







 本文探讨了HashMap的工作原理,包括哈希函数、冲突解决、Rehash机制及线程安全问题。并通过对比ConcurrentHashMap,阐述其锁分段技术、高性能读写策略以及在并发场景下的优势。
本文探讨了HashMap的工作原理,包括哈希函数、冲突解决、Rehash机制及线程安全问题。并通过对比ConcurrentHashMap,阐述其锁分段技术、高性能读写策略以及在并发场景下的优势。
1.HashMap
HashMap用于存储键值对的集合,这些键值对分散存储在一个数组中。
1.put方法:需要一个哈希函数,来确定键值对插入的位置。可能会出现冲突!
怎么办?我们可以利用链表来解决,数组的每一个元素不止是一个键值对,也是一个链表的头结点。
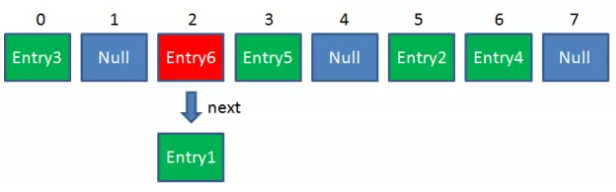
2.Get方法:由于有冲突,同一位置可能匹配到多个Entry,这时候就需要顺着头结点,一个一个向下来查找。
3.默认的初始长度?为什么?
答:16。每次自动扩展或是手动初始化时,长度必须是2的幂
如何实现一个尽量均匀分布的Hash函数呢?我们通过利用Key的HashCode值来做某种运算:进行位运算,有如下的公式(Length是HashMap的长度):
index = HashCode(Key) & (Length - 1) 。Hash算法最终得到的index结果,完全取决于Key的Hashcode值的最后几位。当HashMap长度为10的时候,有些index结果的出现几率会更大,而有些index结果永远不会出现(比如0111)
2.Rehash
hashMap的容量有限,经过多次元素插入,使得冲突逐渐提高,这是,我们进行扩展长度,即Resize

步骤:



