







 本文介绍了机器学习与深度学习的区别,强调深度学习在特征表示上的自动化。接着探讨了人类语言和词义,指出WordNet的局限性。重点讲解了Word2vec,这是一种通过上下文学习单词分布式表示的模型,用于克服传统one-hot编码的不足。Word2vec利用连续词袋模型和skip-gram方法学习词向量,通过最大化上下文词出现的概率来优化模型。文章还讨论了梯度下降在模型训练中的应用,以及随机梯度下降如何加速学习过程。
本文介绍了机器学习与深度学习的区别,强调深度学习在特征表示上的自动化。接着探讨了人类语言和词义,指出WordNet的局限性。重点讲解了Word2vec,这是一种通过上下文学习单词分布式表示的模型,用于克服传统one-hot编码的不足。Word2vec利用连续词袋模型和skip-gram方法学习词向量,通过最大化上下文词出现的概率来优化模型。文章还讨论了梯度下降在模型训练中的应用,以及随机梯度下降如何加速学习过程。
机器学习与深度学习介绍
深度学习是机器学习的一个分支。
传统机器学习都是围绕着决策树、逻辑回归、朴素贝叶斯、支持向量机(SVM)等概念,由人类审视一个特定的问题,找出解决问题的关键要素,设计出与该问题相关的重要特征要素,然后手写代码。人们根据确定的要求会不断加入新的特征,最终系统会有数百万个人工设定的特征。人类去研究如何描述数据,总结出重要特征,只有10%的工作是电脑进行这一数值优化算法。
深度学习是表征学习的一个分支,表征学习的理念是,我们可以只向电脑提供来自世界的原始信号(视觉、语言、其他),然后电脑可以得出好的中介表征来很好的完成任务,即让计算机自己定义特征,和机器学习通过人类来定义特征是一样的。DL将学到多层的学习表征。
简而言之,ML是人类尽可能指定所有可能的特征,DL是自己去定义特征硬练。
人类语言和词义
人们通过语言进行知识传播,我们拥有人类计算机网络,我们使用人类语言作为我们的网络语言以实现人类计算机网络。
- 我们使用wordnet在计算机中拥有可用的意思(一个包含同义词集和超常词列表的同义词典)
e.g. good的同义词集合
import nltk
from nltk.corpus import wordnet as wn
nltk.download('wordnet')
poses = { 'n':'noun', 'v':'verb', 's':'adj (s)', 'a':'adj', 'r':'adv'}
for synset in wn.synsets("good"):
print("{}: {}".format(poses[synset.pos()], ", ".join([l.name() for l in synset.lemmas()])))
noun: good
noun: good, goodness
noun: good, goodness
noun: commodity, trade_good, good
adj: good
adj (s): full, good
adj: good
adj (s): estimable, good, honorable, respectable
adj (s): beneficial, good
adj (s): good
……
adv: well, good
adv: thoroughly, soundly, good
- 类似于WordNet的资源会存在这些问题:
- 作为一个资源很好,但缺少细微差别
如:“proficient”被列为“good”的同义词。但是这仅仅在某些语境下是成立的。 - 缺少单词的新含义
如:wicked, badass, nifty, wizard, genius, ninja, bombest - 不能与时俱进
- 主观性
- 需要人为来创造和适应
- 无法计算准确的单词相似性
- 作为一个资源很好,但缺少细微差别
- 使用one-hot向量来表示单词
在传统的自然语言处理中,我们把词语看作离散的符号
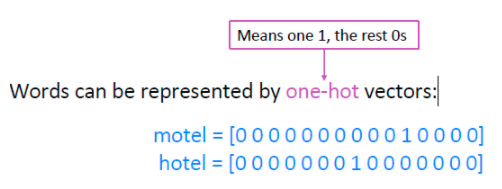
这也会存在一些问题,比如我们搜索Seattle motel,我们同时还会得到Seattle hotel,hotel和motel几乎上是同一个东西;如果我们使用one-hot向量,那么这两个词是正交的没有相似关系。 - 解决方案
