









JSON
定义
JSON(JavaScript Object Notation)
是一种轻量级的数据交换格式
作用
数据标记,存储,传输
特点
1.
读写速度快
2.
解析简单
3.
轻量级
4.
独立于语言,平台
5.
具有自我描叙性
JSON
解析
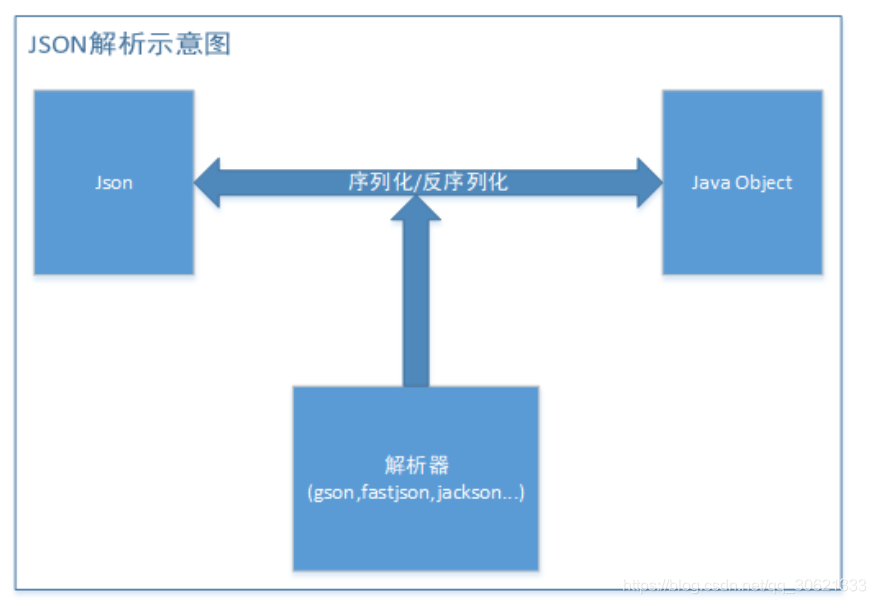
语法
JSON
建构于两种结构:
“
名称
/
值
”
对的集合(
A collection of name/value pairs
)。不同的语言中,它被理解为对象
(
object
),纪录(
record
),结构(
struct
),字典(
dictionary
),哈希表(
hash table
),
有键列表(
keyed list
),或者关联数组 (
associative array
)。
值的有序列表(
An ordered list of values
)。在大部分语言中,它被理解为数组(
array
)。
这些都是常见的数据结构。事实上大部分现代计算机语言都以某种形式支持它们。这使得一种数据格式
在同样基于这些结构的编程语言之间交换成为可能。
JSON
具有以下这些形式:
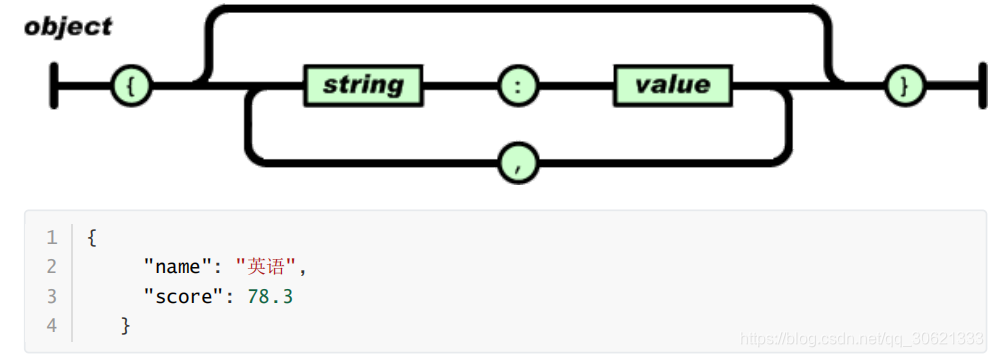
对象是一个无序的
“‘
名称
/
值
’
对
”
集合。一个对象以
“{”
(左括号)开始,
“}”
(右括号)结束。每个
“
名称
”
后
跟一个
“:”
