







 本文深入探讨数据结构,如红黑树、B树、B+树的特点与应用,对比不同排序算法(如二分法、选择排序、冒泡排序、插入排序、希尔排序、归并排序、快速排序)的效率与适用场景,解析迪杰斯特拉算法及多项切分法等高级技巧。
本文深入探讨数据结构,如红黑树、B树、B+树的特点与应用,对比不同排序算法(如二分法、选择排序、冒泡排序、插入排序、希尔排序、归并排序、快速排序)的效率与适用场景,解析迪杰斯特拉算法及多项切分法等高级技巧。
1、习惯类中bool仿函数作为定义条件。
2、深拷贝时慎用strcpy_s( ),考虑memcpy_s( )
strcpy_s(this->name, 5, name);
memcpy_s(this->name, size,name,size);
3、函数对象是一个类而不是函数,只是能像函数一样使用,并且可以有返回值。
int operator()(参数…){};
4、树
I 红黑树: 红黑树+链表 解决hasH冲突
(1)、二分:有序数列的序列起始点 (max+min)/ 2。(二叉树,二叉查找树,二叉搜索树)
例如 0—100 :
 i 插50;ii 插入(50+100)/ 2 = 75。
(2)、二叉搜索树:
 i 左子树不为空,则左子树上的节点都小于根节点。
 ii 右子树不为空,则右子树上的节点都大于根节点。
 O(n) = O( logn ) ~ O(n).<贪心算法只能用于赫夫曼树,不能生成二叉搜索和红黑树>
(3)、解决O(n)的方法是用平衡树(AVL树比红黑树更严格,AVL树左右高度相差不超过1,红黑树只追求局部的平衡即可,所以数据量大,插入删除频繁的话就不能使用AVL树了):
发展过程:链表(暴力查找)->二叉树->二叉查找树->特殊的二叉查找树(自平衡二叉查找树)包括特殊的红黑树
  i 、 红黑树:
a 每个节点不是红色就会黑色,
b 两个红色不能相连,但两个黑色可以相连。
c 根节点都是黑色root
d 每个红色节点的两个子节点都是黑色。
叶子节点都是黑色:出度为0满足了性质就可以近似的平衡了。
  ii 红黑树的三种变换
  a、改变颜色:最简单,红变黑,黑变红。
  b、左旋:如图(E为初始根节点,s为右子树),s变为根节点,E为S的左子树,S之前的左子树为E的右子树(取代了S之前的位置)
  c、右旋:左旋的逆操作
  iii 变换规则如下图:

(4)、查找:
  目录查找:类似索引
  键查找:hash查找
  遍历:暴力查找
  二分:B+树的基础算法
  带索引的数据结构:数组,链表,B树以及B+树,hash_map(红黑树),hash(数组+链表)。
红黑树读取磁盘次数过多,浪费资源(IO),不适合硬盘上数据的查找,所以不能用在mysql,但是内存上的数据可以,所以hashmap底层用红黑树。
(5)B树:(Binary tree最复杂的数据结构,不属于平衡树范围,但是相对于比较平衡):B-tree ,B+tree,B*tree。
 M阶B数有M个子树,M阶B树的重要特性:
节点最多含有M棵子树,M-1个关键字(存的数据,空间)(m >= 2);
除根节点和叶子节点外,其他每个节点至少有ceil(m/2)个子节点,ceil 为上取整(2.5》3)。
若根节点不是叶子结点,则至少有两棵树。
构建过程:有一个非常重要的操作,不满足以上性质时,会进行分裂操作(B-tree)
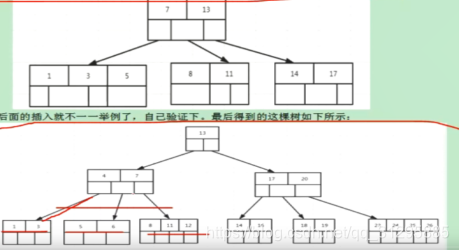
  B+树:mysql 用的是改进后的B+树(用到了双向链表)。
  叶子节点相连,数据只存储在叶子结点,并且数据和节点一样多
  用双向链表解决范围查找。
  用联合索引按照最左原则,比如userid+name+age,以最左的userid建树,查找时也是  用userid查找,如果是用name+age查找,则会遍历索引,不走上面只从每个数据本身  查找,因为没有userid。
5、常用简单算法概述
二分法:在有序数组中查找某一特定元素的搜索算法,每次都从中间元素开始比较
选择排序:时间 O(n^2) 空间O(1)
从0到末尾找一个最小的与a[0]交换位置,然后从1到最后。。。。
冒泡:从0到N-1相邻的元素比较,大于则交换位置;然后0到N-2重复操...
可以优化,即第一遍遍历未发生交换则直接跳出循环。
插入排序:时间 O(n^2) 空间O(1) 位置不正确的元素较少。
0位置先保留,然后用临时变量temp接收1的值,判断temp和0位置大小关系,如果小,则将0的值放在1位置,
temp放在0位置;判断2位置的值和0、1的关系,如果2的值最小,则现将1的值放在2,然后把0的值放在1,
temp的放在0。然后往后重复直到最后一个元素。
用处:待排序的树都离正确位置不远,元素不多,代排元素不多。
插入排序优化为希尔排序:
先分组,步长为: 3s+1 (s= 0 ,1,2,3...)
比如十11个元素的数组,步长10:排列0和10 ,其余不变
步长 7:排列 0和7,1和8,2和9,3和10
步长 4:排列 0,4,8 | 1,5,9 | 2,6,10
步长 1:逐一排列(即普通的插入排序)
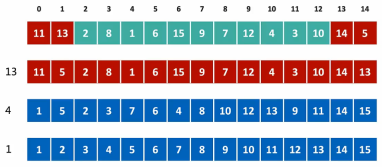
分治算法:(归并和快排):
归并分高低(下标):局部有序 ——整体有序 ;时间(O(nlogn)
2个函数:void fun(T *a, low, middle high)
Void merger ( T*a ,low ,high )
{ low == high return; 分组递归fun }
快排分左右(值):时间 最优==平均(O(nlogn)) 最差(O(n^2))
选定a[ low ] 分界左右——局部细化
2个函数:void fun(T *a, int low,int high)
Void fast(T *a, int left,int right)
{left == right return left; int pv = fun() ; return left}
优化:当小数组的个数为10-15个数时切换为插入排序。
多数重复时:三取样切分(一次取三个数去取中间数为基准值)
迪杰斯特拉:三项切分法,it i gt
(it>i) 交换i和it,it++ ;(i>gt)交换i和gt,gt--; 否则 i++
快速三项切分:
双端快速排序:选取两个基准点 it i g gt


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









