






 本文深入探讨Kafka的生产者消费者模式、设计架构、核心概念及其高级特性,包括事务处理和零拷贝机制。同时,提供了Kafka的安装、启动指南及应用场景,适合初学者和进阶读者。
本文深入探讨Kafka的生产者消费者模式、设计架构、核心概念及其高级特性,包括事务处理和零拷贝机制。同时,提供了Kafka的安装、启动指南及应用场景,适合初学者和进阶读者。
Kafka学习笔记
1.生产者消费者模式
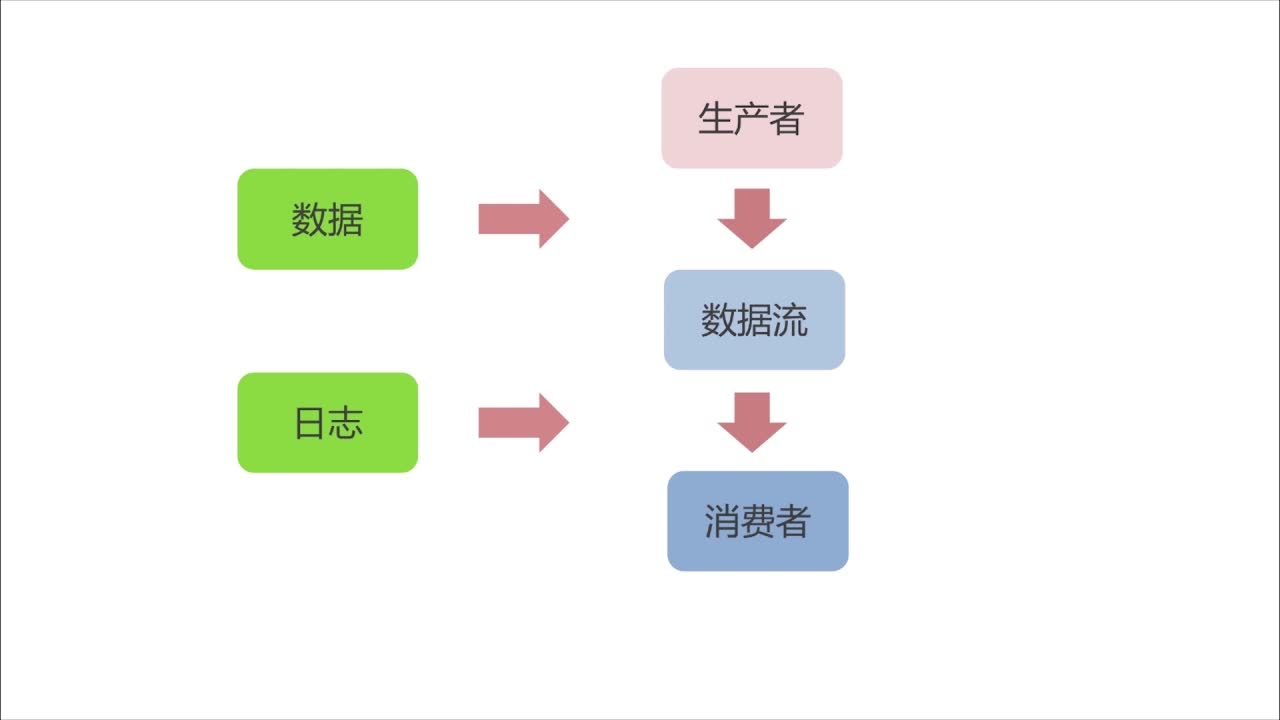
2.Kafka的设计和架构
1.Kafka基本概念
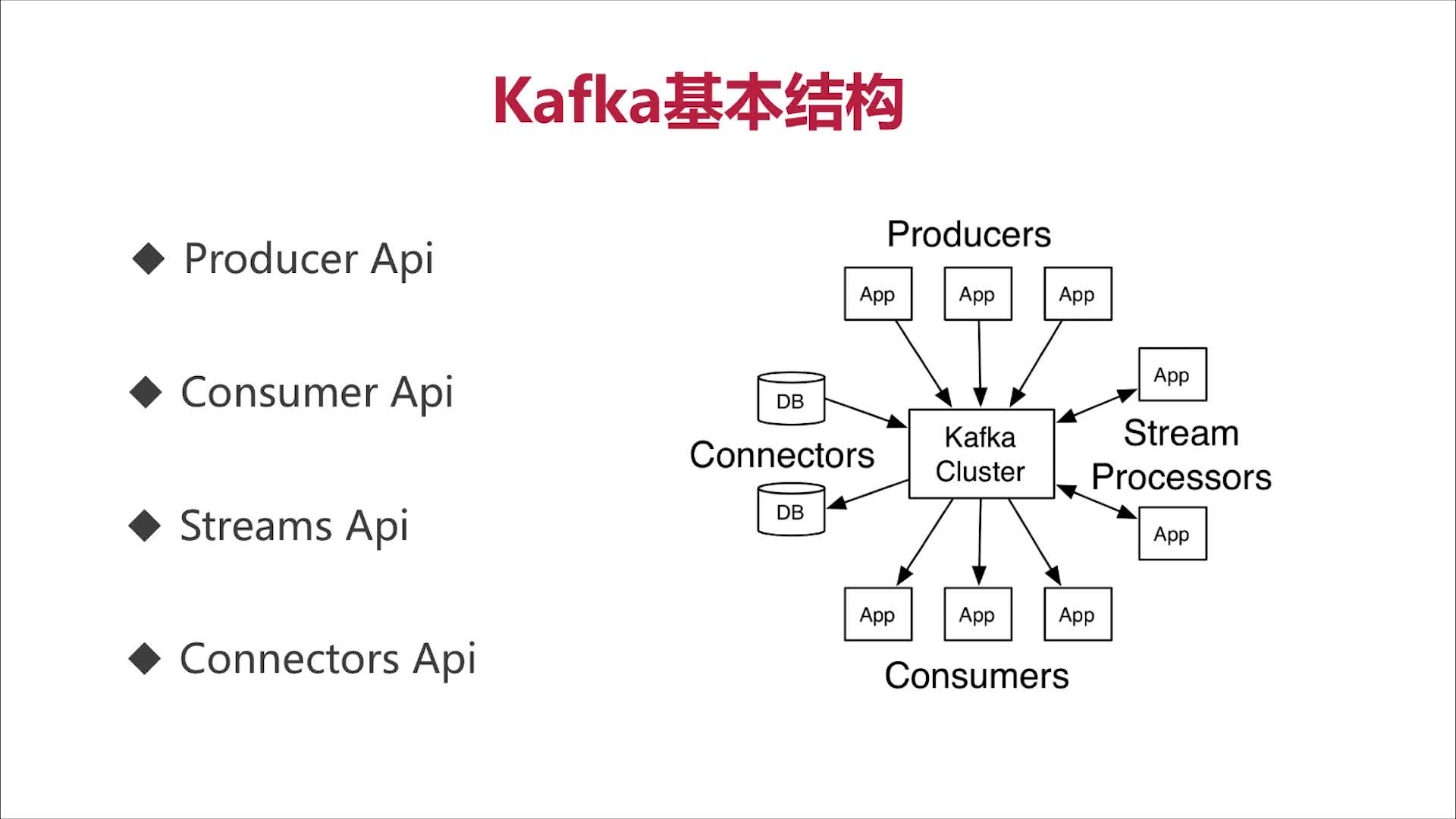
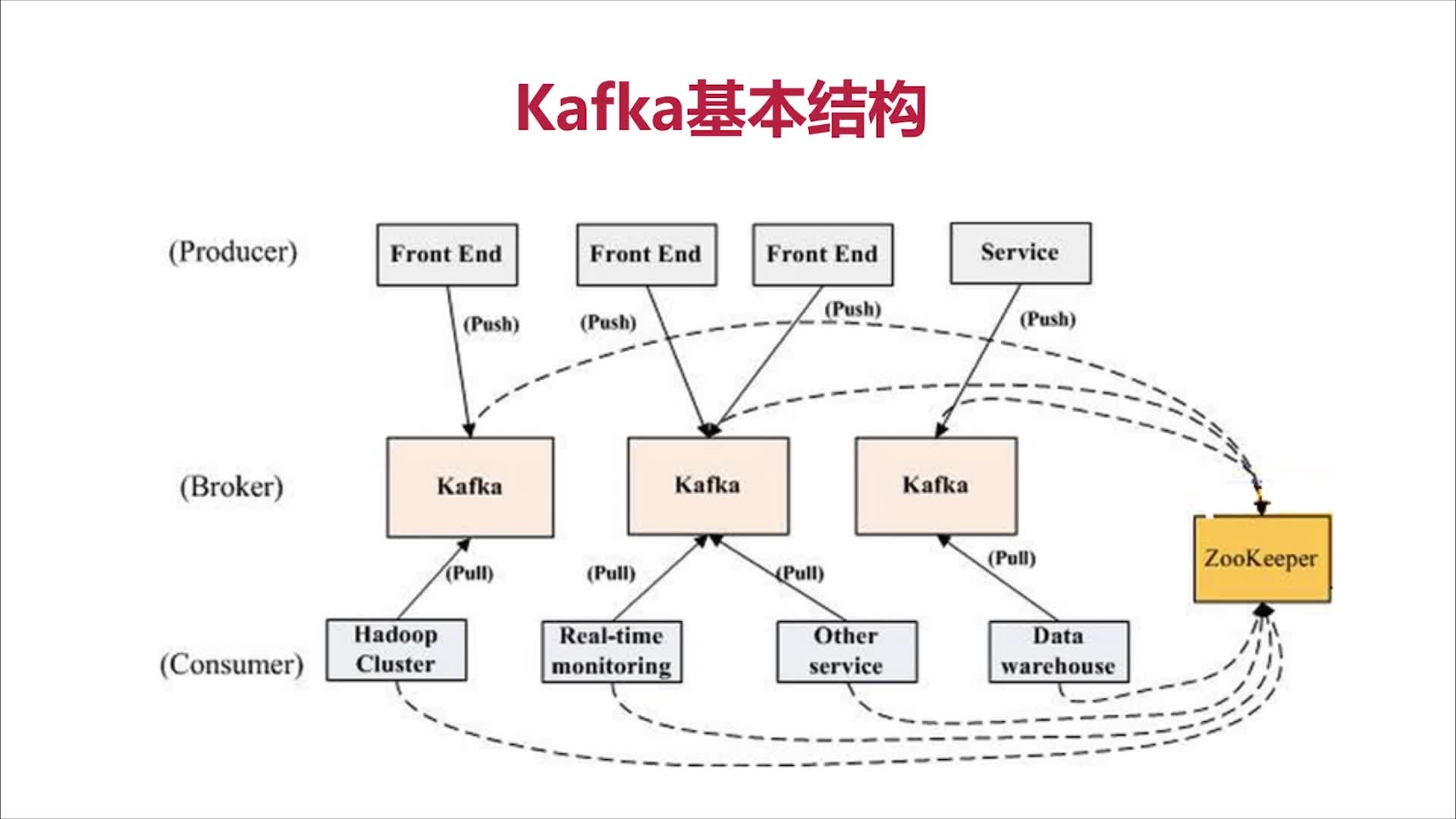
Producer:消息和数据的生产者,向Kafka的一个topic发布消息的进程/代码/服务
Consumer:消息和数据的消费者,订阅数据(Topic)并且处理其发布的消息的进程/代码/服务