(冒号);
“‘
名称
/
值
’
对
”
之间使用
“,”
(逗号)分隔。
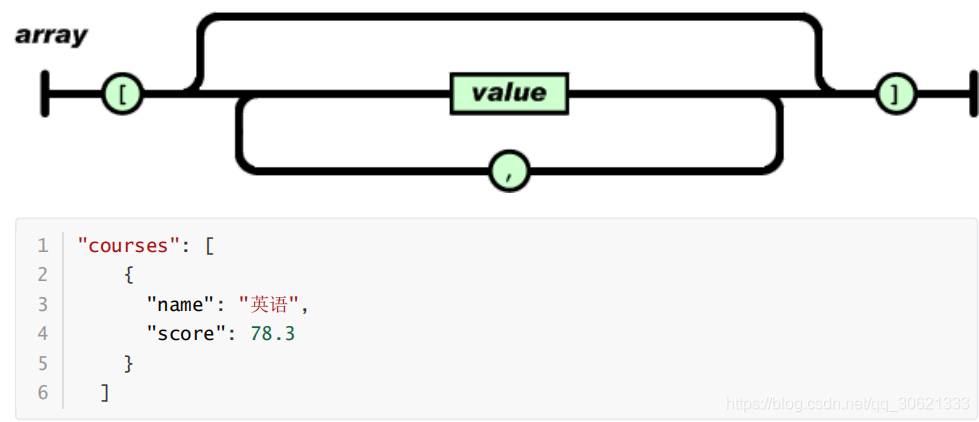
数组是值(
value
)的有序集合。一个数组以
“[”
(左中括号)开始,
“]”
(右中括号)结束。值之间使用
“,”
(逗号)分隔。
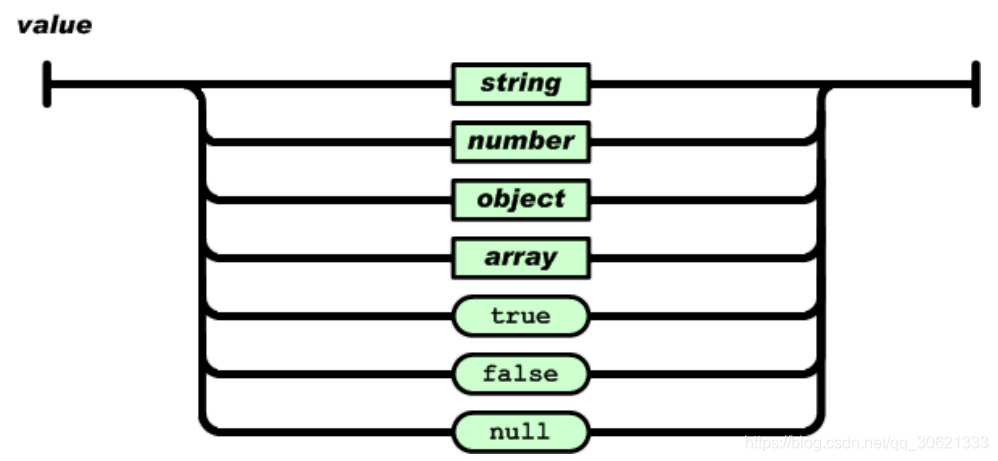
值(
value
)可以是双引号括起来的字符串(
string
)、数值
(number)
、
true
、
false
、
null
、对象
(
object
)或者数组(
array
)。这些结构可以嵌套。
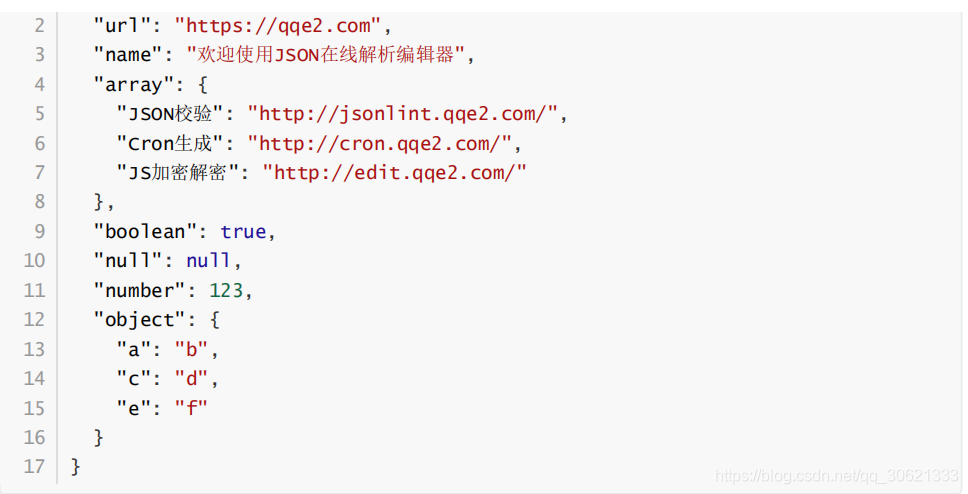
字符串(
string
)是由双引号包围的任意数量
Unicode
字符的集合,使用反斜线转义。一个字符
(
character
)即一个单独的字符串(
character string
)。
字符串(
string
)与
C
或者
Java
的字符串非常相似。
数值(
number
)也与
C
或者
Java
的数值非常相似。除去未曾使用的八进制与十六进制格式。除去一些编
码细节。


JSON
解析方式
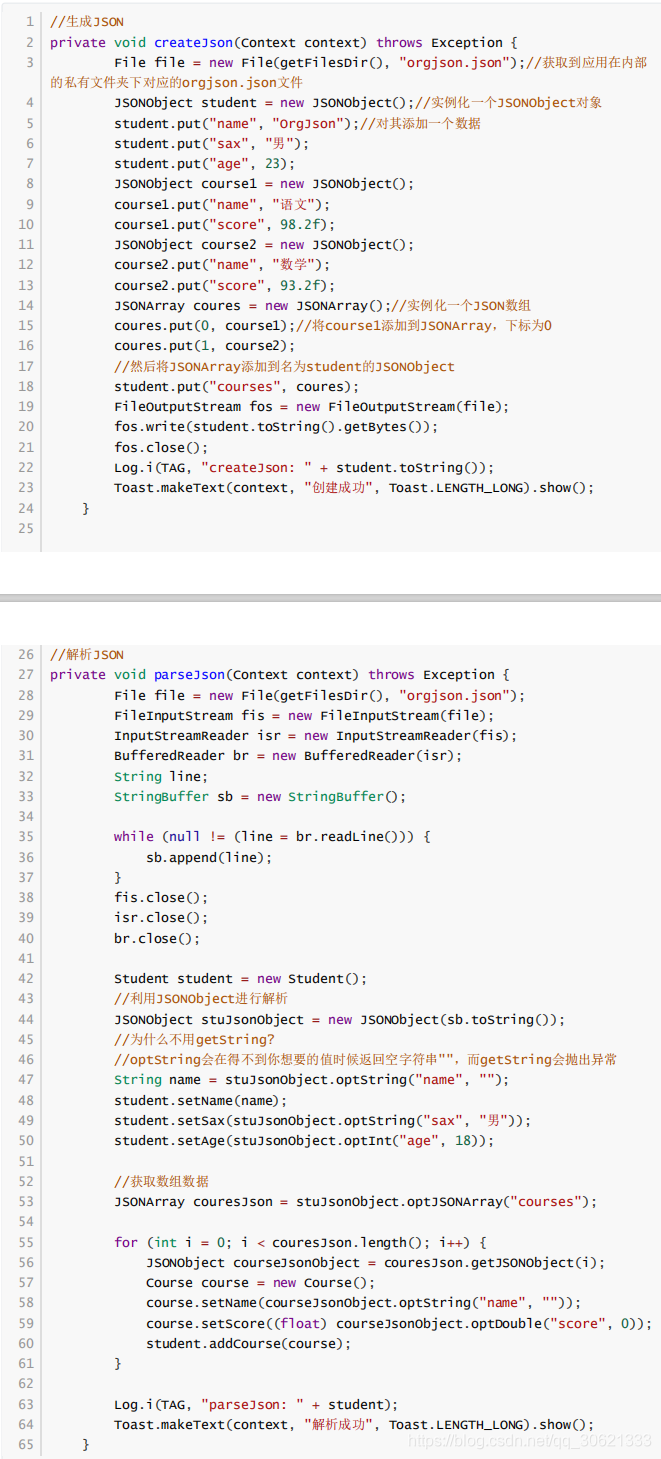
Android Studio
自带
org.json
解析
-
解析原理:基于文档驱动,需要把全部文件读入到内存中,然后遍历所有数据,根据需要检索想要的数据
