






 本文主要介绍了Flink的状态管理和容错机制,包括有状态计算与无状态计算的概念,重点解析了Keyed State和Operator State两种类型及其应用场景。Flink的Managed Keyed State包括ValueState、ListState、ReducingState、AggregatingState和MapState,以及它们的接口和生命周期。此外,文章还提及了Operator State的管理以及重分布策略。
本文主要介绍了Flink的状态管理和容错机制,包括有状态计算与无状态计算的概念,重点解析了Keyed State和Operator State两种类型及其应用场景。Flink的Managed Keyed State包括ValueState、ListState、ReducingState、AggregatingState和MapState,以及它们的接口和生命周期。此外,文章还提及了Operator State的管理以及重分布策略。
...................上一章主要是为了早点结束,然后开始下面一个非常重要的章节,这个章节不理解清楚,就对Flink的一些核心思想无法理解跟掌握。
flink 状态管理和容错
1,有状态计算
在Flink里面,有状态计算可以说是最重要的特性之一,刚好今天还有个朋友问我状态是保存在什么地方,是一致存在还是怎么样,下面要讲的就很清楚了。
如下图:
咳咳,回答上面的问题,默认情况下 Flink的state是存储在内存里面的,通过定时checkpoint是存储在分布式文件系统里面 (一般都是HDFS)。
2,无状态计算
与上者不同,无状态计算不会去存储计算过程中产生的结果,也不会将结果用于下一步计算过程中,计算完成输出结果,接入下一条数据继续处理。。。
3,Fkink状态类型及应用
Flink会根据是否按Key进行分区,分为 Keyed State 和 Non-keyed State 两种类型。
1)Keyed State
说白了就是DataStream.keyBy(0) 之后 数据按照key分区。
2)Operator State
Operator State只和并行的算子实例绑定,和数据元素中的Key无关,每个算子实例中都持有所有数据元素中的一部分状态数据。它还支持当算子实例并行度发生变化时自动重新分配状态数据。
3)上者2个state都具有两种形式
第一种形式 为 “托管状态形式”(Managed State),由 Flink Runtime中控制和关联状态数据,并将状态数据转成为内存Hash Tables 或者 RocksDB 的对象存储 然后持久化到checkpoint中,如果出现异常则通过这些状态恢复
第二种形式 为“原生状态”,由算子自己去管理数据结构,触发checkpoint过程中 Flink不知道状态数据内部的结构,只是将数据转换成bytes数据,存储在checkpoints里面,恢复数据的时候,由算子自己再反序列化出状态的数据结构。
总结就是第一种是我们自己去管理,第二种是算子自己去管理。推荐前者...........
4 , Managed Keyed State
Flink 有以下的 Managed Keyed State 可以使用:
1)ValueState ,与key对应单个值的状态 ,更新update() , 获取 value()
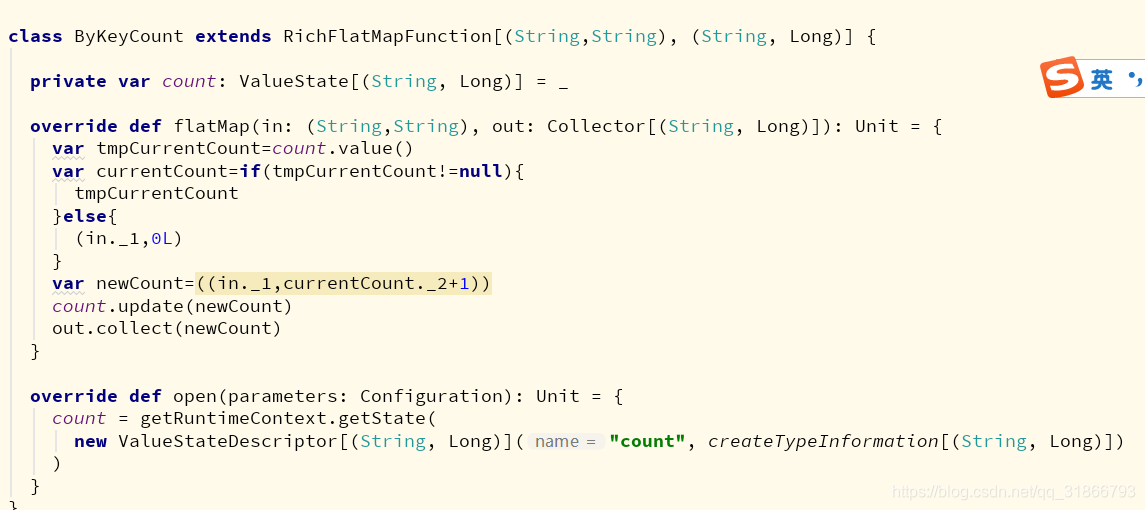
2) ListState 存放的List列表 常用方法 add() addAll(List[T]) get() update(List[T])
3)ReducingState[T] 定义与Key相关的数据袁术单个聚合值的状态,用于存储经过指定ReduceFunction计算之后的指标,方法:add(T) , get()
4)AggregatingState[IN,OUT] 跟reduce不一样在于输入输出类型可以不一样 add[IN] ,get() 方法。
5) MapState 键值对状态。 put(),keys(),values()

