







 本文深入介绍Apache Flink,一款强大的分布式流处理引擎,适用于无界和有界数据流处理。文章涵盖Flink的核心概念,如流处理、批处理、状态管理和事件时间支持,以及Flink的分层API,包括ProcessFunction、DataStreamAPI和SQL & TableAPI。此外,还探讨了Flink在多种资源管理框架上的部署和大规模应用的能力。
本文深入介绍Apache Flink,一款强大的分布式流处理引擎,适用于无界和有界数据流处理。文章涵盖Flink的核心概念,如流处理、批处理、状态管理和事件时间支持,以及Flink的分层API,包括ProcessFunction、DataStreamAPI和SQL & TableAPI。此外,还探讨了Flink在多种资源管理框架上的部署和大规模应用的能力。
Flink概述
Apache Flink® — Stateful Computations over Data Streams

基于数据流的有状态的计算。
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。
Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
处理无界和有界数据
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理。
- 无界流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
- 有界流 有定义流的开始,也有定义流的结束(有始有终)。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理

Apache Flink 擅长处理无界和有界数据集(对应的流处理和批处理)。精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
流
显而易见,(数据)流是流处理的基本要素。然而,流也拥有着多种特征。这些特征决定了流如何以及何时被处理。Flink 是一个能够处理任何类型数据流的强大处理框架。
- 有界 和 无界 的数据流:流可以是无界的;也可以是有界的,例如固定大小的数据集。Flink 在无界的数据流处理上拥有诸多功能强大的特性,同时也针对有界的数据流开发了专用的高效算子。
- 实时 和 历史记录 的数据流:所有的数据都是以流的方式产生,但用户通常会使用两种截然不同的方法处理数据。或是在数据生成时进行实时的处理;亦或是先将数据流持久化到存储系统中——例如文件系统或对象存储,然后再进行批处理。Flink 的应用能够同时支持处理实时以及历史记录数据流。
Flink Layer(分层 API)
Flink 根据抽象程度分层,提供了三种不同的 API。每一种 API 在简洁性和表达力上有着不同的侧重,并且针对不同的应用场景。
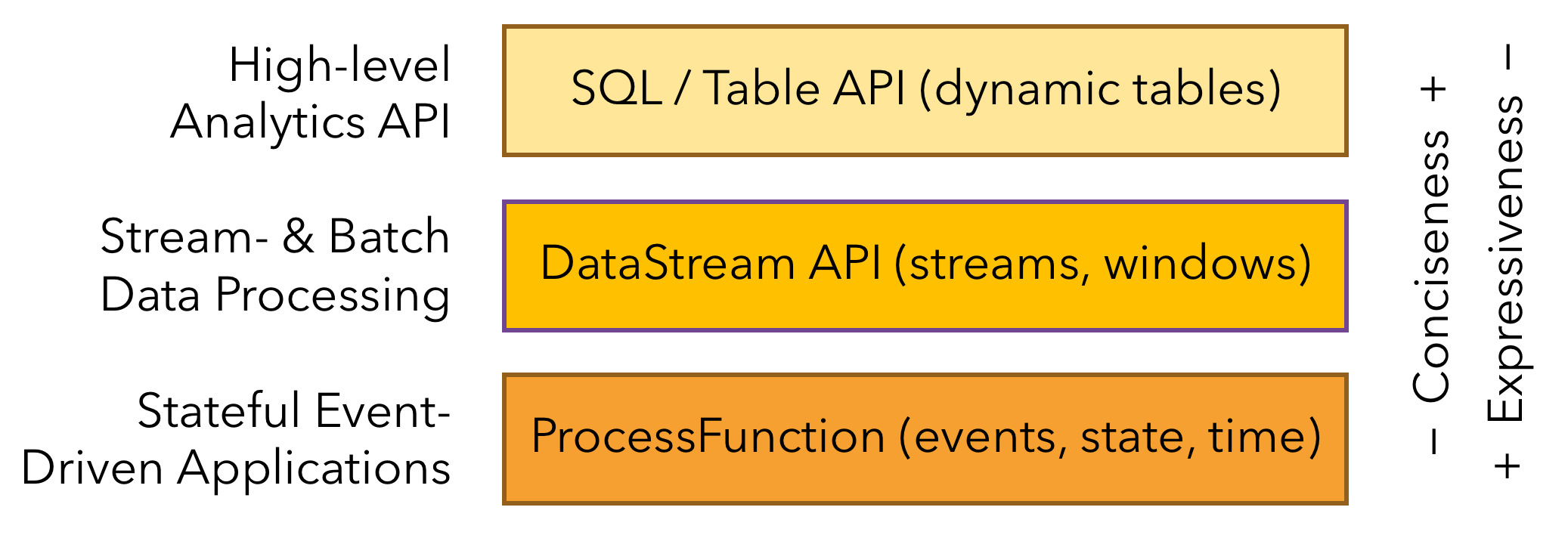
下文中,我们将简要描述每一种 API 及其应用,并提供相关的代码示例。
ProcessFunction
ProcessFunction 是 Flink 所提供的最具表达力的接口。ProcessFunction 可以处理一或两条输入数据流中的单个事件或者归入一个特定窗口内的多个事件。它提供了对于时间和状态的细粒度控制。开发者可以在其中任意地修改状态,也能够注册定时器用以在未来的某一时刻触发回调函数。因此,你可以利用 ProcessFunction 实现许多有状态的事件驱动应用所需要的基于单个事件的复杂业务逻辑。
下面的代码示例展示了如何在 KeyedStream 上利用 KeyedProcessFunction 对标记为 START 和 END 的事件进行处理。当收到 START 事件时,处理函数会记录其时间戳,并且注册一个时长4小时的计时器。如果在计时器结束之前收到 END 事件,处理函数会计算其与上一个 START 事件的时间间隔,清空状态并将计算结果返回。否则,计时器结束,并清空状态。
/**
* 将相邻的 keyed START 和 END 事件相匹配并计算两者的时间间隔
* 输入数据为 Tuple2<String, String> 类型,第一个字段为 key 值,
* 第二个字段标记 START 和 END 事件。
*/
public static class StartEndDuration
extends KeyedProcessFunction<String, Tuple2<String, String>, Tuple2<String, Long>> {
private ValueState<Long> startTime;
@Override
public void open(Configuration conf) {
// obtain state handle
startTime = getRuntimeContext()
.getState(new ValueStateDescriptor<Long>("startTime", Long.class));
}
/** Called for each processed event. */
@Override
public void processElement(
Tuple2<String, String> in,
Context ctx,
Collector<Tuple2<String, Long>> out) throws Exception {
switch (in.f1) {
case "START":
// set the start time if we receive a start event.
startTime.update(ctx.timestamp());
// register a timer in four hours from the start event.
ctx.timerService()
.registerEventTimeTimer(ctx.timestamp() + 4 * 60 * 60 * 1000);
break;
case "END":
// emit the duration between start and end event