-
具体使用
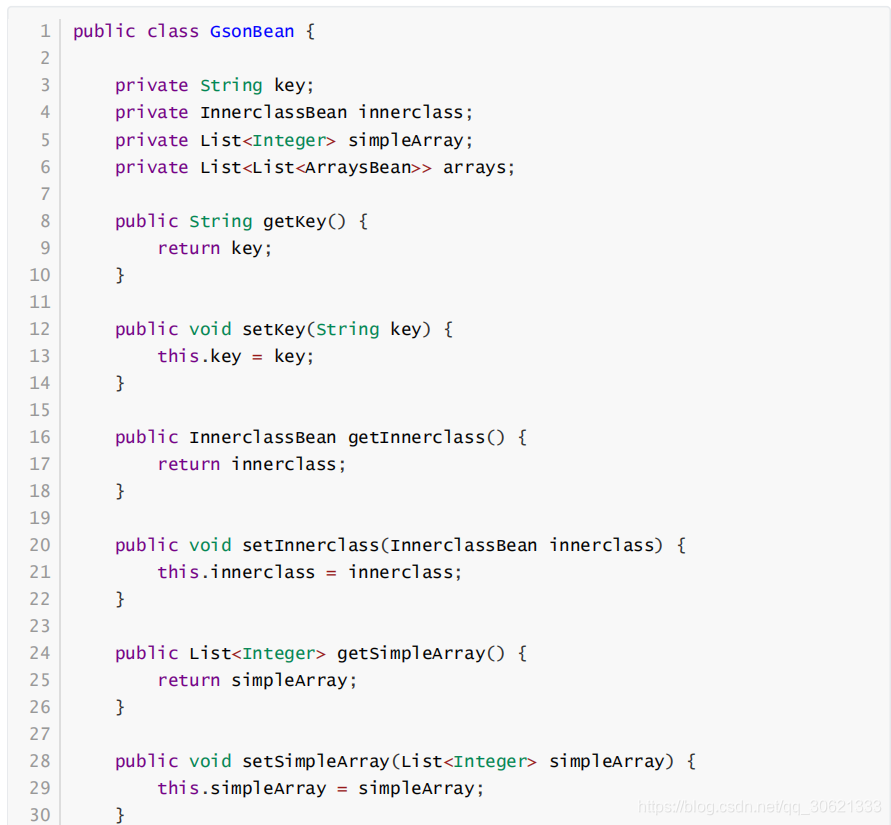
Gson
解析
解析原理:基于事件驱动
解析流程:根据所需取的数据 建立
1
个对应于
JSON
数据的
JavaBean
类,即可通过简单操作解析出
所需数据
Gson
不要求
JavaBean
类里面的属性一定全部和
JSON
数据里的所有
key
相同,可以按需取数据
具体实现


转化成
JavaBean

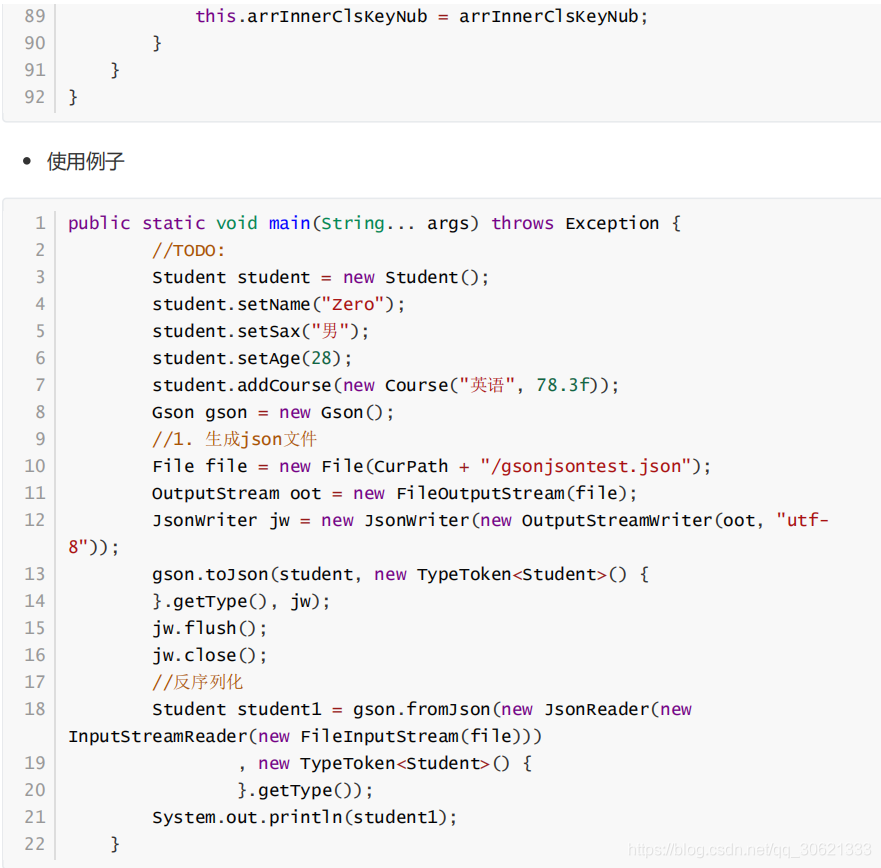
Jackson
解析
- 解析原理:基于事件驱动
- 解析过程:
-
类似 GSON ,先创建 1 个对应于 JSON 数据的 JavaBean 类,再通过简单操作即可解析
-
与 Gson 解析不同的是: GSON 可按需解析,即创建的 JavaBean 类不一定完全涵盖所要解析的 JSON 数据,按需创建属性;但 Jackson 解析对应的 JavaBean 必须把 Json 数据里面的所有 key都有所对应,即必须把 JSON 内的数据所有解析出来,无法按需解析
导入Jackson依赖

使用
Jackson
解析

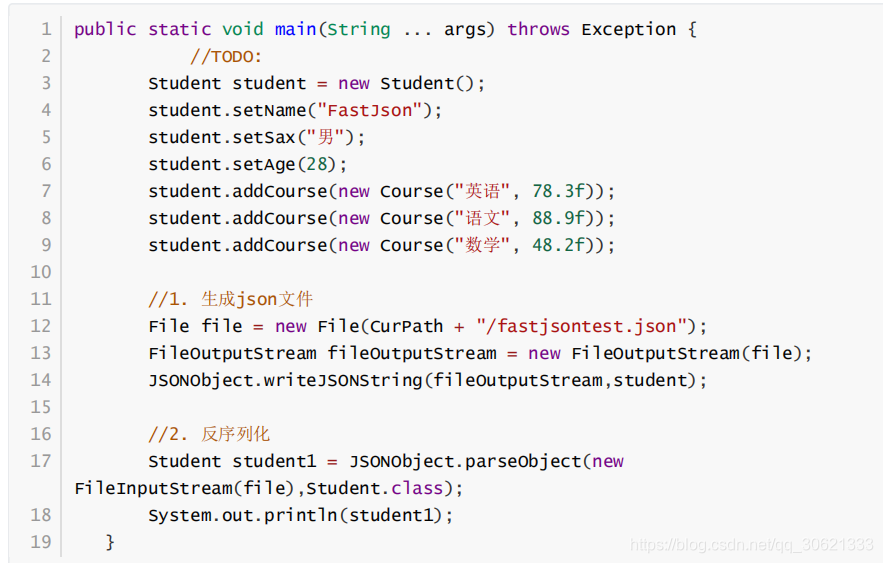
Fastjson
解析
导入
Fastjson
依赖
implementation
'com.alibaba:fastjson:1.2.57'
使用
Fastjson
解析
