






 文章介绍了如何从CSV文件加载数据集,处理其中的缺失值,特别是通过插值法填充数值列和对类别列的特殊处理。之后,讨论了删除缺失值最多的列,并最终将预处理后的数据转换为张量格式,为后续分析或模型训练做准备。
文章介绍了如何从CSV文件加载数据集,处理其中的缺失值,特别是通过插值法填充数值列和对类别列的特殊处理。之后,讨论了删除缺失值最多的列,并最终将预处理后的数据转换为张量格式,为后续分析或模型训练做准备。
1.读取数据集
创建一个人工数据集,并存储在CSV文件 …/data/house_tiny.csv中


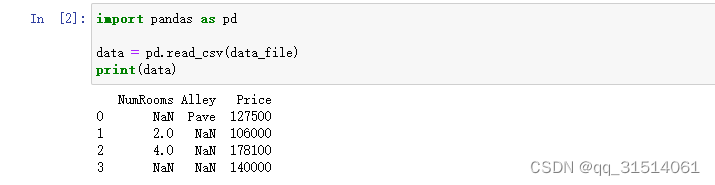
要从创建的CSV文件中加载原始数据集,我们导入pandas包并调用read_csv函数。该数据集有四行三列。其中每行描述了房间数量(“NumRooms”)、巷子类型(“Alley”)和房屋价格(“Price”)。
2.处理缺失值
注意,“NaN”项代表缺失值。 为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。 在这里,我们将考虑插值法。
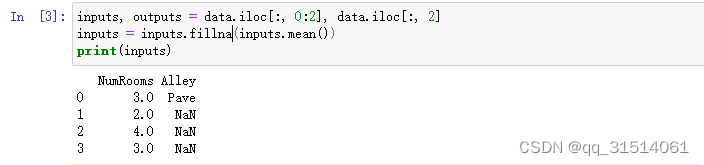
通过位置索引iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。 对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
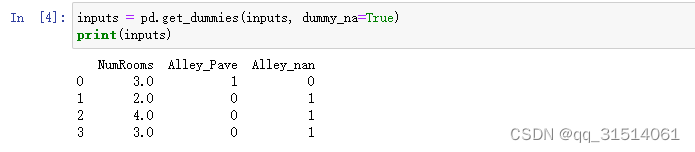
对于inputs中的类别值或离散值,我们将“NaN”视为一个类别。 由于“巷子类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”, pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。 巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
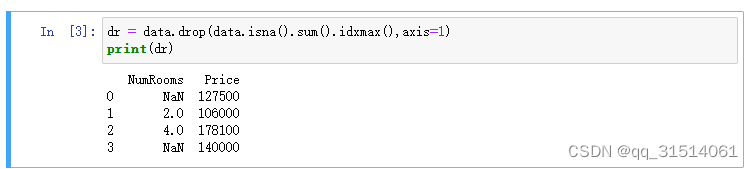
2.1删除缺失值最多的列
isna() 方法来获取数据集中缺失值的布尔矩阵,然后使用 sum() 方法计算每列缺失值的数量,最后使用 idxmax() 方法获取缺失值最多的列的索引。

最后用drop()删除 DataFrame 对象中的缺失值。
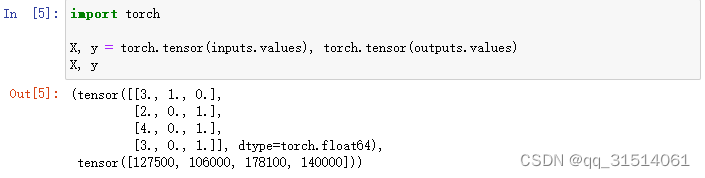
3.将预处理后的数据集转换为张量格式
现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式。 当数据采用张量格式后,可以通过在数据操作中引入的那些张量函数来进一步操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