Long sTime = startTime.value();
if (sTime != null) {
out.collect(Tuple2.of(in.f0, ctx.timestamp() - sTime));
// clear the state
startTime.clear();
}
default:
// do nothing
}
}
/** Called when a timer fires. */
@Override
public void onTimer(
long timestamp,
OnTimerContext ctx,
Collector<Tuple2<String, Long>> out) {
// Timeout interval exceeded. Cleaning up the state.
startTime.clear();
}
}
这个例子充分展现了 KeyedProcessFunction 强大的表达力,也因此是一个实现相当复杂的接口。
DataStream API
DataStream API 为许多通用的流处理操作提供了处理原语。这些操作包括窗口、逐条记录的转换操作,在处理事件时进行外部数据库查询等。DataStream API 支持 Java 和 Scala 语言,预先定义了例如map()、reduce()、aggregate() 等函数。你可以通过扩展实现预定义接口或使用 Java、Scala 的 lambda 表达式实现自定义的函数。
下面的代码示例展示了如何捕获会话时间范围内所有的点击流事件,并对每一次会话的点击量进行计数。
// 网站点击 Click 的数据流
DataStream<Click> clicks = ...
DataStream<Tuple2<String, Long>> result = clicks
// 将网站点击映射为 (userId, 1) 以便计数
.map(
// 实现 MapFunction 接口定义函数
new MapFunction<Click, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Click click) {
return Tuple2.of(click.userId, 1L);
}
})
// 以 userId (field 0) 作为 key
.keyBy(0)
// 定义 30 分钟超时的会话窗口
.window(EventTimeSessionWindows.withGap(Time.minutes(30L)))
// 对每个会话窗口的点击进行计数,使用 lambda 表达式定义 reduce 函数
.reduce((a, b) -> Tuple2.of(a.f0, a.f1 + b.f1));
SQL & Table API
Flink 支持两种关系型的 API,Table API 和 SQL。这两个 API 都是批处理和流处理统一的 API,这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型 API 会以相同的语义执行查询,并产生相同的结果。Table API 和 SQL 借助了 Apache Calcite 来进行查询的解析,校验以及优化。它们可以与 DataStream 和 DataSet API 无缝集成,并支持用户自定义的标量函数,聚合函数以及表值函数。
Flink 的关系型 API 旨在简化数据分析、数据流水线和 ETL 应用的定义。
下面的代码示例展示了如何使用 SQL 语句查询捕获会话时间范围内所有的点击流事件,并对每一次会话的点击量进行计数。此示例与上述 DataStream API 中的示例有着相同的逻辑。
SELECT userId, COUNT(*)
FROM clicks
GROUP BY SESSION(clicktime, INTERVAL '30' MINUTE), userId
Flink应用程序运行方式多样化
部署应用到任意地方
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为独立集群运行。
Flink 被设计为能够很好地工作在上述每个资源管理器中,这是通过资源管理器特定(resource-manager-specific)的部署模式实现的。Flink 可以采用与当前资源管理器相适应的方式进行交互。
部署 Flink 应用程序时,Flink 会根据应用程序配置的并行性自动标识所需的资源,并从资源管理器请求这些资源。在发生故障的情况下,Flink 通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都是通过 REST 调用进行的,这可以简化 Flink 与各种环境中的集成。
运行任意规模应用
Flink 旨在任意规模上运行有状态流式应用。因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。而且 Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
Flink VS Storm VS Spark Streaming(业界流处理框架对比)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mHzQ5mvK-1598358014712)(…/images/image-20200630113437639.png)]
- Spark
- Streaming
- 结构化流
- 批处理为主,流式处理是批处理的一个特例(mini batch)
- eg. 每个十秒钟处理一次数据
- Flink
- 流式为主,批处理是流式处理的一个特例
- Storm
- 流式
- Tuple
Flink应用场景
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多要求严苛的流处理应用都运行在 Flink 之上。
如何学习Flink
-
官网
-
源码
-
maven 把源码关联上
-
example
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









