






图来自刘鹏辉l老师知乎文章(CMU 刘鹏飞:NLP的第四范式 - 知乎 (zhihu.com))
NLP四大范式:
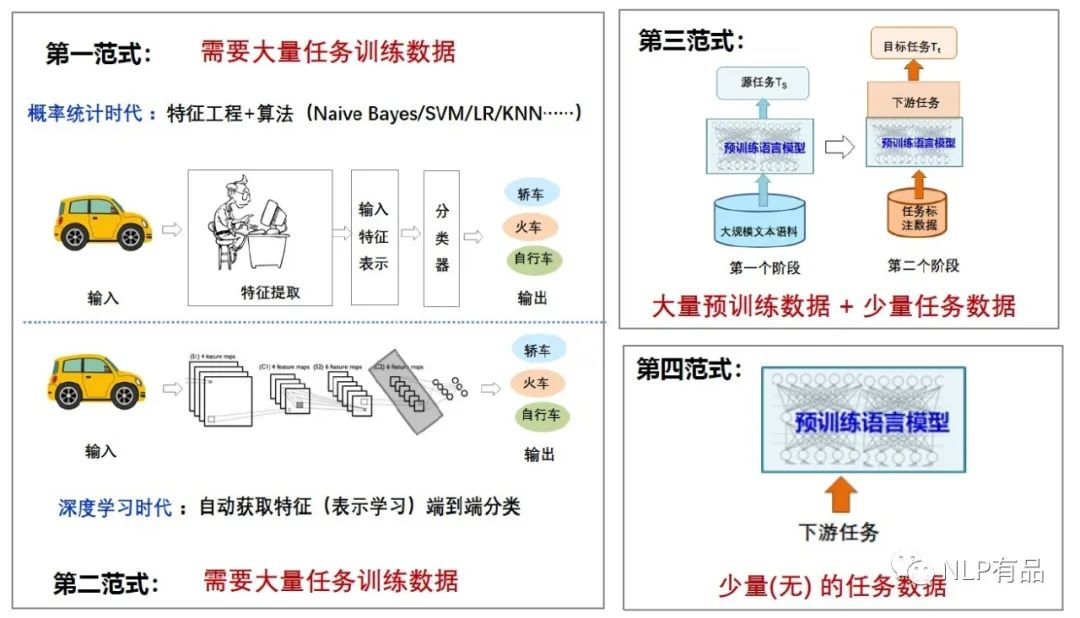
(1)第一范式:非神经网络时代的完全监督学习(特征工程)
第一范式指的是引入神经网络之前NLP领域的处理方法,提取出自然语言语料库中的一些特征,利用特定的规则或数学、统计学的模型来对特征进行匹配和利用,进而完成特定的NLP任务。常见的方法比如贝叶斯、veterbi算法、隐马尔可夫模型等等,来进行序列分类、序列标注等任务。
(2)第二范式:基于神经网络的完全监督学习(架构工程)
第二范式指的是神经网络引进之后,预训练模型出现之前NLP领域的研究方法,这类方法不用手动设置特征和规则,节省了大量的人力资源,但仍然需要人工设计合适的神经网路架构来对数据集进行训练。常见的方法比如CNN、RNN、机器翻译中的Seq2Seq模型等等。
(3)第三范式:预训练,精调范式(目标工程)
第三范式指的是先在大的无监督数据集上进行预训练,学习到一些通用的语法和语义特征,然后利用预训练好的模型在下游任务的特定数据集上进行fine-tuning,使模型更适应下游任务。GPT、Bert、XLNet等模型都属于第三范式,其特点是不需要大量的有监督下游任务数据,模型主要在大型无监督数据上训练,只需要少量下游任务数据来微调少量网络层即可。
(4)第四范式:预训练,提示,预测范式(Prompt工程)
第四范式指在特定下游任务下可以通过引入合适的模版(prompt)去重构下游任务,管控模型的行为,实现few shot甚至zero shot。通过合适的prompt来实现直接在预训练模型上解决下游任务,使下游任务去适应预训练模型,这种模式需要极少量(甚至不需要)下游任务数据,使得小样本、零样本学习成为可能。一个合适的模版甚至可以让模型摆脱对下游特定任务数据的要求,所以如何构建一个合理有效的prompt成为了重中之重。
第三范式的fine-tuning过程是调整预训练模型,使其更加匹配下游任务,那么第四范式就正好相反,prompt过程则是调整下游任务,使其更加匹配预训练模型。也就是第三范式是预训练模型迁就下游任务,而第四范式是下游任务迁就预训练模型。
Prompt learning的定义:
传统的监督学习任务,是去训练一个模型P(y|x),接收x作为输入,去预测y。Prompt learning则不然,它依赖于预训练语言模型P(x),通过引入合适的模版template将输入x调整为完形填空格式的x’,调整后的输入x’里含有某些空槽,利用语言模型P将空槽填充后就可以推断出对应的y。例如对于情感分析任务,传统的做法就是训练一个判别模型,去预测输入x对应的标签是positive或者negative,但是如果是prompt learning,则是利用合适模版,将输入x调整为[x], it is [z]。然后作为语言模型的输入去预测相应z的取值,如果z是positive相关的词,就表示原始输入x是positive,反之就是negative的。
Prompt learning包括三个部分,分别是prompt addition,answer search, answer mapping。
(1)Prompt addition
选择合适的模版,定义函数fprompt(x),可以将原始的输入x转化为x‘,即fprompt(x)=x’。经过该函数转化得到的输入都是带有空槽,槽位上的预测值会直接决定最后的结果。另外,这里的模版不仅仅可以是离散化的token,也可以连续的向量。在不同的下游任务,可以灵活调整,选择合适的模版。
(2)Answer search
通过prompt函数后,将x’输入到语言模型,去预测使得语言模型得分最高的候选槽值。Answer search指的就是从所有可能的候选槽值进行搜索,然后选择合适的槽值填充到对应的空槽里。这里槽值的所有可能结果的集合为Z,对于生成任务而言,Z包括所有的token,但是对于分类任务而言,Z只包含跟特定分类任务相关的一部分token。例如对于之前那个例子而言,Z={positive相关的词语,negative相关的词语}
(3)Answer mapping
当通过answer search得到合适的槽值时,需要根据槽值推断最终的预测结果。这部分比较直接,假如是生成任务,那么填充的槽值就是最终的结果。但如果是分类任务,就需要根据相应的槽值归纳到具体的类中。例如情感分类中,如果把跟positive相关的槽值都归类到positive一类,把跟negative相关的槽值归类到negative一类中。
Prompt learning的分类:
Prompt Learing按照prompt模板构建方式可分为,人工prompt、离散型prompt和连续型prompt。
(1)人工prompt:根据专业经验人工构建多个prompt模板,过程简单直观,效果相对可控,非常适合zero shot等场景,可供快速尝试,但过程耗时耗力。
(2)离散型prompt:通常是先由人工构建,然后可以通过种子prompt去扩充,也可以通过生成方式去获取。在构建得到prompt候选集后,可以在下游任务上评估,也可以通过语言模型去打分。最终可以只选择最合适的一种prompt,也可以集成多个prompt。
(3)连续型prompt:通过梯度去更新优化的。它的效果通常优于离散型prompt,因为它可以进行梯度优化,而离散型prompt由于不可导只能采用近似梯度或其他方式去优化 2。连续型prompt的初始化很重要,一般会采用合理的token进行初始化,这些token可以是手工设计的离散型prompt。
关注NLP有品,多少有些收获不是


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