我们引入分布语义学,我们通过观察上下文来表示单词的含义。
比如:我们要知道bank的意思,抓取了很多文本,获取使用bank的上下文,这样可以很好的抓取该单词的意义
Word2vec
-
Word2vec是具有分布式的单词表示形式。我们把词的含义作为一个神经词向量,这样我们可以实现意义的可视化。
下图展示了一个词对应的向量以及投影到二维空间的表示:
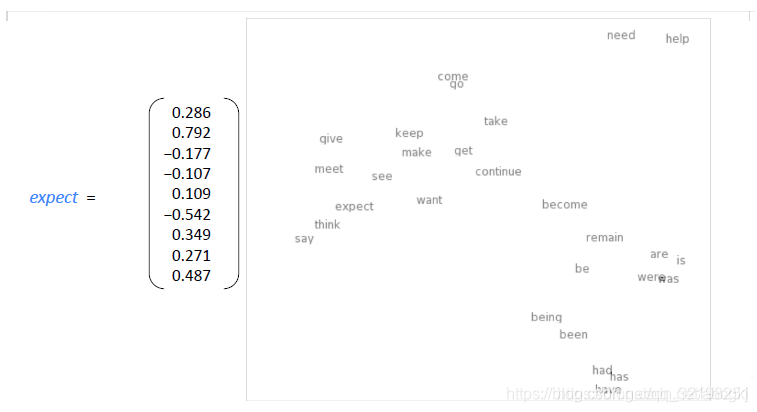
-
过程详解
Word2vec是一种从原始文本中学习嵌入词的高效预测模型。它有两种方法:连续的词袋模型(CBOW)和跳格模型(skip-gram)。从算法上来说,这些模型是相似的,CBOW从源上下文词预测目标词,而skip-gram则相反,从目标词预测源上下文词。
这里理解课程推导的内容使用了skip-gram方法就更好理解了。
每个词我们都由一个向量表示,其中我们定义文本当中当前词的位置序列是t(target),中心词是c(center),上下文词是o(outside)。用向量c和o的相似度(比如说余弦相似度)来计算给定c到o的概率。我们期待的情况是,这个概率可以达到最大化。
对于每个位置t= 1,…,T,预测一个固定大小为m的窗口、中心词为 w t w_t wt,预测context words:
L i k e h o o d = L ( θ ) = ∏ t = 1 T ∏ − m ≤ j ≤ m , j ≠ 1 P ( ω t + j ∣ ω t , θ ) Likehood=L(\theta)=\prod_{t=1}^T \prod_{-m≤j≤m,j≠1} P(\omega_{t+j}|\omega_t,\theta) Likehood=L(θ)=t=1∏T−m≤j≤m,j=1∏P(ωt+j∣ωt,θ)
objective function是likehood的平均负log(average negative log likehood),我们想要得到目标函数的最小值:
o b j e c t i v e f u n c t i o n = J ( θ ) = − 1 T l o g L ( θ ) objective function=J(\theta)=-\frac{1}{T}logL(\theta) objectivefunction=J(θ)=−T1logL(θ) = − 1 T ∑ t = 1 T ∑ − m ≤ j ≤ m , j ≠ 1 P ( ω t + j ∣ ω t , θ ) =-\frac{1}{T}\sum_{t=1}^T\sum_{-m≤j≤m,j≠1} P(\omega_{t+j}|\omega_t,\theta) =−T1t=1∑T−m≤j≤m,j=1∑P(ωt+j∣ωt,θ)
其中,objective function有时也被称作loss function或者cost function; θ \theta θ是是所有要被优化的变量;目标函数是对似然函数进行log,这样累乘可以变成累加,前面又加了一个负号,又乘1/T进行平均,由最大值改为求最小值。
根据上面的算式推到,我们的目标是通过训练模型,也就是改变参数θ的值,来最小化 J ( θ ) J(\theta) J(θ),也就是为了求得P的最小值,对于每个单词w,我们将使用两个向量:- v w v_w vw:当w是中心词的时候, v w v_w vw代表中心词向量,维度设为d维(本课程中设为100维特征,现google最新已为300维),故对于中心词c,对应的词向量为 v c v_c vc
- u w u_w uw :当w是上下文词的时, u w u_w uw代表上文词向量,维度设为d维,故对于上下文词o,对应的词向量为 u o u_o uo
- 一共用V个词汇
我们要求 P ( ω t + j ∣ ω t ) P(\omega_{t+j}|\omega_t) P(ωt+j∣ωt)的最小值,相当于计算对于中心词c和上下文词o时的概率,即:
P ( o ∣ c ) = e x p ( u o T v c ) ∑ w ∈ V e x p ( u w T v c ) P(o|c)=\frac{exp(u_o^Tv_c)}{\sum_{w\in V}exp(u_w^Tv_c)} P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc)
