 Redis数据结构解析
Redis数据结构解析





 本文深入解析Redis中的六种核心数据结构:String、Hash、List、Set、ZSet及它们的具体实现原理,包括SDS、ziplist、hashtable、skiplist等。
本文深入解析Redis中的六种核心数据结构:String、Hash、List、Set、ZSet及它们的具体实现原理,包括SDS、ziplist、hashtable、skiplist等。
由于面试中常常被问到,所以特意整理一篇出来,重在几种数据结构的实现原理,操作命令请看前一篇文章
String

这就是String的结构,也是redis最常见最基础的一种结构,我们从它说起,进而引申出其他四种结构。
key-value是外层实现,是用字典(hashtable)实现的。
key的类型
key的类型是redis中特有的字符串实现-SDS。因为redis是C语言实现的,而c语言中只有char[]类型没有字符串类型。那为什么redis不用char[]类型,要自己实现一个SDS呢?其实就和java为什么实现一个String类型而不是直接用char[],一样的道理。
主要有四点原因:
- 因为如果直接使用char[]类型的话,需要事先指定大小,不然容易数组溢出,SDS不用担心溢出问题。
- 如果要获取这个字符串的长度,需要遍历数组,时间复杂度是O(N),SDS定义了len属性,所以复杂度是O(1)
- c语言中,char[]长度变更的话,会对内存重新分配
- 二进制不安全,需要判断末尾的/0符号,对于一些视频、压缩文件等并不友好
value的类型
value的类型是一个redisObject类型。我们本文的目的-几种存储结构的实现其实就是指value的几种实现,也就是redisObject中包含的几种类型。
typedef struct redisObject {
unsigned type:4; /* 对象的类型,包括:OBJ_STRING、OBJ_LIST、OBJ_HASH、OBJ_SET、OBJ_ZSET */
unsigned encoding:4; /* 具体的数据结构 */
unsigned lru:LRU_BITS; /* 24 位,对象最后一次被命令程序访问的时间,与内存回收有关 */
int refcount; /* 引用计数。当 refcount 为 0 的时候,表示该对象已经不被任何对象引用,则可以进行垃圾回收了 */
void *ptr; /* 指向对象实际的数据结构 */
} robj;
也就是上面的type:OBJ_STRING(字符串)、OBJ_LIST(链表)、OBJ_HASH(哈希)、OBJ_SET(集合)、OBJ_ZSET(有序集合)
对于我们本小节的String,对应的type就是OBJ_STRING
比如我执行一个命令
set hello world
它的存储就是这样的

这里的dictEntry可以理解为类似于HashMap中的Entry,当然,redis对hashTable的实现不是这么简单的,放到下面hash结构中细讲
OBJ_STRING里面也是redis的字符串实现的,也就是SDS。(这里的SDS有三种编码方式,字符串长度不同,编码方式也不同)
String小结
总结下来,String的实现,key是一个redis自己实现的SDS字符串类型,value是一个redisObject对象,redisObject具体类型是OBJ_STRING,本质也是SDS。
Hash哈希
如果说String是最基础的一种结构,那么hash应该是常用的一种结构。
毕竟实际应用中大多是比较复杂的数据结构,简单的string类型并不能很好的满足需求。
value的实现需要一个合适的结构来承载类似于dto这种的结构。
也就是hash
懒得画图了,盗一张图

