




 博客探讨了CPU对象寻址优化,解释了为何对象实例大小通常是8的倍数,以确保寻址效率。同时,详细介绍了CAS分段机制,如LongAdder中的实现,如何通过细胞数组分散并发压力,提高并发性能。当线程增多,同步机制如synchronized会经历从无锁到轻量级锁再到重量级锁的升级过程,以应对多线程竞争。
博客探讨了CPU对象寻址优化,解释了为何对象实例大小通常是8的倍数,以确保寻址效率。同时,详细介绍了CAS分段机制,如LongAdder中的实现,如何通过细胞数组分散并发压力,提高并发性能。当线程增多,同步机制如synchronized会经历从无锁到轻量级锁再到重量级锁的升级过程,以应对多线程竞争。

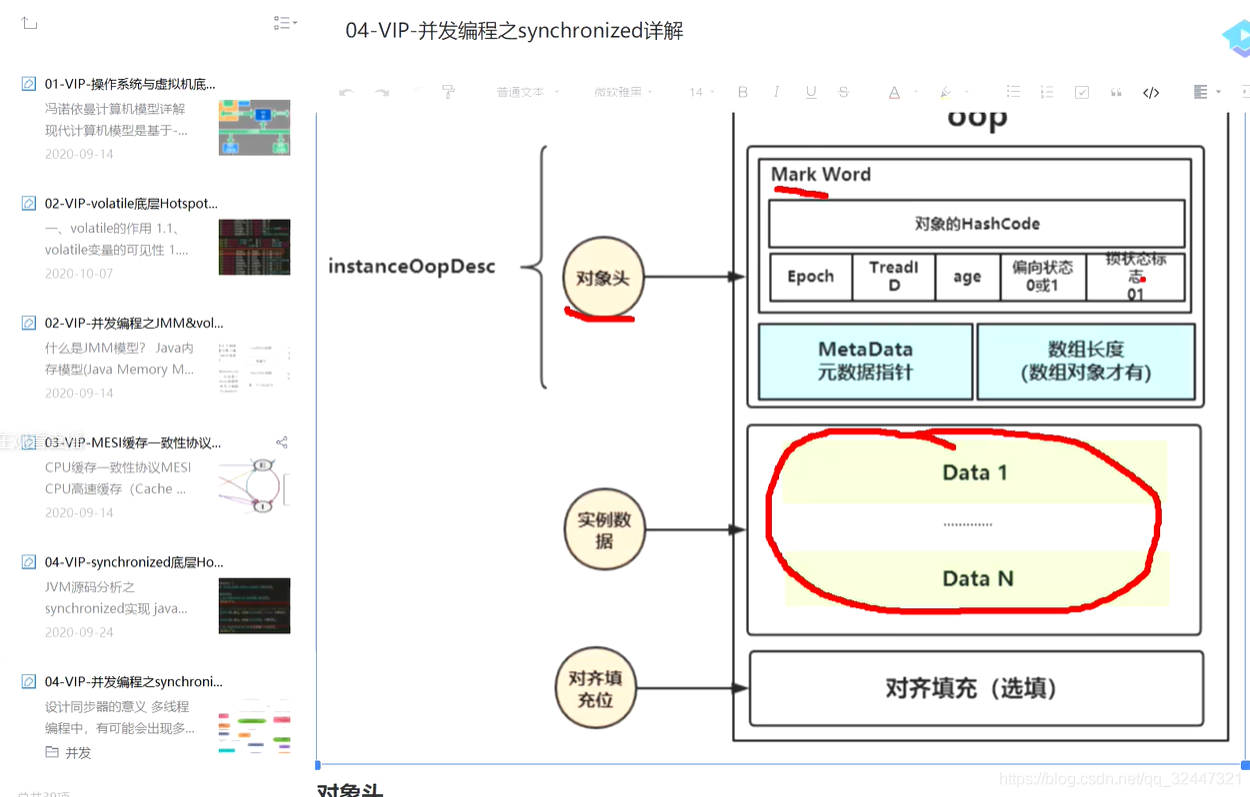
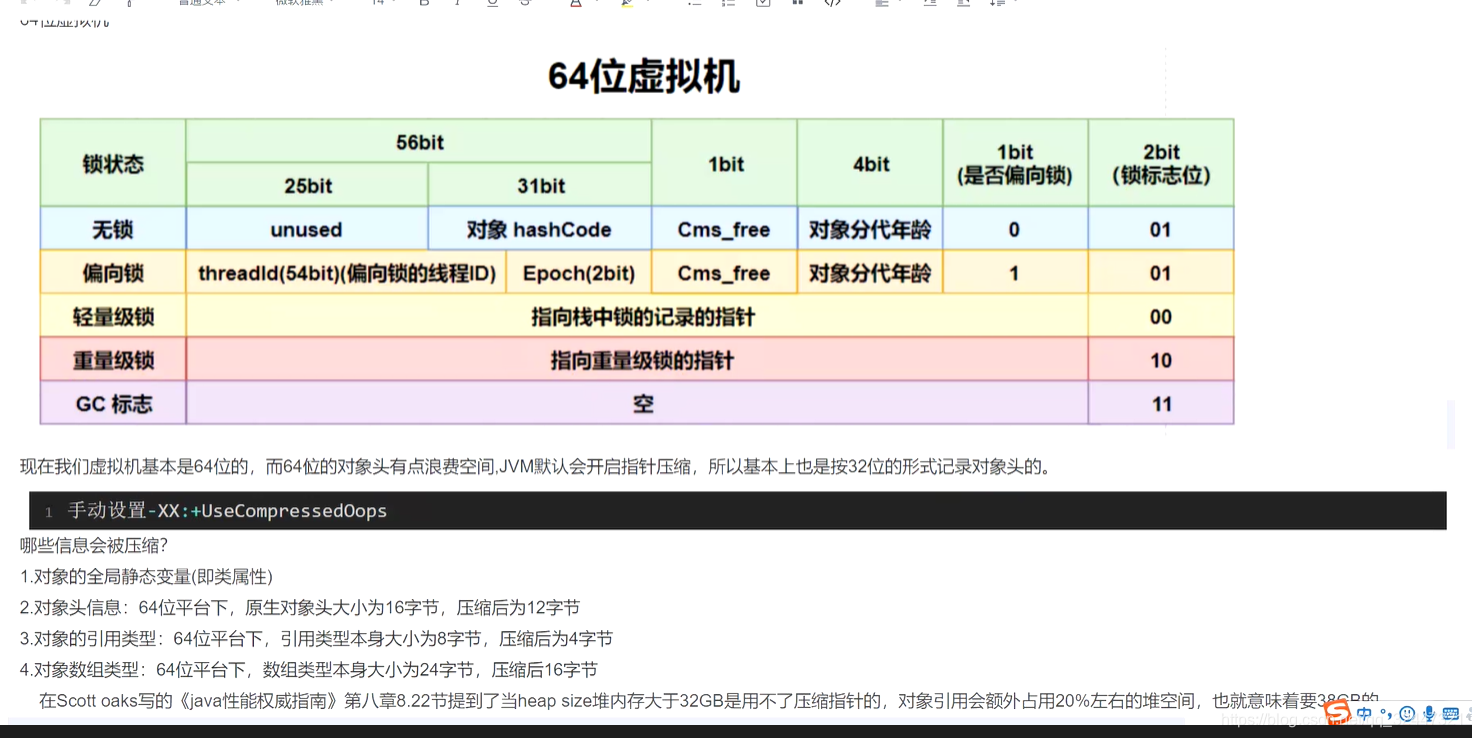
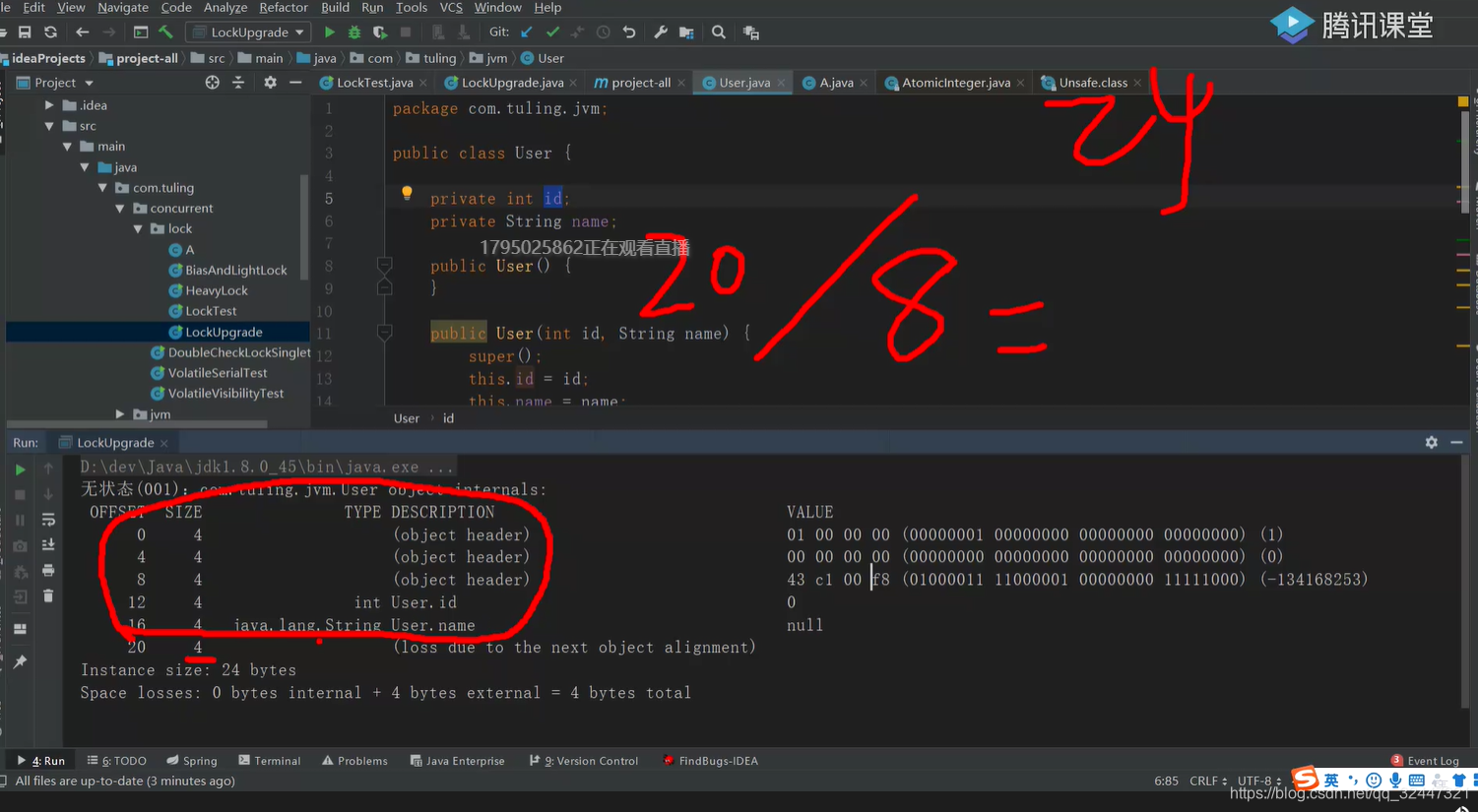
对齐 --》对象寻址效率更高 (20byte 补充external的4byte为了8做整除)为什么是8的倍数,cpu处理经验值
