







 本文介绍了中文分词的基本概念和分类,重点讲述了基于字符串匹配和统计方法的分词策略,如正向最大匹配法、逆向最大匹配法以及概率语言模型,包括一元模型、N元模型、马尔可夫模型和隐马尔可夫模型(HMM)。此外,还提供了中文分词的代码实践,涉及模型训练和维特比算法的实现。
本文介绍了中文分词的基本概念和分类,重点讲述了基于字符串匹配和统计方法的分词策略,如正向最大匹配法、逆向最大匹配法以及概率语言模型,包括一元模型、N元模型、马尔可夫模型和隐马尔可夫模型(HMM)。此外,还提供了中文分词的代码实践,涉及模型训练和维特比算法的实现。
1 简介和分类
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法(本文主要讲述该方法)
1.1基于字符串匹配的分词方法:
这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)
1)正向最大匹配法(由左到右的方向)
2)逆向最大匹配法(由右到左的方向):
3)最少切分(使每一句中切出的词数最小)
4)双向最大匹配法(进行由左到右、由右到左两次扫描)
1.2基于理解的分词方法:
这种分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
1.3基于统计的分词方法:
给出大量已经分词的文本,利用统计机器学习模型学习词语切分的规律(称为训练),从而实现对未知文本的切分。例如最大概率分词方法和最大熵分词方法等。 随着大规模语料库的建立,统计机器学习方法的研究和发展,基于统计的中文分词方法渐渐成为了主流方法。
主要统计模型:N元文法模型(N-gram),隐马尔可夫模型(Hidden Markov Model ,HMM),最大熵模型(ME),条件随机场模型(Conditional Random Fields,CRF)等
2 正向最大匹配法和逆向最大匹配法
使用trie树建立词典,进行正向和反向查找
例如:大学生活动中心
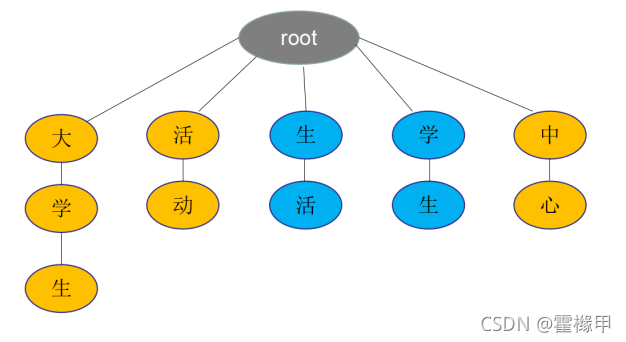
正向最大匹配法:根据中文句子,从左到右去trie树匹配查找长度最大的词语。
如上图,大学生/活动/中心,先匹配出“大学生”,然后“活动”,最后“中心”
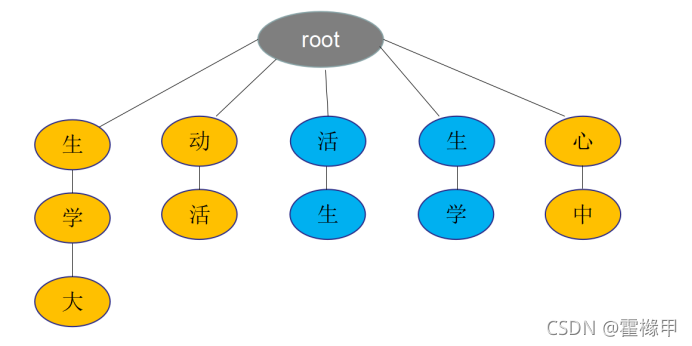
逆向最大匹配法:根据中文句子,从右(句子末尾)到左去trie树匹配查找长度最大的词语。
如上图,大学生/活动/中心,先匹配出“心中”,然后“动活”,最后“生学大”
3 基于统计分词介绍
3.1 概率语言模型
假设要分出来的词在语料库和词表中都存在,则最简单的切方法是按词计算概率,而不是按字计算概率(没有意义)。
分词问题,可以看作:输入一个字串C=c1,c2,c3...cn,输出一个词串S=w1,w2,w3...wm,m<=n,即分出的单词数m<=原来字串的长度。对于一个特定的字串C都有多种切分方案S,分词的目标就是找出最有可能出现的S方案,即使得P(S|C)概率最大,P(S|C)就是由字符串C切分出S方案的概率,也就是对输入字符串切分出最有可能的词序列。
例如,对于输入字符串“南京市长江大桥”,有下面2中切分方案S:
S1: 南京市/长江/大桥
S2: 南京/市长/江大桥
计算条件概率P(S1|C),P(S2|C),选择出概率较大的作为切分方案。
P(C)表示字串C在语料库中出现的概率。比如语料库中有1万的句子,“南京市长江大桥”在该语料库中出现了1次,则P(C)=P(南京市长江大桥)=万分之一。
由条件概率公式得知:p(C,S)=P(S|C)*P(C)=P(C|S)*P(S),
故贝叶斯公式:p(S|C)=p(C|S)*p(S)/p(C)。