key
key没啥好说的,几种结构都一样,见String的key说明
value
String的value就是一个String,而hash的value是一个hash。
注意,此时就有两个hash结构了
- 外层哈希:
外部的一个Entry<key,value>是redis本身的外层哈希
key就是这里的teacher:qingshang这个字符串
value是右边这一坨,包括所有的field和所有的value。 - 内层哈希:
也就是redisObject中的type类型为OBJ_HASH时
把上面的value用hash的结构存储起来
内层哈希
内层哈希就是我们本小节要说的哈希。
它是一个哈希结构没错,但是哈希同样有很多种实现,类似于java中也有hashMap、hashTable、hashSet等多种实现。
redis中的内层哈希有两种具体的实现方式:hashtable(哈希表)和zipList(压缩列表)
zipList
先说zipList吧
ziplist叫做压缩列表,其实从名字我们可以猜到两个点
压缩,猜测它肯定是以空间为重的,优先考虑存储空间
列表,猜测它是一个列表结构。
带着这种猜测再去看它的结构,会好理解很多
zipList是什么
它的源码中注释翻译过来如下:
ziplist 是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一 个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能, 来换取高效的内存空间利用率,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面。
zipList的内部结构
c源码如下:
typedef struct zlentry {
unsigned int prevrawlensize; /* 上一个链表节点占用的长度 */
unsigned int prevrawlen; /* 存储上一个链表节点的长度数值所需要的字节数 */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数 */
unsigned int len; /* 当前链表节点占用的长度 */
unsigned int headersize; /* 当前链表节点的头部大小(prevrawlensize + lensize),即非数据域的大小 */
unsigned char encoding; /* 编码方式 */
unsigned char *p; /* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 */
} zlentry;
是不是又臭又长不想看?没关系,那就先不看,但是完了一定要看看,从源码的命名以及代码结构,也能学到挺多的。
看一下结构图吧,比较清晰
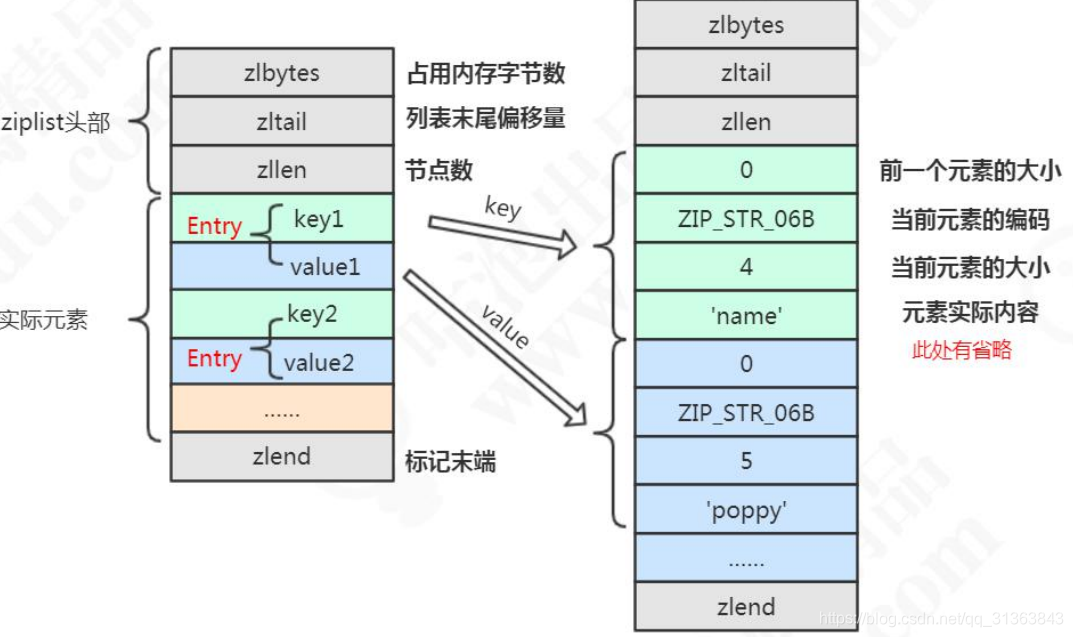
注意几个关键点,就很容易看懂了。
- Entry,是不是很熟悉?对的,就是键值对,hash结构的核心,实际存储k-v键值对的东西。
- key,注意key的结构,主要包含四个属性:
– 上一个元素的大小:能够根据这个找到上一个元素的内存地址开始的位置,偏移量运算
– 当前元素的编码:没啥好说的,就是字面意思,key长度不一样,用的编码不一样
– 当前元素的大小: 根据这个能计算出下一个元素的位置
– 元素实际内容: 这就不用说了吧 - value,和key的结构一样
编码 encoding(ziplist.c 源码第 204 行)
#define ZIP_STR_06B (0 << 6) //长度小于等于 63 字节
#define ZIP_STR_14B (1 << 6) //长度小于等于 16383 字节
#define ZIP_STR_32B (2 << 6) //长度小于等于 4294967295 字节
综上,根据上一个元素的大小和当前元素的大小就能实现一种特殊的双向链表了。
其实叫链表不合适,因为它没有链,只有表,这句话怎么理解呢?
就是通常的链表都是存储着指针,指针指向下一个节点的内存地址,这种存储结构的后果就是一条链表的内存占用一定是一个碎片化的。
但是ziplist不是这样,他不是通过指针来寻找元素的,所以它可以把所有元素按照顺序放在一大块内存中。
但是同样的,虽然避免了内存碎片化,但是这种内存整体化的缺点就是不利于拓展,比如我一开始定了一个大小为100的ziplist,后面元素多了,必然要进行扩容,扩容的代价也不低。这也是为什么ziplist只适合于字段小且数量少的场景中。
hashtable
hashtable为什么说他重要呢?因为外层哈希和内层哈希都是用的这个玩意儿。
上面说外层哈希的时候(不记得的可以翻上去看一下),提到了一个类型-dictEntry
这个其实就是哈希结构的键值对实现(就像ziplist中的Entry一样,每一种哈希结构的核心必然是这样的键值对结构)
当然,实际的hashtable,为了增强一些功能,比如解决哈希冲突、扩容等操作,会对这个dicEntry键值对做进一步的封装。
一层一层的包下来就像这样

