







一、什么是java集合
java集合是用来存放java对象的容器,集合类放在 java.util 包中。
注意:
1.java 集合只能存放对象,如果存入的是基本的数据类型,会进行装箱,然后在存放到集合中
2.集合存放时是对象的引用,对象本身还是存在在堆内存中
3.集合可以存放不同类型(一般不会这么做)、不限数据的数据类型
二、java集合架构图
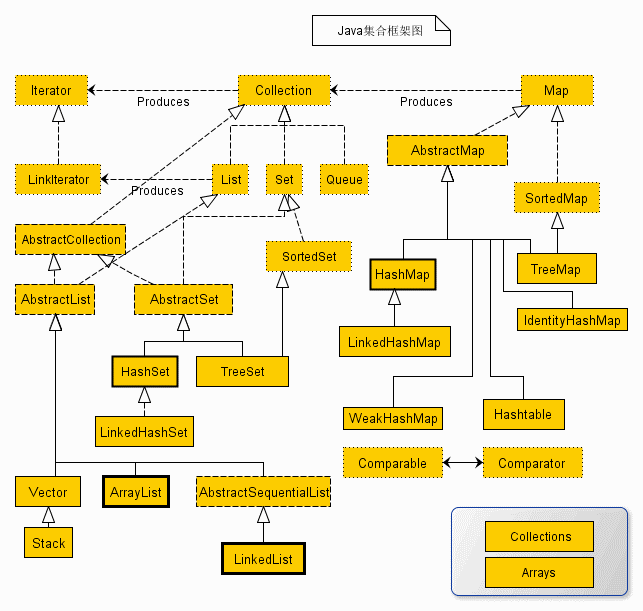
通过集合架构图可以看出,除了 Map 集合外,其他所有的集合都实现了 Iterator 接口 。这就是为啥 Map 集合不能使用forech 遍历的原因了。
三、List:有序的可以重复的集合
1.典型实现
a) ArrayList :底层数据结构是数组,默认初始化数组的大小为10,或者是一个空的数组,默认每次扩容原来大小的1.5倍。因 为是数组结构,所以ArrayList 的查询速度很快,增删慢。线程不安全,但是高效。同步到方式:
List list = Collections.synchronizedList(new ArrayList(...));
b)Vector:底层实现是数组,默认初始化数组的大小为10,或者是一个空的数组,默认每次扩容原来大小的1.5倍,查询快,增删慢,线程不安全,效率低。但是这个集合基本没有在使用了。
c)LinkedList:底层的数据结构是链表,查询慢,增删快,线程不安全,效率高。如果需要使用同步,方式如下:
List list = Collections.synchronizedList(new LinkedList(...));
四、Set:无序、不可重复的集合(Map 集合的 Key 组成)
1.典型实现:
a)HashSet:不保证元素的顺序,不可以重复,线程不安全,集合的元素可以为 null。底层的实现是一个 数组 ,存在的意义就是为了加快查询的速度。默认的初始化大小是 16,加载因子是0.75 (实际上使用的是HashMap实现的,key存放数 据)。元素的存放的位置通过 hash(value) 计算的结果,在存放到对应的位置上,所以自定义的对象为了判断对象是 否是相同 的对象,都要是实现 hashCode()、equals()方法。需要注意的是,只有 hashCode()返回的值 与 equals()返回为 true 才认为是一个相同的对象。同样也是线程不安全的,如果需要实现同步使用如下方式:
Set s = Collections.synchronizedSet(new HashSet(...));
b)LinkedHashSet:有序、不重复的集合,底层采用 链表和哈希的算法。元素可为 null。默认的初始化大小是 16,加载因子 是0.75。链表是为了保证数据的有序性,哈希算法保证数据的唯一。线程不安全,需要达到线程安全,使用如下方式:
Set s = Collections.synchronizedSet(new LinkedHashSet(...));
c)TreeSet:有序、不可重复。底层使用红黑树算法,擅长于范围内查询数据。自定义的对象必须实现 Comparable 接口,覆 盖 compareTo(Object obj) 方法(用来比较对象的顺序,需要自己根据实际情况考虑如何判断)。而且不能放入 null 元 素,线程不安全,需要达到线程安全,使用如下方式:
SortedSet s = Collections.synchronizedSortedSet(new TreeSet(...));
d)HashSet、LinkedHashSet、TreeSet 比较:
相同点:
1.都不允许元素重复
2.都不是线程安全的类
不同点:
1.HashSet:不保证元素的添加顺序,底层采用 哈希表算法,查询效率高。判断两个元素是否相等,equals() 方法返回true,hashCode() 值相等。即要求存入 HashSet 中的元素要覆盖 equals() 方法和 hashCode()方法
2.LinkedHashSet:HashSet 的子类,底层采用了 哈希表算法以及 链表算法,既保证了元素的添加顺序,也保证了查询效率。但是整体性能要低于 HashSet
3.TreeSet:不保证元素的添加顺序,但是会对集合中的元素进行排序。元素不能为 null。底层采用 红-黑 树算法(树结构比较适合范围查询)
五、Map:key-value的键值对,key不允许重复、value 可以
1.严格来说 Map 并不是一个集合,而是两个集合之间的映射关系
2.Map 集合没有实现Collection 接口,也没有实现 Iterable 接口,所以不能使用 for-each遍历
3.常用实现:
a)HashMap: 采用哈希表算法,是无序的顺序是有计算出来的 hash 值决定,key 不允许重复,key相同的判断标准是equals 为true , hashCode 相同。HashMap 允许 null 键和 null 值。JDK1.8 以后当链表的长度超过8转成红黑树,如果需要同 步的 Map 集合,建议使用 concurrentHashMap
b)TreeMap:采用红黑树算法,按一定的顺序进行排序,重复放入标准是 compareTo/compare 返回时0。TreeMap 不允许 null 键但允许 null 值
c)HashTable:采用哈希算法,时 HashMap 的前身。HashTable 不允许 null 键和 null 值。线程安全,但是性能较低,基本不 再使用。
d)HashMap、TreeMap、HashTable比较:
1.HashMap、TreeMap 都是线程不安全,HashTable 是线程安全
2.HashMap允许 null 键和 null 值、TreeMap 不允许 null 键但允许 null 值、HashTable 不允许 null 键和 null 值

















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









