




 本文介绍了如何使用CrawlScrapy框架结合代理爬取Boos直聘的职位信息。CrawlScrapy基于Scrapy,通过链接提取器进行URL匹配。文章详细讲解了爬虫结构,包括爬虫部分(定义爬取规则和解析网页)、下载器中间件(实现代理功能以防止IP被封)和Pipeline(保存数据到JSON文件)。同时,推荐了‘零基础:21天搞定Python分布爬虫’的学习资源。
本文介绍了如何使用CrawlScrapy框架结合代理爬取Boos直聘的职位信息。CrawlScrapy基于Scrapy,通过链接提取器进行URL匹配。文章详细讲解了爬虫结构,包括爬虫部分(定义爬取规则和解析网页)、下载器中间件(实现代理功能以防止IP被封)和Pipeline(保存数据到JSON文件)。同时,推荐了‘零基础:21天搞定Python分布爬虫’的学习资源。
写在前面和推荐学习
零基础:21天搞定Python分布爬虫
在本文中使用CrawlScrapy框架结合代理来实现对Boos直聘职位信息的爬取。
简单说明Scrapy框架
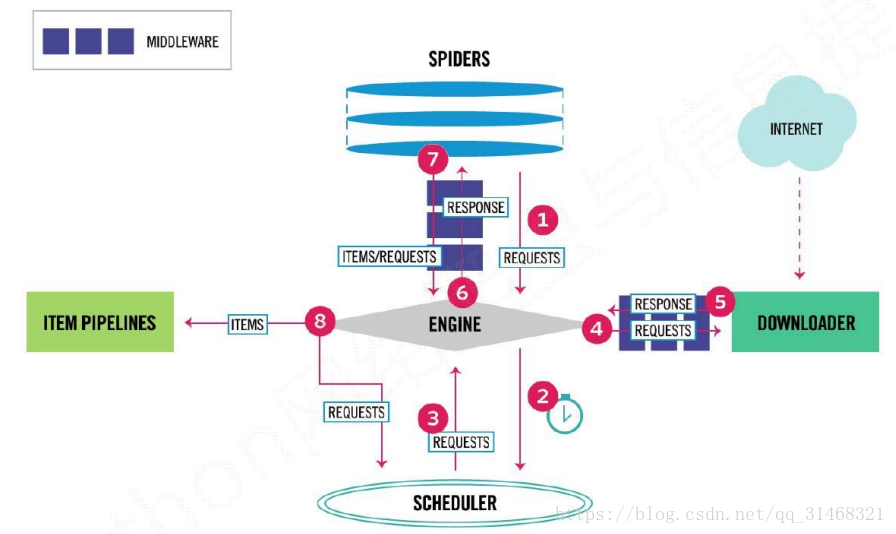
主要流程
1.爬虫发送一个请求给引擎
2.引擎将这个请求发送给调度器
3.调度器按照一定的方式进行整理,在将请求发送给引擎
4.引擎再次将请求发送给下载器中间件,去到网络中请求资源进行下载
5.下载之后封装为Response对象,返回给引擎
6.引擎在将Resonse发送给爬虫提取信息,如果请求正常这时爬虫返回一个ITEMS,否则返回一个Resqust对象给引擎,再次进入调度器
7.这个items/Request返回给引擎,引擎将ITEMS对象发送给Pipeline对数据进行保存
爬虫结构
本次爬虫使用的是CrawlScrapy框架,这个框架继承了Scrapy框架,流程一致,不同的是,CrawlScrapy框架中有一个链接提取器,通过正则表达式进行匹配页面中所有的URL,有点广度优先的思想。
链接提取器如下:
rules = (
#c101010100/?query=数据分析&page=2
Rule(LinkExtractor(allow=r'.+/\?query=python&page=\d'), follow=True),
#https://www.zhipin.com/job_detail/9f625f605d18d1661XN_39--GFU~.html
Rule(LinkExtractor(allow=r'.+/job_detail/.+'), callback='parse_item', follow=False),
)
在此次爬虫中主要实现了如下几个部分:
- 爬虫部分,解析提取网页
- 实现了链接提取器中的规则,确定了需要爬取那些网页
- 实现了下载器中间件部分,在该部分添加了代理的功能,这样即使IP被封也可以继续爬取信息
- 实
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1880
1880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