- dictEntry* [n] :如果你对hashmap的源码有理解的话,就会好理解很多。这东西其实就类似于hashmap中的一个table()数组,123代表着一个个的桶,桶后面是一个链表,存储着哈希冲突的一个个节点,这个封装的目的就是为了把dictEntry封装成一个数组+链表的结构来解决哈希冲突
- dictht :这个东西,某种程度上和dictEntry* [n]是一样的概念,这个封装的目的是封装了一些属性,用来形容存储dictEntry* [n]这个数组的大小等属性。
- dict:这个东西其实就是dictht的进一步封装。这个封装的目的是为了哈希表的扩容。你可能注意到了,dict里面有两个引用,ht[0]和ht[1],正常情况下,我们只用ht[0]指向的这一个表。如果链表长度过长,也就是节点数量比dictEntry* [n]这个数组的大小大很多,表明哈希冲突比较严重,说明需要扩容了。这个时候就会把ht[1]给开辟出来使用。
具体的扩容操作类似于hashmap,ht[1]的空间默认是ht[0]的两倍,分配好空间以后,把ht[0]上面的数据重新计算hash值,放到ht[1]中。所以扩容也叫做rehash。之后把ht[0]的空间释放,ht[1]设置为新的ht[0],并创建新的ht[1]以备下次扩容使用。
hashtable注意事项
hashtable使用起来有一点需要注意,就是它的value只能存储简单的string类型,换句话说就是不能再存一个hashtable这种套娃行为了。
如果我有一个对象,里面有个字段的属性是一个dto或者list类型的,使用hash存储就不太方便了。这个时候可以把它序列化成一个字符串,当成string存储。当然这样的话如果频繁的读取修改某个字段,一直序列化反序列化代价也不小。
list列表
其实如果搞懂了hash,像list这种简单的结构就信手拈来了。
它就是一个简单的列表,结构如下

具有着列表的特性:有序、允许重复
所以通过不同的操作命令,可以达到先进先出(队列)、先进后出(栈)的效果
list的存储结构
早期版本
之前的版本,数据量小的时候用ziplist存储,数据量到达临界值后用linkedlist存储
ziplist前面介绍过了,linkedlist虽然没介绍,但是通过这句话已经能明白它的几大特点了
相较于,ziplist的压缩结构,通过元素长度来寻找其他元素,linkedlist是直接存了指针
相较于ziplist牺牲时间换空间,适用于小数据,linkedlist适用于更长的数据
当今版本-quicklist快速列表
当今版本把ziplist和linkedlist做了一个结合,叫做quicklist

