




 本文档详细介绍了如何在MyEclipse环境中配置Hadoop插件以连接HDFS,包括所需文件的下载、配置Hadoop环境变量及解决常见错误的方法。
本文档详细介绍了如何在MyEclipse环境中配置Hadoop插件以连接HDFS,包括所需文件的下载、配置Hadoop环境变量及解决常见错误的方法。
myeclipseC12016连接HDFS
- 步骤1 获取hadoop-eclipse-plugin-2.6.0.jar , winutils.exe
- 步骤2 myeclipse中指定 hadoop的位置
- 附上所需的所需的文件
- 链接:https://pan.baidu.com/s/1Tsy2OyvjonHVnI0EjcrxEA 密码:a70p
获取jar包
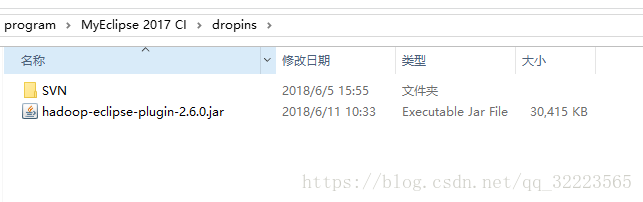
将hadoop-eclipse-plugin-2.6.0.jar置于 myeclipse的plugins下,(后来发现myeclipse Window/preference/ 中未显示 Hadoop Map/Reduce该选项,又将该jar包置于dropins 一份,终于出现该选项了。)
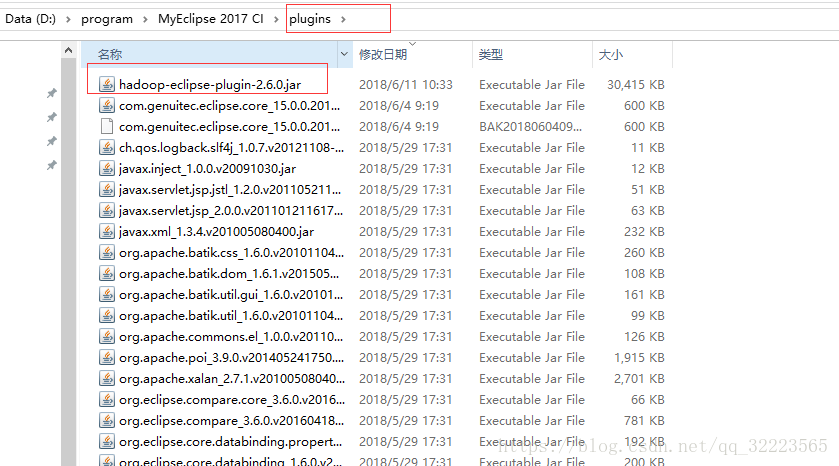
指定Hadoop installation directory的位置。 (即和安装在虚拟机中hadoop版本一致的 本地的hadoop的解压包 …/hadoop/bin),在计算机环境变量中配置 HADOOP_HOME = …./hadoop/bin
下载 hadoop-common-2.2.0-bin-master的文件
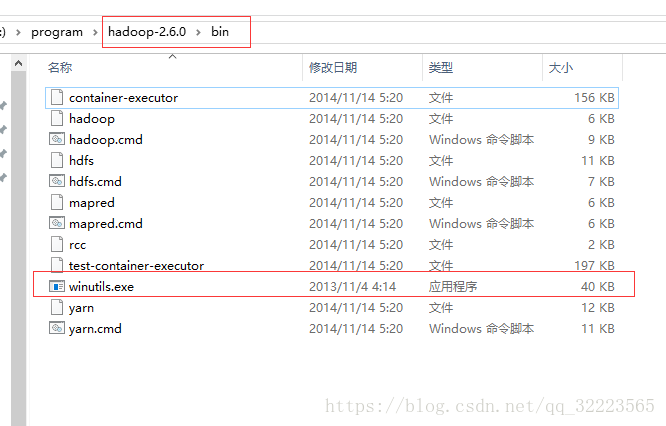
只需要其中的winutils.exe文件,并将该文件置于 …../hadoop/bin/目录下,程序建立连接的时候需要使用,否则会报 Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
- 见图
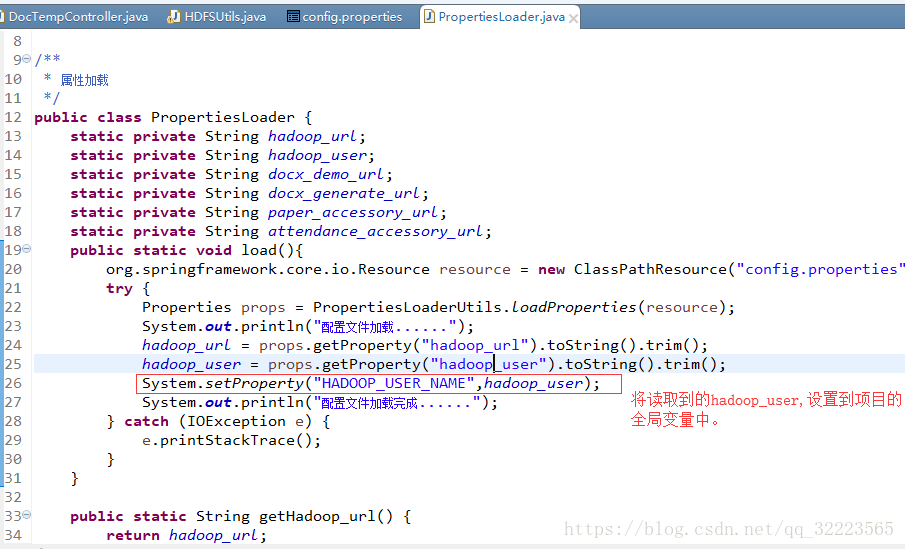
使用FileSystem需要注意一下
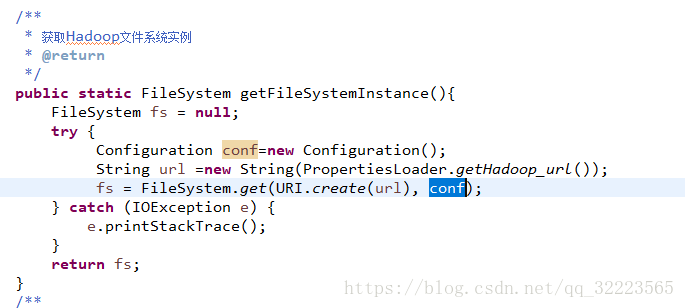
- 列: url = hdfs://192.168.5.169:9000/
系统会先在系统变量中寻找 HADOOP_USER_NAME的值,(即:计算机系统变量中获得) 若未找到,即读取System.getProperty(“HADOOP_USER_NAME”);
将读取的hadoop_user,设置到系统 的全局变量中。
这里设置下
System.setProperty(“HADOOP_USER_NAME”,hadoop_user);
hadoop_user未配置文件中所设

















 9350
9350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