两个单词越相似,点积结果越大。(A·B=|A||B|cos θ \theta θ)
这里计算logP对 v c v_c vc的偏导数,用向量表示所有的参数,有V个单词,d维向量。每个单词有2个向量。参数个数一共是2dV个。
∂ ∂ v c l o g P ( o ∣ c ) = ∂ ∂ v c l o g e x p ( u o T ⋅ v c ) ∑ w = 1 V e x p ( u w T ⋅ v c ) = ∂ ∂ v c l o g e x p ( u o T ⋅ v c ) ⏟ 1 − ∂ ∂ v c l o g ∑ w = 1 V e x p ( u w T ⋅ v c ) ⏟ 2 \frac{\partial}{\partial v_c}logP(o|c)=\frac{\partial}{\partial v_c}log\frac{exp(u_o^T\cdot v_c)}{\sum_{w=1}^{V}exp(u_w^T\cdot v_c)}=\underbrace{\frac{\partial}{\partial v_c}logexp(u_o^T\cdot v_c)}_{1}-\underbrace{\frac{\partial}{\partial v_c}log\sum_{w=1}^{V}exp(u_w^T·v_c)}_{2} ∂vc∂logP(o∣c)=∂vc∂log∑w=1Vexp(uwT⋅vc)exp(uoT⋅vc)=1 ∂vc∂logexp(uoT⋅vc)−2 ∂vc∂logw=1∑Vexp(uwT⋅vc)
式子1我们可以得到其倒数为 u o u_o uo;
式子2的推导过程如下:
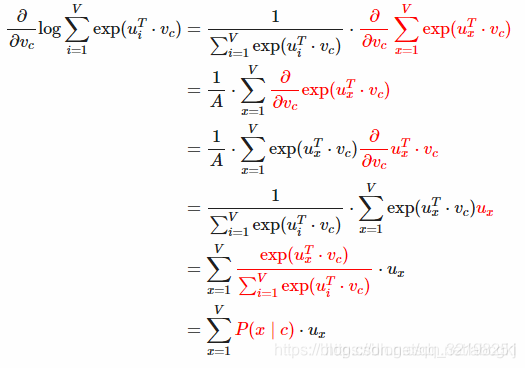
注:公式中的x为避免和前面的i重复。
所以,综合起来可以求得,单词o是单词c的上下文概率
logP(o∣c),对center向量 v c v_c vc
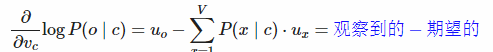
实际上偏导是,单词o的上下文词向量,减去,所有单词x的上下文向量乘以x作为c的上下文向量的概率。
-
总体梯度计算:
在一个window里面,对中间词汇 v c v_c vc
求了梯度, 然后再对各个上下文词汇 u o u_o uo
求梯度(本文中没有写,感兴趣可自行计算)。然后更新这个window里面用到的参数。
通常在每个窗口中,我们将计算该窗口中使用的所有参数的更新。例如:
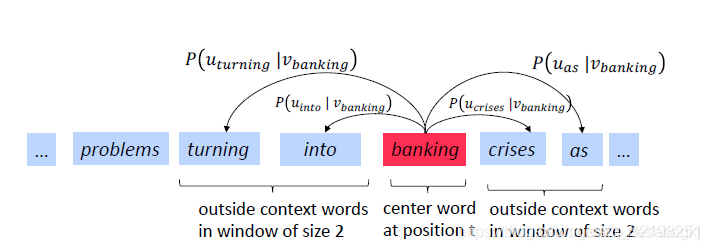
-
梯度下降
有了梯度之后,参数减去梯度,就可以朝着最小的方向走了。机器学习梯度下降
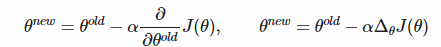
-优化梯度
-
方法
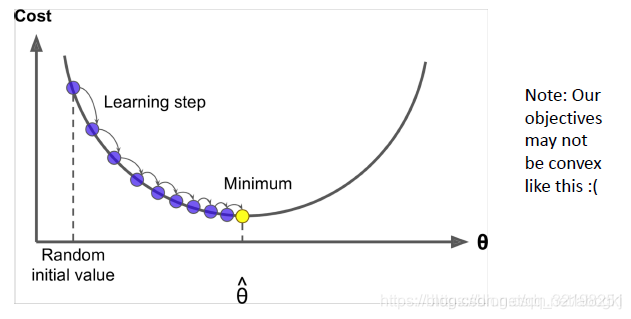
我们最小化目标函数:J ( θ ) J(\theta)J(θ)
梯度下降是一种最小化J ( θ ) J(\theta)J(θ)的算法
思想:对于当前θ值,计算J ( θ ) J(\theta)J(θ)的值,然后在负梯度的方向上迈步
-
具体细节
更新方程(以矩阵表示)
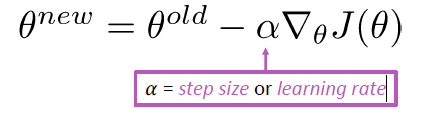
更新方程(对于单个参数)
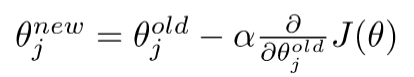
算法:

-
随机梯度下降
问题:J ( θ ) J(\theta)J(θ)是语料库中所有窗口的函数(数以亿计),所以计算J(θ)的梯度非常耗费资源,您需要等待很长时间才能进行一次更新,对于几乎所有的神经网络来说,这是一个非常糟糕的方法。
解决方法:随机梯度下降(Stochastic gradient descent,SGD),即重复示例窗口,并在每个窗口之后更新
随机梯度下降算法:


















 3933
3933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









