







 XL-Net是一种改进的预训练语言模型,由CMU和Google的研究人员提出,旨在解决BERT存在的预训练与微调数据不一致的问题。XL-Net通过采用自回归训练方式,避免了MASK标记,使用双流注意力机制,解决了BERT的AE模型缺陷。同时,XL-Net引入了Transformer-XL,用于处理长文本任务,通过缓存机制保存并利用每个段落的隐藏状态,有效解决了长序列信息丢失问题。
XL-Net是一种改进的预训练语言模型,由CMU和Google的研究人员提出,旨在解决BERT存在的预训练与微调数据不一致的问题。XL-Net通过采用自回归训练方式,避免了MASK标记,使用双流注意力机制,解决了BERT的AE模型缺陷。同时,XL-Net引入了Transformer-XL,用于处理长文本任务,通过缓存机制保存并利用每个段落的隐藏状态,有效解决了长序列信息丢失问题。
XL-Net
论文:《XLNet: Generalized Autoregressive Pretraining for Language Understanding》
论文地址:https://arxiv.org/pdf/1906.08237v1
作者/机构:CMU+google
年份:2019.6
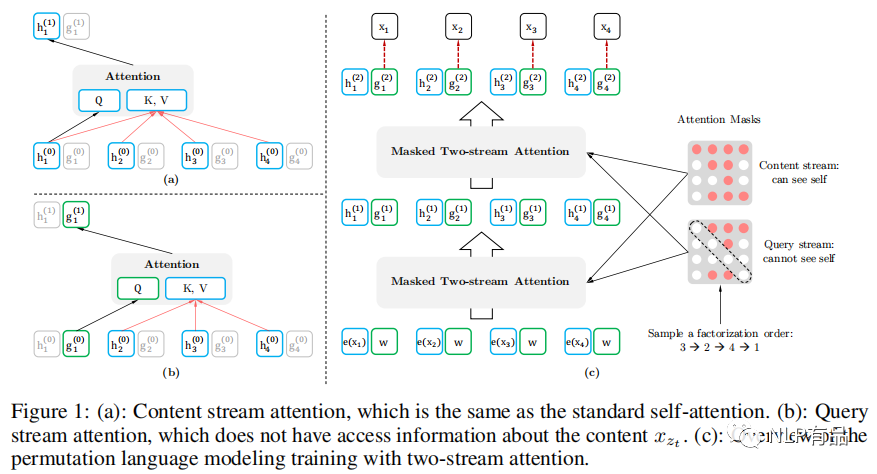
XL-NET主要是通过改变MLM了训练的方式,来提高Bert的性能,提出了自回归(AR,autoregressive)语言模型训练方法,另外还针对长文本任务将transformer替换为transformer-xl来提高微调长文本任务的性能。XL-NET的两个改进点如下:
(1)采用AR模型替代AE模型,解决mask带来的负面影响
Bert预训练过程中,MaskLM使用的是AE(autoencoding)方式,使用mask掉的词的上下文来预测该mask的词,而在微调阶段,输入文本是没有MASK的,这就导致预训练和微调数据的不统一,从而引入了一些人为误差。
而XL-Net使用的是AR方式,避免了采用mask标记位,且保留了序列的上下文信息,使用双流注意力机制实现的,巧妙的改进了bert与传统AR模型的缺点。
这样做的目的是:取消mask标记避免了微调时候输入与预训练输入不一致带来的误差问题。
(2)引入transformer-xl
Bert的编码单元使用的是普通的Transformer,其缺点是输入序列的长度受最大长度限制,对于特别长的序列就会导致丢失一些信息。对于长序列transfo rmer的做法将长序列分为N个段,然后分别独立计算N个段,然后将N个段的结果拼接,并且每一次的计算都没法考虑到每一个段之间的关系。
而transformer-xl就能解决这个问题,其具体做法是:将长序列文本分为多个段序列,在计算完前一段序列后将得到的结果的隐藏层的值进行缓存,下个段序列计算的过程中,把缓存的值拼接起来再进行计算。
这样做的目的是:不但能保留长依赖关系还能加快训练,因为每一个前置片段都保留了下来,不需要再重新计算,在transformer-xl的论文中,经过试验其速度比transformer快了1800倍。
更多NLP相关技术干货,请关注微信关注【NLP有品】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