自定义一个
JSON
解析库
编写一个
JSON
解析器实际上就是一个方法,它的输入是一个表示
JSON
的字符串,输出是结构化的对应
到语言本身的数据结构
一般来说,解析过程包括词法分析和语法分析两个阶段。词法分析阶段的目标是按照构词规则将
JSON
字符串解析成
Token
流,比如有如下的
JSON
字符串:
{
"key"
:
"value"
,
}
结果词法分析后,得到一组
Token
,如下:
{key : value, }
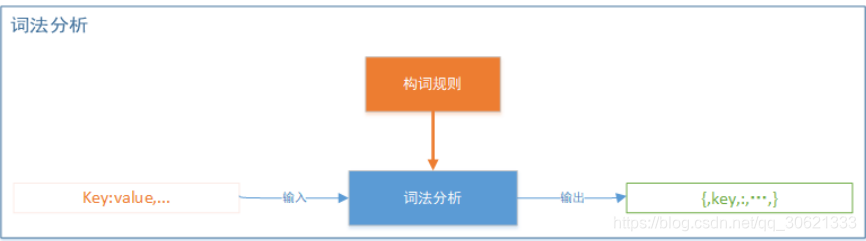
词法分析解析出
Token
序列后,接下来要进行语法分析。语法分析的目的是根据
JSON
文法检查上面
Token
序列所构成的
JSON
结构是否合法。比如
JSON
文法要求非空
JSON
对象以键值对的形式出现,
形如
object = {string : value}
。如果传入了一个格式错误的字符串,比如
{
"key"
,
"value"
}
那么在语法分析阶段,语法分析器分析完
Token name
后,认为它是一个符合规则的
Token
,并且认为
它是一个键。接下来,语法分析器读取下一个
Token
,期望这个
Token
是
:
。但当它读取了这个
Token
发现这个 Token
是
,
,并非其期望的
:
,于是文法分析器就会报错误。
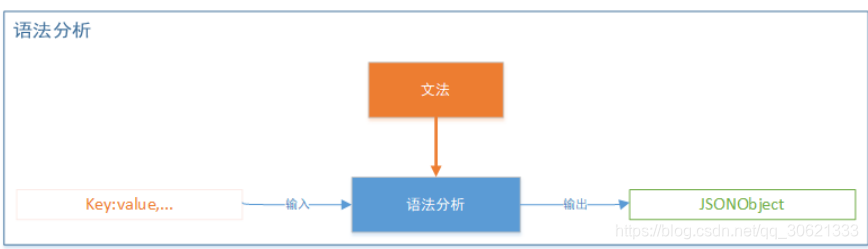
JSON
解析分析小结
1.