Consumer Group:逻辑概念,对于同一个topic,会广播给不同的group,一个group中,只有一个consumer可以消费该消息
Broker:物理概念,Kafka集群中的每个Kafka节点
Topic:逻辑概念,Kafka消息的类别,对数据进行区分、隔离
Partition:物理概念,Kafka下数据存储的基本单元。一个topic数据,会被分散存储到多个Partition,每一个Partition是有序的
Replication(副本、备份):同一个Partition可能会有多个Replication,多个Replication之间数据是一样的
2.Kafka概念延伸
Replication特点:
Replication的基本单位是Topic的Partition
所有读和写都从Leader进,Followers只作备份
Follower必须能够及时复制Leader的数据
当集群中有Broker挂掉的情况,系统可以主动地使Replication提供服务
系统默认设置每一个Topic的Replication系数为1,可以在创建Topic时单独设置
每一个Topic被切分为多个Partitions(Partition属于消费者存储的基本单位)
消费者数目小于或等于Partition的数目(多个消费者若消费同个Partition会出现数据错误,所有Kafka如此设计)
Broker Group中的每一个Broker保存Topic的一个或多个Partitions
3.Kafka的基本结构
kafka消息结构:
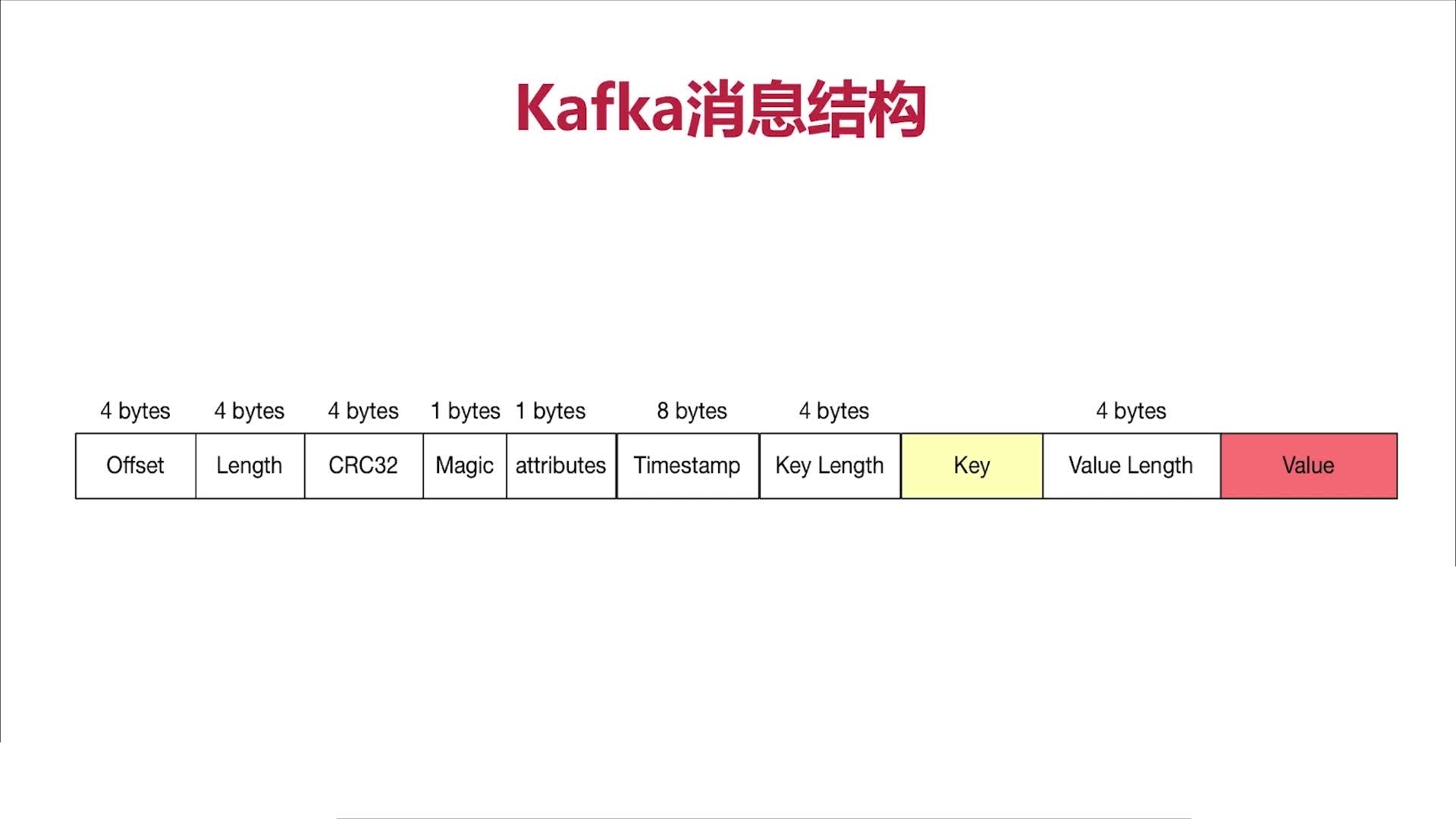
Offset: 消息的偏移量
Length: 消息的长度
CRC32 : 消息校验字段,校验信息的完整性
Magic: 用于判断该消息是不是kafka消息
attributes: 可选字段,存放当前消息的属性
4.Kafka的特点
分布式:多分区、多副本、多订阅者、基于Zookeeper调度
高性能:高吞吐量、低延迟、高并发、时间复杂度为O(1)
持久性与扩展性:数据可持久化、容错性、支持在线水平扩展、消息自动平衡
3.Kafka应用场景及操作
1.Kafka应用场景
消息队列
行为跟踪
元信息监控
日志收集
流处理