其中:P(C)是一个固定值,另外从词串恢复到字串的概率只有唯一一种方式,故P(C|S)=1
所以比较P(S1|C),P(S2|C)的大小,可以化简为:
P(S1|C)/P(S2|C)=P(S1)/P(S2)
因为P(S1)=p(南京市,长江,大桥)=P(南京市)P(长江)P(大桥)>P(S2)=p(南京,市长,江大桥)=P(南京)P(市长)P(江(大桥),故选择S1
3.1.1一元模型
对于不同的S,m的值是不一样的,一般地,m越大,P(S)与越小,即分出的词越多,概率越小
P(S)计算公式:P(S)=P(w1)*P(w2)*P(w3)...P(wn),
P(wi)=(wi在语料库中出现的次数n) / (语料库中的总词数N)
该公式是基于独立假设的,即词与词之间是相互独立的,因此该公式也叫一元模型
3.1.2 N元模型
假设在日本,和服是一个常见词,按照一元模型,可能会把“产品和服务”切分为:产品/和服/务,为了切分更准确需要考虑词所处的上下文
N元模型使用n个单词组成的序列来衡量切分方案的合理性:
估计单词w1出现后,w2出现的概率P(w1,w2)= P(w1)P(w2|w1)
同理,P(w1,w2,w3)= P(w1,w2)*P(w3|w1,w2)=P(w1)P(w2|w1)*P(w3|w1,w2)
更加一般的形式:
P(w1,w2,w3...wn)= P(w1)P(w2|w1)*P(w3|w1,w2)...*P(wn|w1,w2,w3...wn-1)
如果简化成一个词的出现仅仅依赖前面一个词,则为二元模型(Bigram)
P(S)=P(w1,w2,w3...,wn)≈P(w1)P(w2|w1)*P(w3|w2)...P(wn|wn-1)
3.1.3 马尔可夫模型(MM:Markov Model)
N元模型又可以看作马尔可夫模型:每个状态只依赖之前有限个状态

参数:
状态,由数字表示,假设共有M个,初始概率,由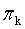 表示
表示
状态转移概率,由 表示
k,l=1,2,...M
3.1.4 隐马尔可夫模型HMM(Hidden Markov Model)
马尔可夫模型是对一个序列建模,但有时我们需要对2个序列建模,
如机器翻译,源语言序列 -> 目标语言序列
语言识别,语言信号序列 -> 文字序列
通常一个序列称为观测序列,一个为隐藏序列,如语言识别中,声波信号为观测序列,记为O,实际上要表达的文字观测不到,记为S,我们要找的就是S,即“说了什么”。
观测序列O中的数据通常是由隐藏序列数据决定的,彼此间相互独立
隐藏序列数据间相互依赖,通常构成了马尔可夫序列
例如语言识别中,每段声波信号是相互独立的,有对应的文字决定
对应的文字序列中,文字间相互依赖,构成马尔可夫序列
观测和隐藏序列共同构成隐马模型:
O(O1,O2,...OT),观测序列,Ot只依赖St
S(S1,S2,...ST),状态序列(隐藏序列),S是马尔可夫序列,假设一阶马尔可夫,则St+1只依赖于St
HMM参数
状态由数字表示,假设共有M个
观测由数字表示,假设共有N个
初始概率(所有初始状态中k状态的样本数/所有初始状态的样本数),由 表示
状态转移概率(k状态到l状态的概率a(k,l)=所有k状态下到l的频次/所有k状态的频次),由 表示
k,l=1,2,...M
发射概率(由k状态发射到u观测值的概率=k状态下观测值u的频次/k状态的频次),由 表示
u=1,2,...N k=1,2,...M
HMM生成过程:
先生成第一个状态,然后依次由当前状态生成下一个状态,最后每个状态发射出一个观测值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