他们都会有对应的接口:
6)State的生命周期 (TTL)
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(10))
//指定刷新时对创建和写入操作有效
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
//指定状态可见性
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build()
val valueState = new ValueStateDescriptor[String]("valuestate",classOf[Long])
valueState.enableTimeToLive(stateTtlConfig)
上面代码是案例代码 我自己写报错,没搞成功 ~日 。
注:
StateTtlConfig.UpdateType.OnCreateAndWrite 创建写入时候更新TTL
StateTtlConfig.UpdateType.OnReadAndWrite 所有读写操作都更新TTL
StateTtlConfig.StateVisibility.NeverReturnExpired 状态数据过期了就不返回了
StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp 状态数据过期但还没清理依然返回。
5,Managed Perator State
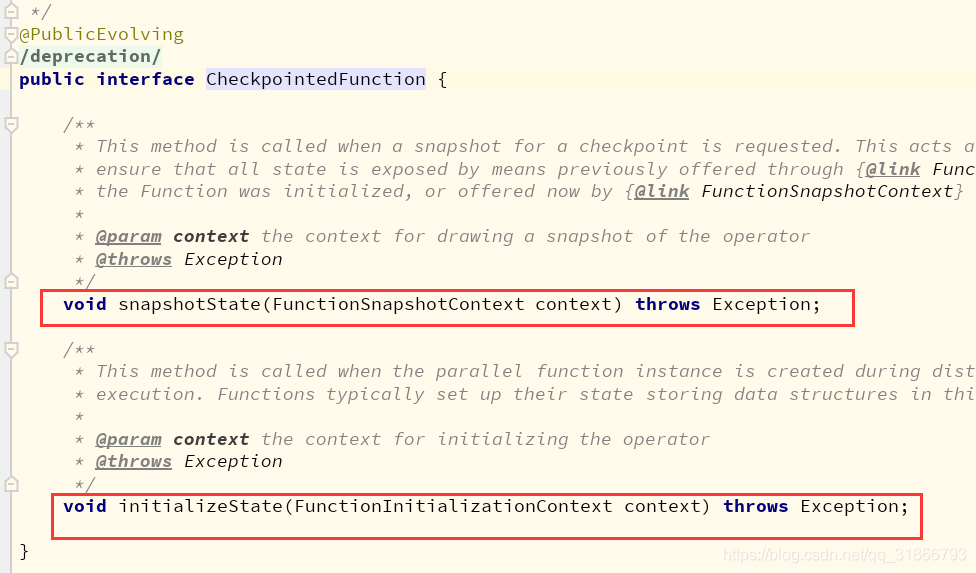
1)通过 checkpointedFunction 接口操作 Operator State,注意,在每个算子Managed Perator State 都是以List形式存储
2) Flink 目前只支持 对 Managed Perator State两种重分布的策略,分别是
Even-split Redistribution 和 Union Redistribution
3)简单案例 实现checkpointedFucntion接口统计输入到算子的数据量
class CheckpointCount(val numElement:Int) extends FlatMapFunction[(Int,Long),(Int,Long,Long)] with CheckpointedFunction{
//存储数据数量
private var operatorCount :Long =_
// 存储key相关的状态值
private var keyedState :ValueState[Long] =_
//存储算子的状态值
private var operatorState :ListState[Long] =_
override def flatMap(value: (Int, Long), out: Collector[(Int, Long, Long)]): Unit = {
val count = keyedState.value()+1
keyedState.update(count)
//更新本地算子的值
operatorCount = operatorCount + 1
//输出结果
out.collect((value._1,count,operatorCount))
}
//当发生snapshot时候,操作
override def snapshotState(context: FunctionSnapshotContext): Unit = {
operatorState.clear()
operatorState.add(operatorCount)
}
//初始化
override def initializeState(context: FunctionInitializationContext): Unit = {
keyedState= context.getKeyedStateStore
.getState(new ValueStateDescriptor("keyedState",createTypeInformation[Long]))
operatorState= context.getOperatorStateStore
.getListState(new ListStateDescriptor("keyedState",createTypeInformation[Long]))
if (context.isRestored){
operatorCount = operatorState.get().asScala.sum //这里恢复数量,写法要完善。scala会报错
}
}
}
4) 通过ListCheckpointed 接口定义 Operator State
class CheckpointCountDemo extends FlatMapFunction[(String,Long),(String,Long)] with ListCheckpointed[Long]{
//接入的数据量
private var numberCount :Long = 0L
// 统计方法
override def flatMap(value: (String, Long), out: Collector[(String, Long)]): Unit = {
numberCount += 1
out.collect(value._1,numberCount)
}
override def snapshotState(checkpointId: Long, timestamp: Long): util.List[Long] = {
Collections.singletonList(numberCount)
}
//重置
override def restoreState(stateList: util.List[Long]): Unit = {
numberCount =0L
for (count <- stateList){
numberCount += count
}
}
}
总结,顺便也写了一下循环 +=累加是不~~~,完事了 。下次继续,外面好像下雨了 。。。我了个去。。怎么回去啊。。。。蛋疼

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