2.Kafka安装与启动(单机版)
官方文档:http://kafka.apache.org/quickstart#quickstart_createtopic
解压tgz包,2.11-2.0.0版本自带Zookeeper
tar -xzf kafka_2.11-2.0.0.tgz cd kafka_2.11-2.0.0
用SecureCRT克隆会话,方便查看日志,启动Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
克隆会话,启动Kafka
bin/kafka-server-start.sh config/server.properties
创建Topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
查看Topic
bin/kafka-topics.sh --list --zookeeper localhost:2181
启动生产者
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
启动消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
用jps命令查看已经启动的Java进程,查看服务是否正确
root@ubuntu:~/kafka/kafka_2.11-2.0.0# jps 43427 ConsoleConsumer 42291 ConsoleProducer 41043 QuorumPeerMain 43719 Jps 41356 Kafka
在Producer输入文字,在Consumer中可以即时收到
Producer:
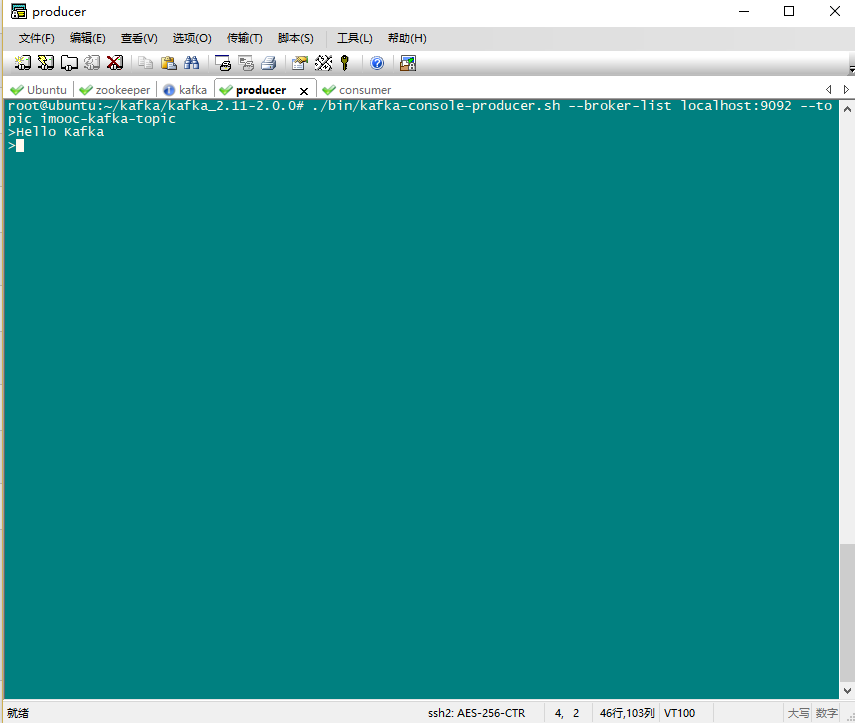
Consumer:

3.Kafka安装与启动(集群版)
https://www.cnblogs.com/luotianshuai/p/5206662.html#autoid-0-2-0
4.Java测试连接Kafka单机版和Kafka集群的代码
https://github.com/cjy513203427/KafkaExample