一个对象实例的size(byte)都是8的倍数? 寻址默认被8整除,hashmap默认size 16都是经验值
所谓CAS分段机制,其维护这一个base变量和一个cell数组,当多个线程操作一个变量的时候,先会在这个base变量上进行cas操作,当它发现线程增多的时候,就会使用cell数组。比如当base更新为3的时候发现线程增多(也就是casBase操作失败),那么它会自动使用cell数组,每一个线程对应于一个cell,在每一个线程中对该cell进行cas操作,这样就可以提高并发效率,分散并发压力。在LongAdder中的源码如下:
当线程增多,每个cell中分配的线程数也会增多,当其中一个线程操作失败的时候,它会自动迁移到下一个cell中进行操作,这也就解决了CAS空旋转,自旋不停等待的问题。这就是自动迁移机制。
具体在源码中的体现如下(该段代码在抽象类Striped64下,LongAdder继承自该类)
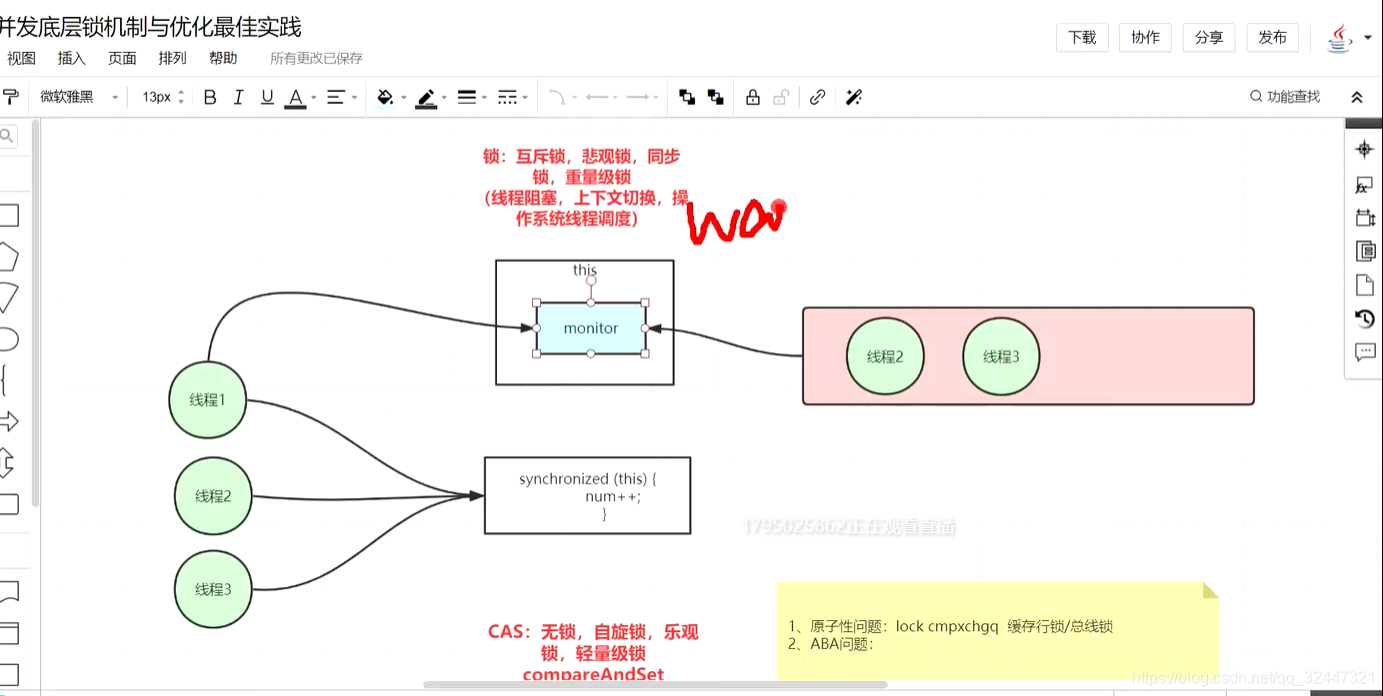
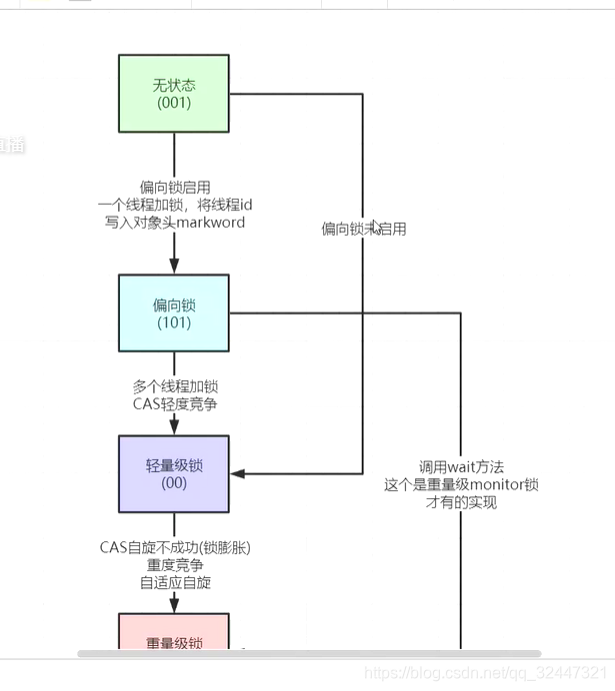
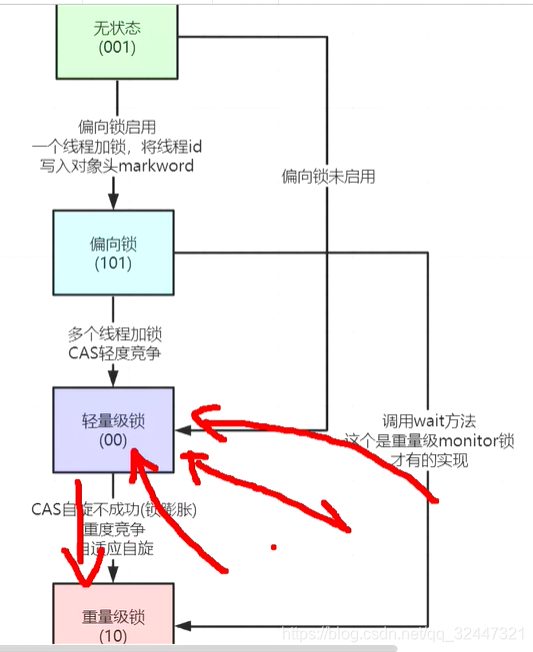