- quicklist: 维护了一个双线链表,*head指向头节点,*tail指向尾节点
- quicklistNode: 链表中的一个节点,这个节点的数据结构就是一个zipList
那么为什么要整合这俩结构呢?
首先,我们知道了ziplist和inkedList的优缺点,再一看quicklist的结构,就明白原因了。
- 在相同的数据量下,quicklist比linkedlist内存碎片更大,数量更小
- 在相同的数据量下,quicklist比ziplist更利于内存的拓展。
就像java中的linkHashMap,也是在hashMap的基础上,给entry节点之间做了个链表,有很多这种结合实现的数据结构,他们之间并不是独立存在的,都是某种场景下的拓展和增强。
Set集合
如果说list是一个有序可重复的列表,那么set就是一个无序不允许重复的集合
明白上面这句话,其实就基本明白了set的结构

set的实现
我们先猜测一下
set既然无序,那么首先排除链表(ziplist、linkedlist、quicklist)
既然不允许重复,那么可能是类似于java中的set的这种结构,比如HashSet
带着猜测往下看
intset
intset是redis实现的一种存储结构,用来存储整数类型的、不允许重复的值,是set的实现之一。
hashtable
如果当value的值并不是整数,或者说即便是整数但是元素数量超过了512个,就不能用intset了
会用hashtable
这里又要提一嘴hashmap了,所以说hashmap是一个很经典很重要的数据结构。java中hashSet的实现就是基于hashMap。当我们执=hashSet.add(value)的时候,这个value存在了hashmap的key中,value存了一个固定的Object的值。利用了hashmap的key的不重复性,来满足hashSet的特性。
redis中,使用hashtable实现set结构的时候,也是基于这种原理,key存储元素的值,value存储null。
zset有序集合
相较于set,zset是一个有序的集合,它满足有序、不允许重复的特征。
这里的有序并不是指插入的顺序,而是
- zset在插入元素的时候会指定一个score,比如
zadd myzset 10 zhangsan 20 lisi 30 wangwu,score分别是10、20、30 - 当score相同时,按照元素的ASCII码来排序
所以它的数据结构一定基于链表的,这样才能保证起码有序。
至于不重复的,插入的时候遍历比较,也可以保证。
这么一想,ziplist、linkedList、quicklist这种list结构貌似可以实现zset的特性
ziplist实现zset
确实,当我们元素的数量小于128个,且元素的大小都小于64字节,也就是说整体数据量比较小的时候,是可以用ziplist来实现的。
skiplist跳表+dict哈希实现zset
当数据量起来的时候,用ziplist就不合适了,因为每次插入元素都要去遍历,进行排序,校验是否重复,是比较慢的。
所以这个时候用skiplist+dict
dict比较熟,就是键值对。
skiplist又是什么呢?
在去思考skiplist是什么之前,我们先回想下,在list的早期结构中,数据量起来的时候,ziplist怎么转变的?
没错,转变为了linkedlist
我们看下,如果使用linkedlist实现zset

是可以的,但是随着链表长度的加长,遍历元素带来的代价也是逐渐增大的。
同样的问题,list是怎么解决的?没错,quicklist!既然list中能用quicklist代替ziplist,那么zset中也可以寻找类似的结构来代替quicklist。
所以我们的skiplist就出现了
skiplist
废话不多说,直接上跳表结构

聪明的同学已经看出来了,它每隔两个节点增加了一层结构来存储额外的指针,去指向下下个元素,这样再遍历的时候,就能减少很多遍历次数了。
比如要查找23

- 23 首先和 7 比较,比它大
- 23 再和 19 比较,比它大,继续向后比较。
- 但 23 和 26 比较的时候,比 26 要小,因此回到下面的链表(原链表),与 22 比较。
- 23 比 22 要大,沿下面的指针继续向后和 26 比较。23 比 26 小,说明待查数 据 23 在原链表中不存在
可能这个链表长度还不够长,所以不明显,如果链表足够长,这种比较方式带来的跳跃能够减少很多遍历次数。
可能有同学问啦,为什么不可以用quicklist,你对比下二者的结构,再想想zset和list的特性区别就明白了
二者虽然都是有序的,但是因为这个顺序并不相同
list是插入顺序,所以直接插入即可
zset插入的时候需要遍历元素去比较score或者key的ASICII码,有一个遍历的过程。
而且zset是不允许有重复元素的,也必然需要遍历。
显然quicklist的结构并没有给遍历元素带来什么便捷之处。


















 173万+
173万+




 到【灌水乐园】发言
到【灌水乐园】发言