4.Kafka高级特性
1.Kafka消息事务
事务保证一避免僵尸实例
每个事务Producer分配一个transactional.id ,在进程重新启动时能 够识别相同的Producer实例
Kafka增加了一个与transactional.id相关的epoch ,存储每个 transactional.id 内部元数据
—旦epoch被触发,任何具有相同的transactional.id和更旧的 epocli的Producer被视为僵尸,Kafka会拒绝来自这些Procedure 的后续事务性写入
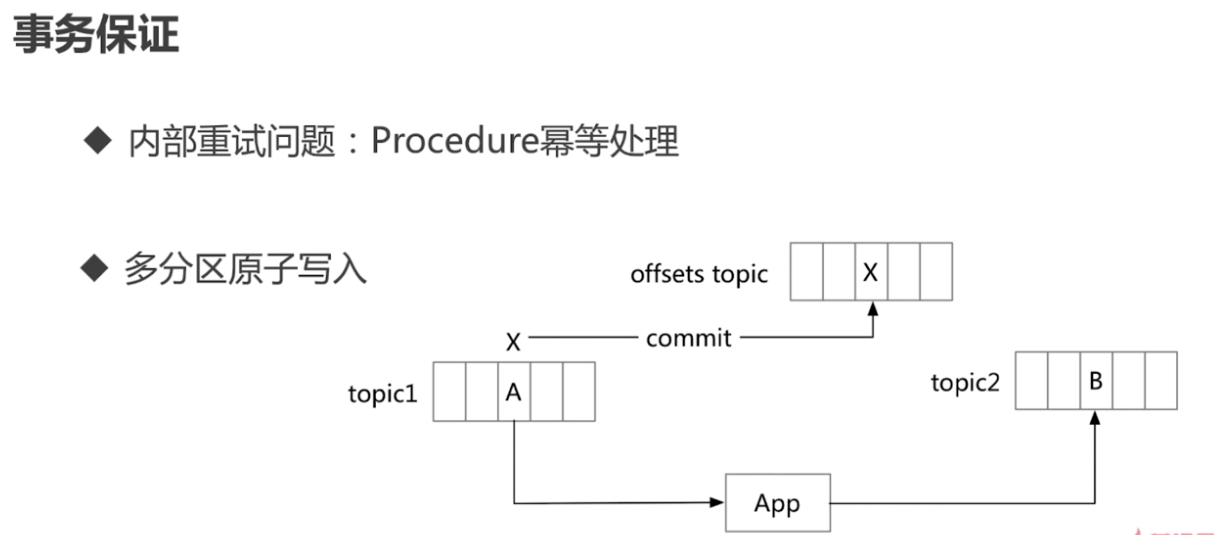
一个消息在该偏移量被提交时,被视为"消息被消费"
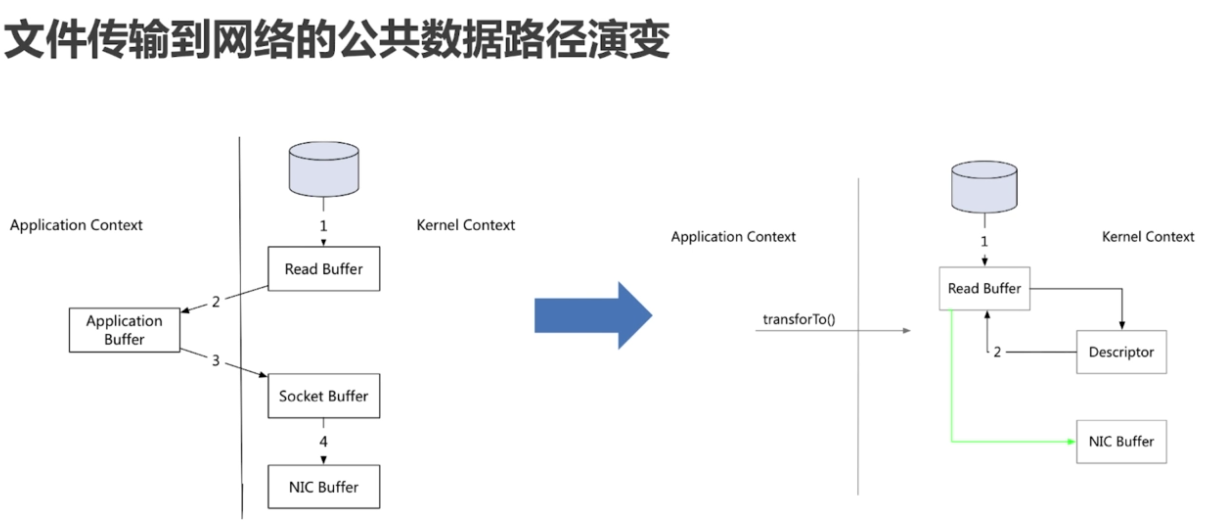
2.零拷贝
内核空间和用户空间的交互拷贝次数为0,不是不拷贝

















 4810
4810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