通过词法分析是将字符串解析成一组
Token
序列
2.
然后通过语法分析检查输入的
Token
序列所构成的
JSON
格式是否合法
词法分析
按照
“
构词规则
”
将
JSON
字符串解析成
Token
流。请注意双引号引起来词
–
构词规则,所谓构词规则是
指词法分析模块在将字符串解析成
Token
时所参考的规则。在
JSON
中,构词规则对应于几种数据类
型,当词法解析器读入某个词,且这个词类型符合
JSON
所规定的数据类型时,词法分析器认为这个词
符合构词规则,就会生成相应的
Token
。这里我们可以参考
http://www.json.org/
对
JSON
的定义,罗
列一下
JSON
所规定的数据类型:
- BEGIN_OBJECT({)
- END_OBJECT(})
- BEGIN_ARRAY([)
- END_ARRAY(])
- NULL(null)
- NUMBER(数字)
- STRING(字符串)
- BOOLEAN(true/false)
- SEP_COLON(:)
- SEP_COMMA(,)
当词法分析器读取的词是上面类型中的一种时,即可将其解析成一个
Token
。我们可以定义一个枚举类
来表示上面的数据类型,如下:
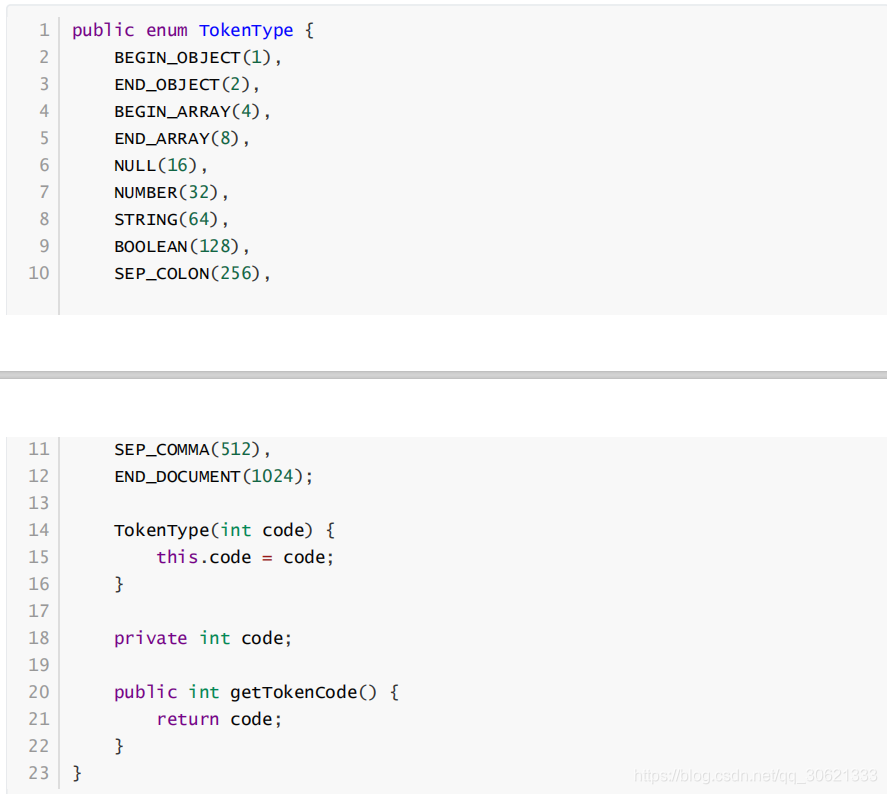
在解析过程中,仅有
TokenType
类型还不行。我们除了要将某个词的类型保存起来,还需要保存这个
词的字面量。所以,所以这里还需要定义一个
Token
类。用于封装词类型和字面量,如下:

定义好了
Token
类,接下来再来定义一个读取字符串的类
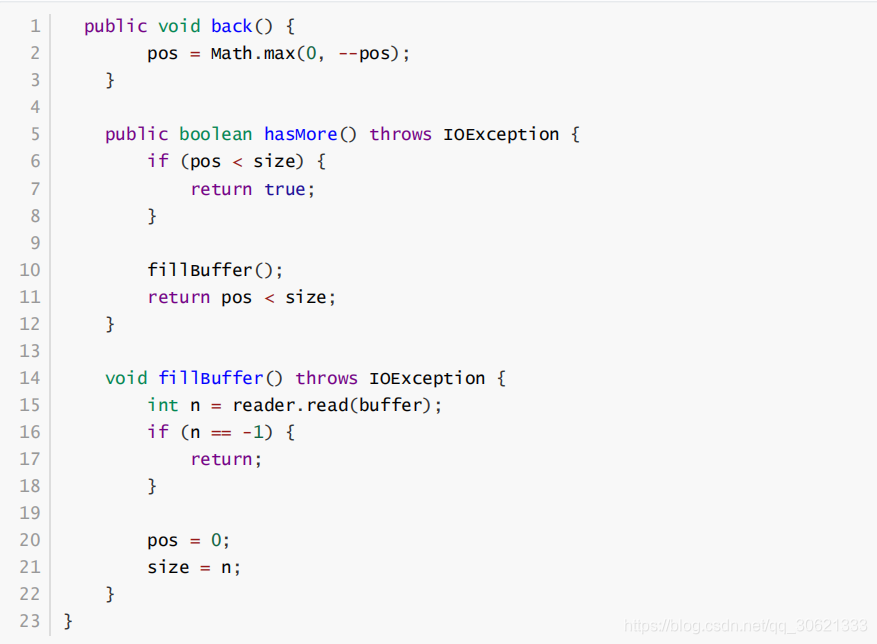
有了
TokenType
、
Token
和
CharReader
这三个辅助类,接下来我们就可以实现词法解析器了

