






一、概述
hdfs小文件,一说128MB一下,或者更有实际意义的事40、30MB一下的文件,小文件产生的影响也很明确,主要是对namenode的文件管理产生较大负担(文件的元数据管理),治理小文件是个长期的工作,包括对已经产生的小文件合并、为了小文件生成的优化(里面涉及到sql的优化,源文件的加工处理等等),本文主要根据在数栈–安徽国网客户的小文件处理(此环境还未上小文件治理功能,是手动处理干预的),进行初步的讨论
二、小文件治理
1、发现小文件
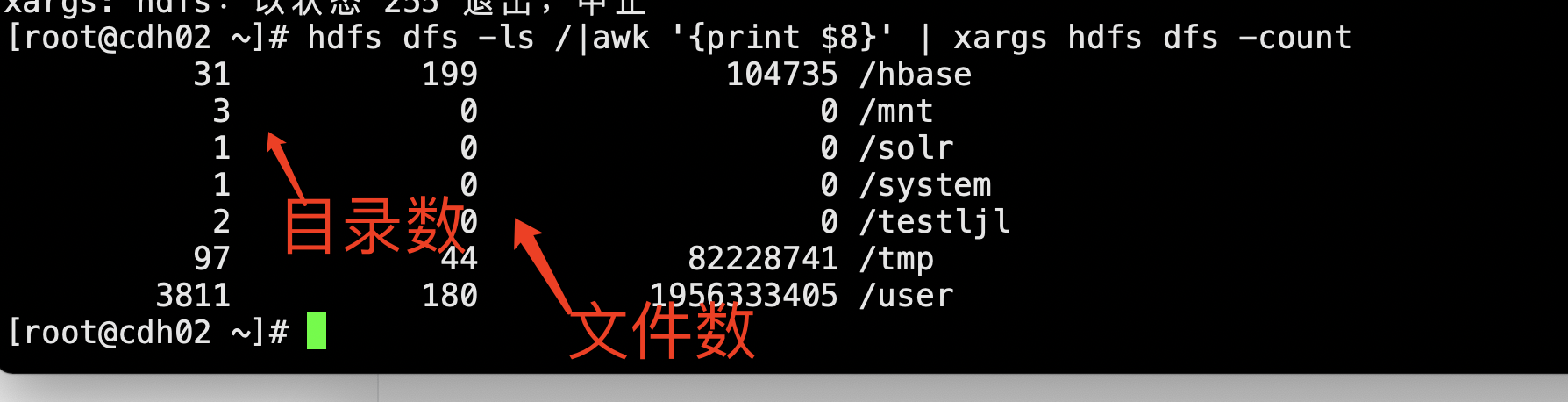
运行这个命令,找到目录(数据库)中文件多的目录(表)
hdfs dfs -ls /dtInsight/hive/warehouse/ah_dsap.db |awk '{print $8}' | xargs hdfs dfs -count >/tmp/ah_dsap.csv
注:
下面这样可以直接输出根据第二列排序的结果
hdfs dfs -ls /dtInsight/hive/warehouse/ah_dsap.db |awk '{print $8}' | xargs hdfs dfs -count | sort -n -k 2
2、SQL优化
这里只是真的spark sql的基本优化
a、场景:
发现客户这些表都不大(几M甚至KB级别),但是每个分区下却有几百到几千个小文件
b、调整参数:spark sql任务中调整shuffle参数
spark.sql.shuffle.partitions=10 #默认是200,这里调整为10,根据情况文件较小的话可以调整到5或者更小,调整后要关注下任务运行速度(可能会变慢)
c、调整后观察:参数调整后可以补数据重新生成一个分区看看,一个是看看运行速度,一个是看看新分区中的文件个数(是否大大减少),安徽国网客户这边一个任务参数调整为10,补数据发现文件数量从几千降低到100个左右
d、进一步动作
由于历史分区都是小文件较多,且上有表对应的数据都存在(这个要核实清楚,否则重跑会影响数据),可以进行不数据来刷新历史分区
三、至于限制产生文件大小、生产文件自动合并等参数测试、、、、未完待续


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









