







详细图片展示请点击https://zhuanlan.zhihu.com/p/43373383
曾经,我把目光放在你身体上四分位的地方,发现了世界的美好。。。
之后,山水流转,时光荏苒,不再从前。。。
此一文,献给过往。
先上张图:好奇怪,为什么是这么个比例[皱眉]
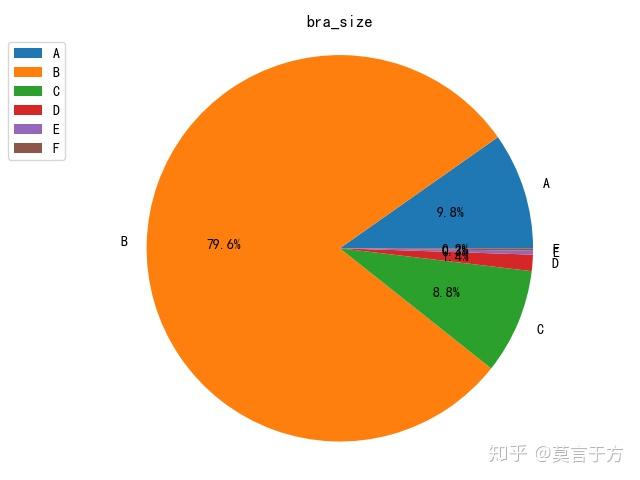
这篇文章分为两个部分,python爬虫和数据分析。爬取京东bra一些数据,并进行分析,在上帝视角看一看bra的秘密。
第一部分,爬虫部分。
爬虫部分利用python和selenium包,爬取京东数据,将数据保存在数据库中。
第二部分,将爬到的数据使用pandas包和matplotlib包进行清洗,在可视化
第一步,先导入包,需要导入的包有,selenium包,用来模仿浏览器,lxml包,用来分析网页信息,显示等待和隐式等待包,数据库包。如下
from selenium import webdriver
import time
from lxml import etree
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from databases import Write_databases然后,写打开浏览器接口,再获取URL列表时,使用PhantomJS浏览器。
#打开浏览器,返回driver
def open_web():
driver = webdriver.PhantomJS()
return driver获取京东商城前100也的bra商品详情页的URL,(前100页已经足够了,50页之后的商品就基本没有销售信息了)
#获取bra列表,获取每个bra的ID,生成详情页的url,返回url列表
def get_bra_list(driver,url):
bra_list_urls = [] #定义URL列表
driver.get(url)#打开浏览器
i=100
while i>0:#设置爬取前100页
html = etree.HTML(driver.page_source)
bra_lists = html.xpath(".//div[@id='J_goodsList']/ul/li")
for bra_list in bra_lists:
bra_id = bra_list.xpath(".//div[@class='p-price']/strong/@class")
bra_detail_url = 'https://item.jd.com/'+bra_id[0].split('_')[1]+'.html'
bra_list_urls.append(bra_detail_url)
next_btn = driver.find_element_by_class_name('pn-next')#某一页数据爬取完成时,点击下一页按钮
next_btn.click()
i -= 1
print("=*"*20+str(i))
return bra_list_urls得到URL列表之后,再按照列表中的URL一个一个爬取即可。
爬取详细URL相应信息,进入详情页面之后,首先需要爬取价格,然后点击商品评价,如图

然后再爬取商品评价中的颜色,尺寸,时间
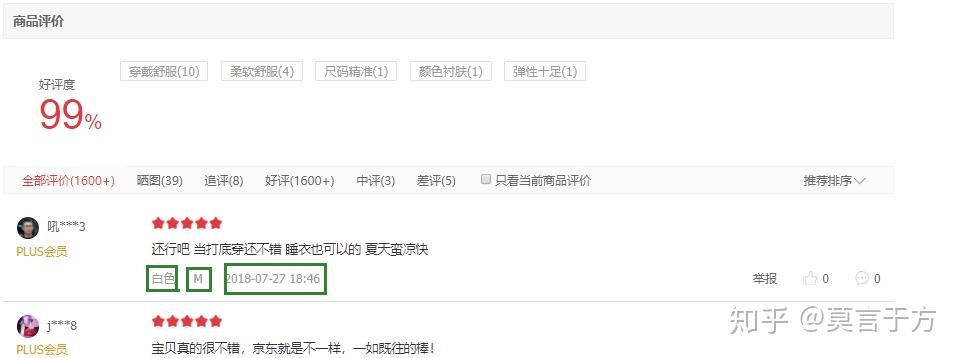
如下步骤,这次,使用Chrome浏览器
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