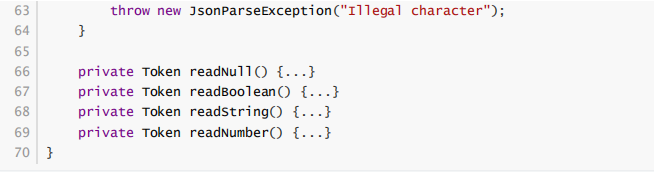
上面的代码是词法分析器的实现,部分代码这里没有贴出来,后面具体分析的时候再贴。先来看看词法
分析器的核心方法
start
,这个方法代码量不多,并不复杂。其通过一个死循环不停的读取字符,然后
再根据字符的类型,执行不同的解析逻辑。上面说过,
JSON
的解析过程比较简单。原因在于,在解析
时,只需通过每个词第一个字符即可判断出这个词的
Token Type
。比如:
- 第一个字符是{、}、[、]、,、:,直接封装成相应的 Token 返回即可
- 第一个字符是n,期望这个词是null,Token 类型是NULL
- 第一个字符是t或f,期望这个词是true或者false,Token 类型是 BOOLEAN
- 第一个字符是”,期望这个词是字符串,Token 类型为String
- 第一个字符是0~9或-,期望这个词是数字,类型为NUMBER
正如上面所说,词法分析器只需要根据每个词的第一个字符,即可知道接下来它所期望读取的到的内容是什么样的。如果满足期望了,则返回 Token ,否则返回错误。下面就来看看词法解析器在碰到第一个字符是 n 和 ” 时的处理过程。先看碰到字符 n 的处理过程:

上面的代码很简单,词法分析器在读取字符
n
后,期望后面的三个字符分别是
u,l,l
,与
n
组成词
null
。
如果满足期望,则返回类型为
NULL
的
Token
,否则报异常。
readNull
方法逻辑很简单,不多说了。
接下来看看
string
类型的数据处理过程:

string
类型的数据解析起来要稍微复杂一些,主要是需要处理一些特殊类型的字符。
JSON
所允许的特
殊类型的字符如下:

最后一种特殊字符
\/
代码中未做处理,其他字符均做了判断,判断逻辑在
isEscape
