




背景
基于此,我们发布了《中文大模型基准测评2024年10月报告》,在AI大模型发展的巨大浪潮中,通过多维度综合性测评,对国内外大模型发展现状进行观察与思考。
自2022年11月30日ChatGPT发布以来,AI大模型在全球范围内掀起了有史以来规模最大的人工智能浪潮。国内学术和产业界在过去一年半也有了实质性的突破。大致可以分为四个阶段,即准备期(ChatGPT发布后国内产学研迅速形成大模型共识)、成长期(国内大模型数量和质量开始逐渐增长)、爆发期(各行各业开源闭源大模型层出不穷,形成百模大战的竞争态势)、繁荣期(更多模态能力的延伸和应用)。

2. 2024年值得关注的中文大模型全景图
截止目前为止,国内已发布开源、闭源通用大模型及行业大模型已有上百个,SuperCLUE梳理了2024年值得关注的大模型全景图。

AI聚合体验:https://www.aichatgpt.net/
3. 2023-2024年度国内外大模型技术发展趋势
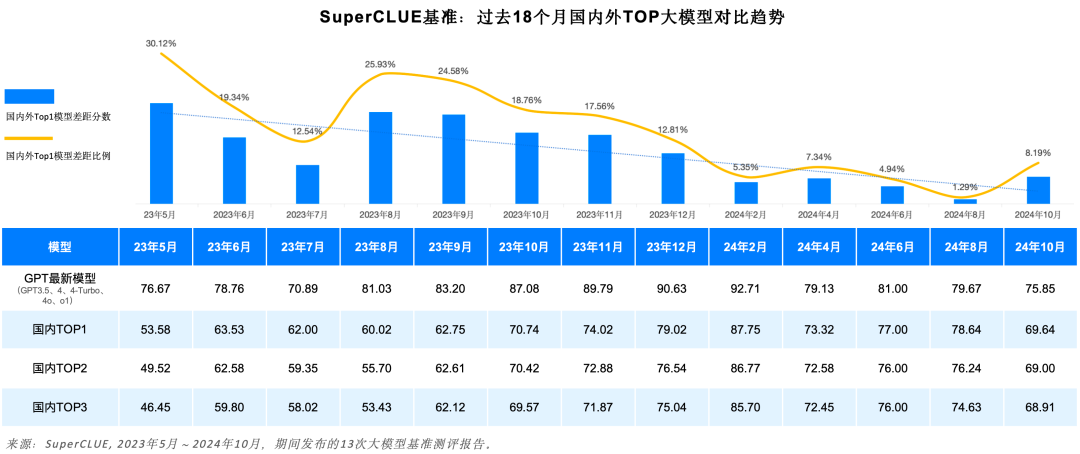
2023年5月至今,国内外大模型能力持续发展。其中GPT系列模型为代表的海外最好模型经过了从GPT3.5、GPT4、GPT4-Turbo、GPT4o、o1的多个版本的迭代升级。国内模型也经历了波澜壮阔的18个月的迭代周期,其中Top1的模型经历了10次易主,不断提升国内模型的最强战力。
总体趋势上,国内外第一梯队大模型在中文领域的通用能力差距在持续缩小,从2023年5月的30.12%的差距,缩小至2024年8月的1.29%。不过随着o1的发布,差距再次拉大到8.19%。
二、SuperCLUE通用能力测评
1. 中文大模型基准SuperCLUE介绍
中文语言理解测评基准CLUE(The Chinese Language Understanding Evaluation)是致力于科学、客观、中立的语言模型评测基准,发起于2019年。陆续推出CLUE、FewCLUE、KgCLUE、DataCLUE等广为引用的测评基准。
SuperCLUE是大模型时代CLUE基准的发展和延续。聚焦于通用大模型的综合性测评。SuperCLUE根据多年的测评经验,基于通用大模型在学术、产业与用户侧的广泛应用,构建了多层次、多维度的综合性测评基准。
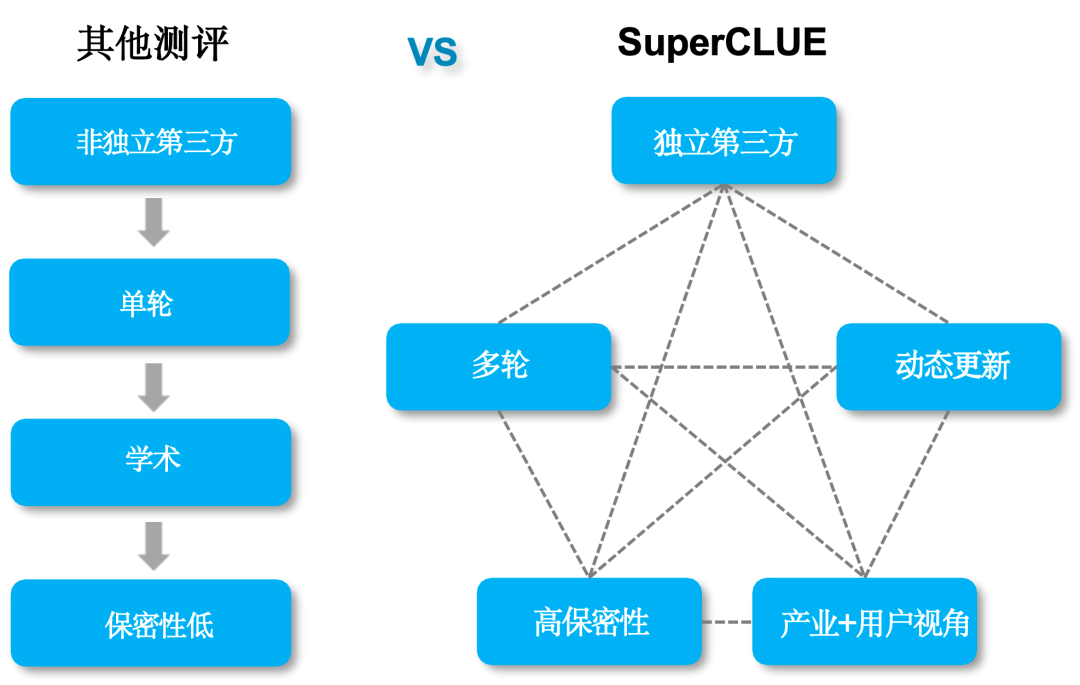
1) 独立第三方测评,非大模型方主导
随着国内外大模型的竞争日益激烈,模型开发方主导的评测可能存在偏向自家产品的风险。与之形成鲜明对比的是,SuperCLUE作为一个完全独立的第三方评测机构,承诺提供无偏倚的客观评测结果。SuperCLUE采用先进的自动化评测技术,有效消除人为因素带来的不确定性,确保每一项评测都公正无私。
2) 测评方式与真实用户体验目标一致
不同于传统测评通过选择题形式的测评,SuperCLUE目标是与真实用户体验目标保持一致,所以纳入了开放主观问题的测评。通过多维度多视角多层次的评测体系以及对话的形式,模拟大模型的应用场景,真实有效的考察模型生成能力。
3) “Live”更新,测评体系/方法与时俱进
不同于传统学术领域的评测,SuperCLUE根据全球的大模型技术发展趋势,不断升级迭代测评体系、测评维度和方法,以保证尽可能精准量化大模型的技术演进程度。并且每次测评集均为原创的新题,且保证题目的高保密性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