当被synchinzed修饰的,这种锁初始状态是“无状态的”,在多线程并发执行情况下偏向锁会升级轻量级锁(10线程左右),当并发的thread持续增大时 导致锁膨胀从而升级重量级锁
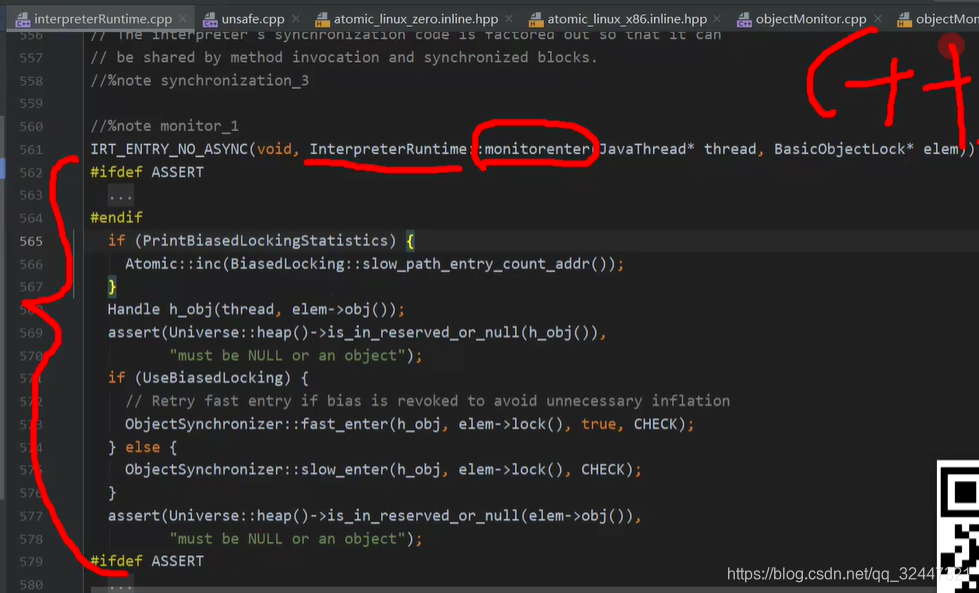
synchronized 对应的C++代码(当线程读取到关键字synchronized时,进行锁升级的判断)

















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