方法中。在传入
JSON
字符串中,仅允许字符串包含上面所列的转义字符。如果乱传转义字符,解析时会报错。对于
STRING
类型的词,解析过程始于字符
”
,也终于
”
。所以在解析的过程中,当再次遇到字符
”
,
readString
方法会认为本次的字符串解析过程结束,并返回相应类型的
Token
。
上面说了
null
类型和
string
类型的数据解析过程,过程并不复杂,理解起来应该不难。至于
boolean
和
number
类型的数据解析过程,大家有兴趣的话可以自己看源码,这里就不在说了。
语法分析
当词法分析结束后,且分析过程中没有抛出错误,那么接下来就可以进行语法分析了。语法分析过程以
词法分析阶段解析出的
Token
序列作为输入,输出
JSON Object
或
JSON Array
。语法分析器的实现的
文法如下:
当词法分析结束后,且分析过程中没有抛出错误,那么接下来就可以进行语法分析了。语法分析过程以
词法分析阶段解析出的
Token
序列作为输入,输出
JSON Object
或
JSON Array
。语法分析器的实现的
文法如下:
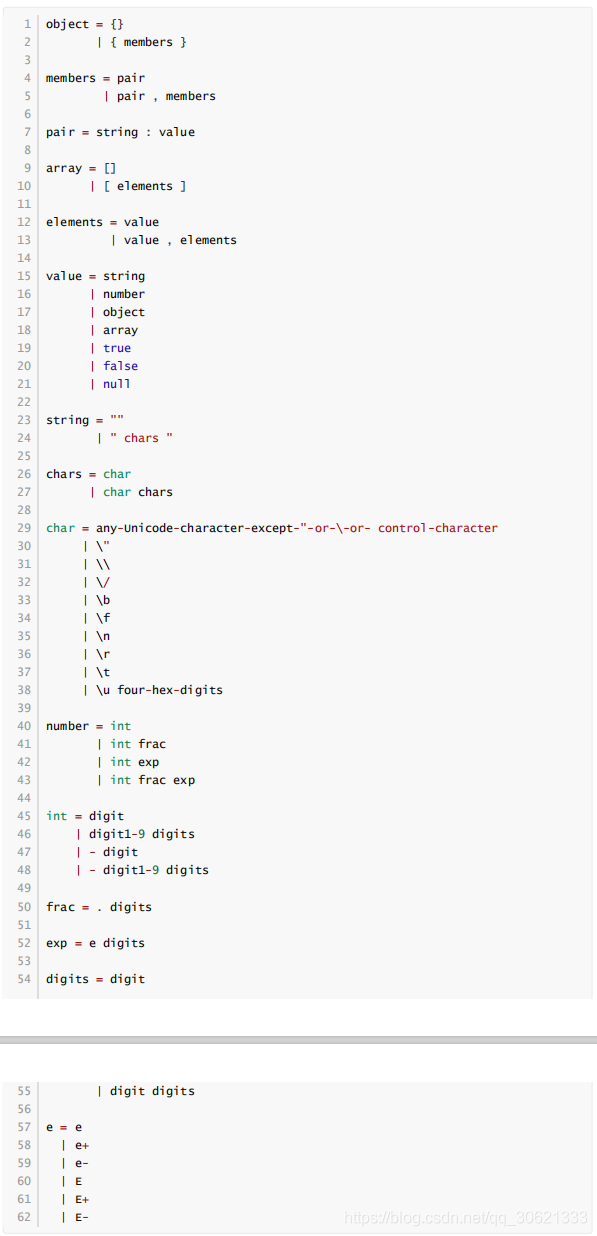
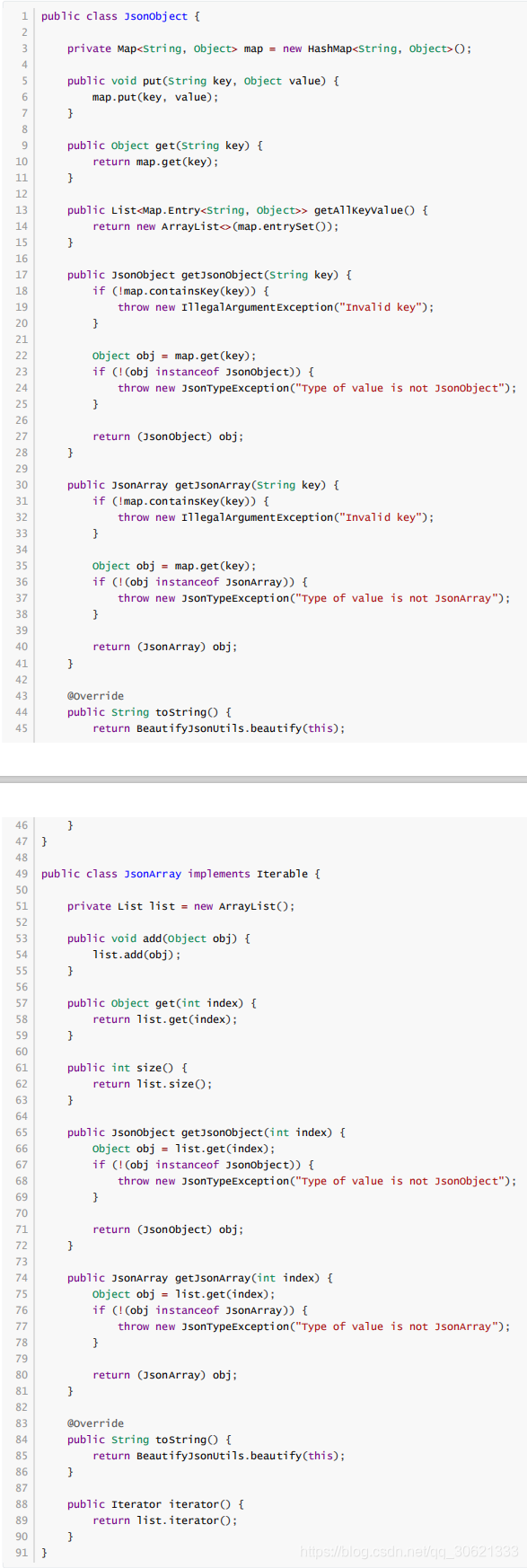
语法分析器的实现需要借助两个辅助类,也就是语法分析器的输出类,分别是
JsonObject
和
JsonArray
。代码如下:
语法解析器的核心逻辑封装在了
parseJsonObject
和
parseJsonArray
两个方法中,接下来我会详细分
析
parseJsonObject
方法,
parseJsonArray
方法大家自己分析吧。
parseJsonObject
方法实现如下:

parseJsonObject
方法解析流程大致如下:
1.
