







 本文介绍如何配置Hive以实现与HDFS和YARN的集成,并通过不同方式运行Hive查询。此外,还提供了在Linux环境下安装MySQL并解决远程访问问题的方法。
本文介绍如何配置Hive以实现与HDFS和YARN的集成,并通过不同方式运行Hive查询。此外,还提供了在Linux环境下安装MySQL并解决远程访问问题的方法。
配置
conf中
vi hive-site.xml
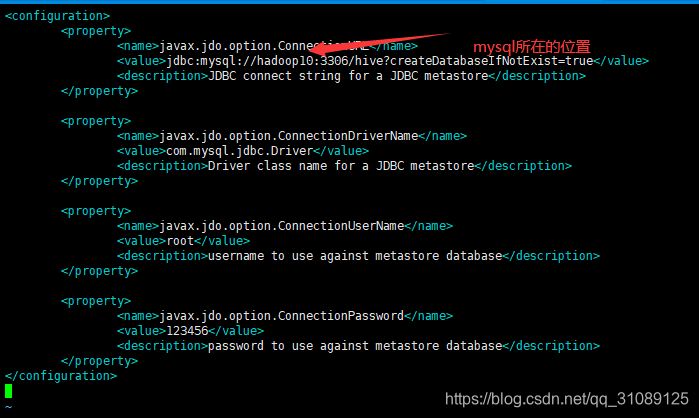
确保hive成功启动,还需要将hdfs和yarn打开。
分布式数据库,多数机器可以在hdfs上创建数据库
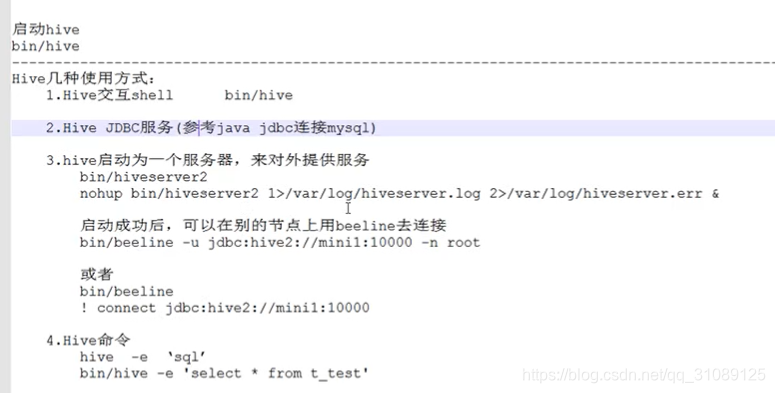
客户端与服务器
1、前台运行
(服务端)执行某个hive处于bin/hiveserver2
(客户端)另一个电脑 !connect jdbc:hive2://hadoop15:10000 (hadoop15是传集群的那台计算机)
2、后台运行
nohub bin/hiveserver2 1>/dev/null 2>&1 & (1代表正确的,2代表错误。信息都写入黑洞)
脚本化运行
创建xx.sh文件,在文件中写入多条hive语句,批量运行
法一:

运行语句:sh xx.sh
法二:
创建test.hql

运行语句:hive -f test.hql
select 的内容在服务端可以看到
三、交互式运行
进入hive中写语句
关于mysql
Linux安装MySQL-5.6.24-1.linux_glibc2.5.x86_64.rpm-bundle.tar
出现以下问题
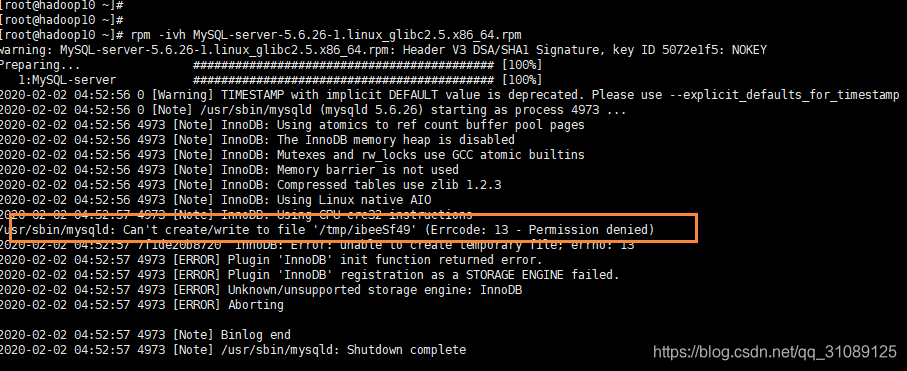
执行 chmod 777 /tmp
即可
给root用户授予从任何机器上登陆mysql服务器的权限:
mysql> grant all privileges on *.* to 'root'@'%' identified by '你的密码' with grant option;
mysql> flush privileges;
注意点:要让mysql可以远程登录访问
最直接测试方法:从windows上用Navicat去连接,能连,则可以,不能连,则要去mysql的机器上用命令行客户端进行授权:

















 1627
1627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









