







 本文介绍了蚂蚁集团自研的移动端OCR技术xNN-OCR,该技术利用深度学习和端侧推理引擎,在移动端实现快速、准确的文字识别。文章详细阐述了xNN-OCR的技术演进,包括数据生成、网络架构优化、模型压缩等方面,并分享了在支付宝中的应用和能力开放情况,为开发者提供了接入和体验的途径。
本文介绍了蚂蚁集团自研的移动端OCR技术xNN-OCR,该技术利用深度学习和端侧推理引擎,在移动端实现快速、准确的文字识别。文章详细阐述了xNN-OCR的技术演进,包括数据生成、网络架构优化、模型压缩等方面,并分享了在支付宝中的应用和能力开放情况,为开发者提供了接入和体验的途径。

作者:张伟辰(璟铭)
随着手机性能的不断提升,在手机端进行复杂的AI计算已经成为各大厂商的核心发展方向,在此之上产生了大量的端智能应用。这种端侧AI计算的模式,使得大量牵涉时效性、成本和隐私考虑的场景实现变成了可能。在这里,我们以广泛使用的文字识别技术(OCR)为例,介绍一下蚂蚁自研移动端OCR技术(xNN-OCR)。
背景介绍
文字识别技术是计算机视觉领域中历史悠久、应用广泛的一个研究方向,特别是随着深度学习技术的发展,其能力空间不断扩大。相比云端计算方式,移动端OCR算法可在离线情况下完成图片中文字提取,对于实时性、隐私保护和成本要求高的场景,有着很大的应用价值。另一方面,基于深度学习的OCR模型越来越复杂,通常具有几十M的参数量以及几百GFlops的计算量,如何在手机有限的计算资源下,完成OCR模型运行是一个极具挑战的任务。在支付宝中,我们结合自研的端侧推理引擎xNN和应用算法的深度优化,研发了又小、又快、又准的xNN-OCR技术产品,从2018年上线到银行卡号识别场景开始,陆续支撑了数十个核心业务的技术升级。本文我们将给大家完整的展开xNN-OCR的技术演进和能力开放情况。
xNN-OCR技术演进
一个端侧模型研发需要经历下面的几个流程:训练数据获取和标注、网络结构设计、训练调参、端侧移植和端侧部署,各个环节相互关联也相互影响。在基础算法方面,xNN-OCR经历了小字库、大字库到基于异构计算的三个模型研发阶段。我们将从核心的数据、网络设计和模型压缩层面分别介绍最新成果。
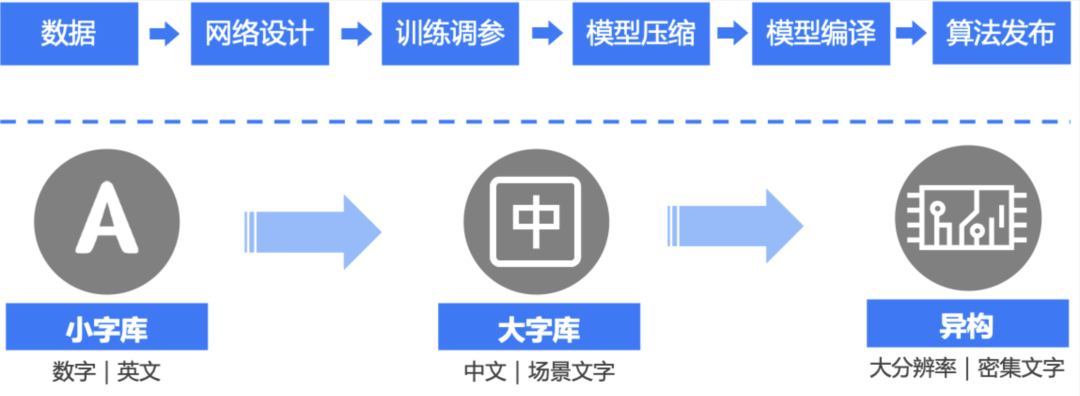
数据生成
数据像弹药
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