1..高并发下,为什么HashMap可能会出现死锁?
假设一个hashMAp已经到了Resize的临界点,此时有两个线程AB,在同一时刻对HashMap进行put操作,链表可能会出现环形
此时在使用get,由于带有环形链表,所以程序会进入死循环!
为了杜绝这种情况的发生,我们通常使用另一个集合类ConcurentHashMap,这个集合兼顾了线程安全和性能。
3.如何判断链表有环?
方法一:深度遍历节点,记录下来,发现有重复的,即是有环
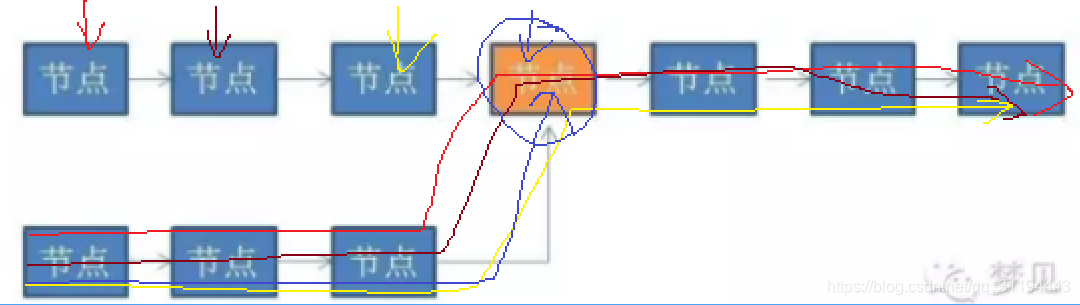
方法二:创建两个指针1和2(在java里就是两个对象引用),同时指向这个链表的头节点。然后开始一个大循环,在循环体中,让指针1每次向下移动一个节点,让指针2每次向下移动两个节点,然后比较两个指针指向的节点是否相同。如果相同,则判断出链表有环,如果不同,则继续下一次循环。
假设从链表头节点到入环点的距离是D,链表的环长是S。那么循环会进行S次(为什么是S次,有心的同学可以自己揣摩下),可以简单理解为O(N)。除了两个指针以外,没有使用任何额外存储空间,所以空间复杂度是O(1)。
4.引申问题:
Q1:判断两个单向链表是否相交,如果相交,求出交点。
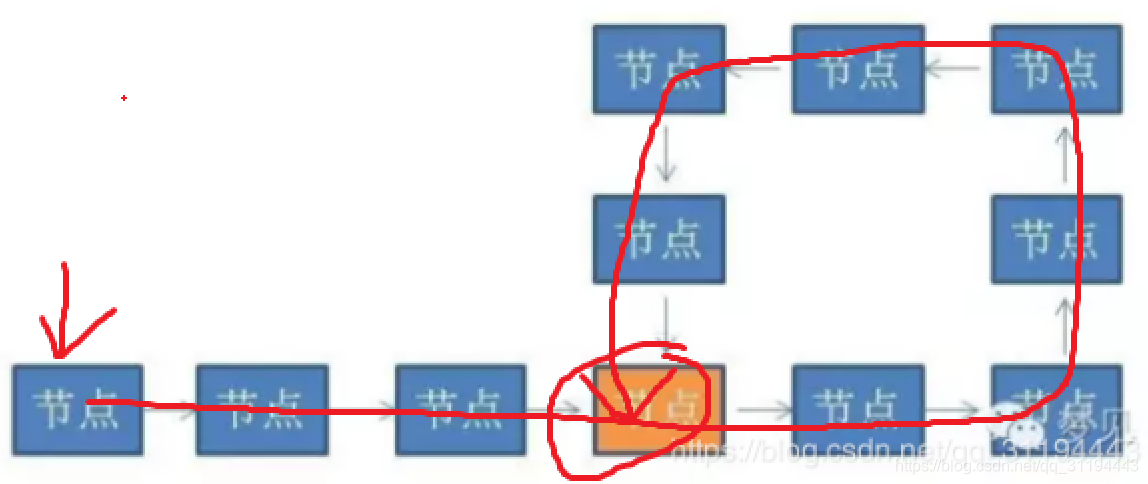
Q2:在一个有环链表中,如何找出链表的入环点?
设置一个指针,走一圈,记录每个节点,出现重复的,即是入环点
5.什么是ConcurrentHashMap?
首先,HashMap不是线程安全的,在并发插入元素的时候,有可能出现带环链表,让下一次读操作出现死循环。
1.并发场景下,ConcurrentHaspMap是怎么保证线程安全的?怎么实现高性能读写?
想要避免HashMap的线程安全问题,可以改用HashTable或者Collections.synchronizedMap
但是两者性能都不高,无论是读还是写,它们都会给整个集合加锁,导致同一时间的其他操作为之阻塞。
这时候,兼顾安全和效率,concurrentHashMap应运而生
2.Segment
Segment本身就相当于一个HashMap对象。同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。
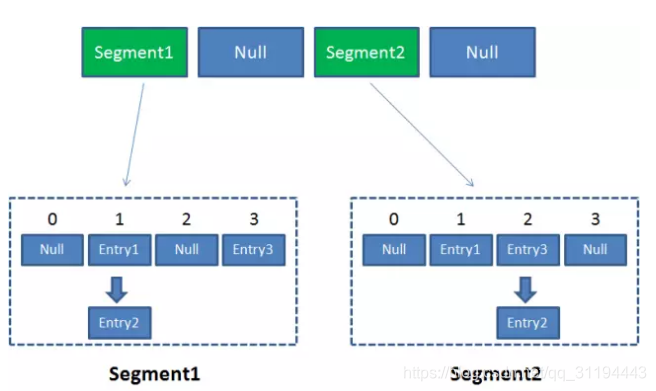
可以说,ConcurrentHashMap是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。这样的二级结构,和数据库的水平拆分有些相似。
3.concurrentHashMap采用了锁分段技术,每一个segment就好比一个自治区,读写高度自治,segment之间互不影响。
Case1:不同Segment的并发写入:可以
Case2:同一Segment的一写一读:可以
Case3:同一Segment的并发写入:上锁,不能并发写入,会阻塞
4.concurrentHashMap的读写详细过程:
ConcurrentHashMap在对Key求Hash值的时候,为了实现Segment均匀分布,进行了两次Hash。
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
Put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
6.ConcurrentHashMap的Size方法
ConcurrentHashMap的Size方法是一个嵌套循环,大体逻辑如下:
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
为了尽量不锁住所有Segment,首先乐观地假设Size过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有Segment保证强一致性。

















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









