







分享一个sql查询
首先:介绍一下表结构
CREATE TABLE ZYRS_METADATA.T_EXTRACTOR_MESSAGE (
ID VARCHAR ( 32 ) NOT NULL PRIMARY KEY, --uuid
TASK_INSTANCE_ID VARCHAR ( 32 ), -- 任务ID
LAST_UPDATE_TIME BIGINT, --上次更新时间
DATASOURCE_NAME VARCHAR ( 32 ) NOT NULL,--数据源名称
DATASOURCE_ID VARCHAR ( 32 ), --数据源ID
NEW_SCRIPT_PATH VARCHAR ( 128 ), --新脚本路径
OLD_SCRIPT_PATH VARCHAR ( 128 ), --旧脚本路径
IS_ADD_SCRIPT CHAR ( 2 ) --是否新增脚本
)其次:介绍一下我的查询需求
第一步我需要查询 DATASOURCE_ID, DATASOURCE_NAME, LAST_UPDATE_TIME这三个字段。
第二步我要按照DATASOURCE_ID查询出这个记录出现了多少次,left join字段WAIT_NUMBER表示出现的次数。
第三步我需要根据我查出的记录按照DATASOURCE_ID为基准取每条记录中LAST_UPDATE_TIME最大的那个值
最后:我编写的SQL如下所示
select * from (
select DATASOURCE_ID,DATASOURCE_NAME,LAST_UPDATE_TIME,WAIT_NUMBER,ROW_NUMBER() OVER (PARTITION BY DATASOURCE_ID ORDER BY LAST_UPDATE_TIME DESC) AS RN FROM (
SELECT DISTINCT
t.DATASOURCE_ID,
t.DATASOURCE_NAME,
t.LAST_UPDATE_TIME,
g.WAIT_NUMBER
FROM
T_EXTRACTOR_MESSAGE t
LEFT JOIN ( SELECT f.DATASOURCE_ID, count( * ) AS WAIT_NUMBER FROM T_EXTRACTOR_MESSAGE f GROUP BY f.DATASOURCE_ID ) g ON g.DATASOURCE_ID = t.DATASOURCE_ID)) d where RN=1附:查询样式
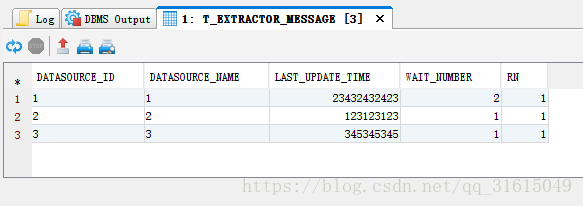

















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