读取一个
Token
,检查这个
Token
是否是其所期望的类型
2.
如果是,更新期望的
Token
类型。否则,抛出异常,并退出
3.
重复步骤
1
和
2
,直至所有的
Token
都解析完,或出现异常
上面的步骤并不复杂,但有可能不好理解。这里举个例子说明一下,有如下的
Token
序列:
{
、
id
、
:
、
1
、
}
parseJsonObject
解析完
{ Token
后,接下来它将期待
STRING
类型的
Token
或者
END_OBJECT
类型
的
Token
出现。于是
parseJsonObject
读取了一个新的
Token
,发现这个
Token
的类型是
STRING
类
型,满足期望。于是
parseJsonObject
更新期望
Token
类型为
SEL_COLON
,即
:
。如此循环下去,直至
Token
序列解析结束或者抛出异常退出。
上面的解析流程虽然不是很复杂,但在具体实现的过程中,还是需要注意一些细节问题。比如:
1.
在
JSON
中,字符串既可以作为键,也可以作为值。作为键时,语法分析器期待下一个
Token
类
型为
SEP_COLON
。而作为值时,则期待下一个
Token
类型为
SEP_COMMA
或
END_OBJECT
。所
以这里要判断该字符串是作为键还是作为值,判断方法也比较简单,即判断上一个
Token
的类型
即可。如果上一个
Token
是
SEP_COLON
,即
:
,那么此处的字符串只能作为值了。否则,则只能
做为键。
2.
对于整数类型的
Token
进行解析时,简单点处理,可以直接将该整数解析成
Long
类型。但考虑
到空间占用问题,对于
[Integer.MIN_VALUE, Integer.MAX_VALUE]
范围内的整数来说,解析成
Integer
更为合适,所以解析的过程中也需要注意一下。
参考
https://segmentfault.com/a/1190000010998941#articleHeader1
Gson
原理解析
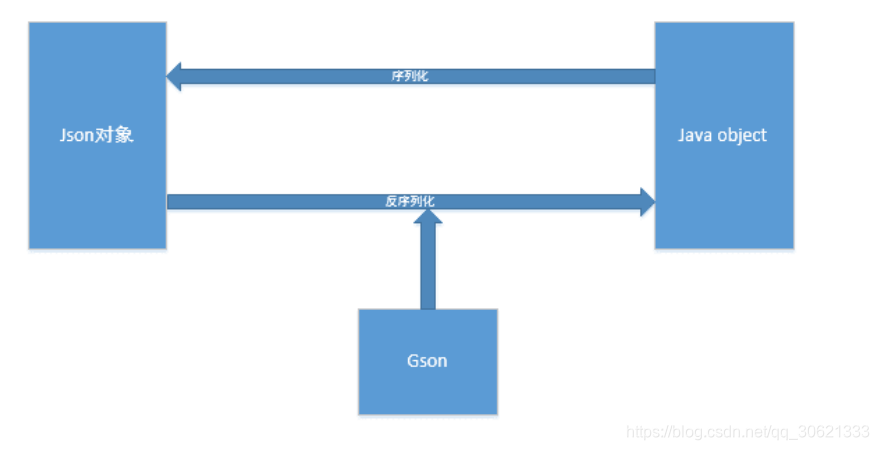
在这个序列化和反序列化的过程中,
充当的了一个解析器的角色
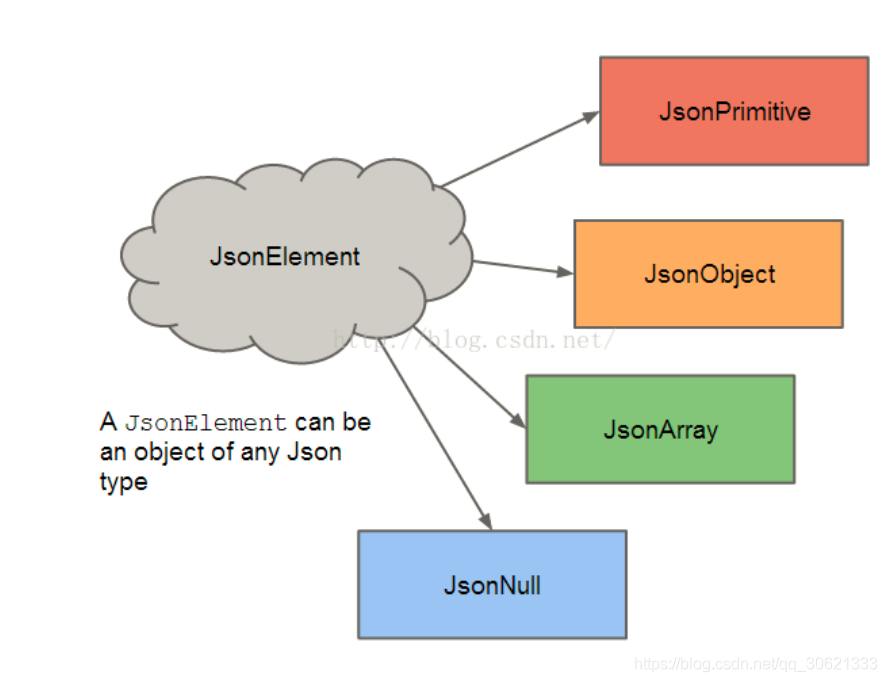
JsonElement
该类是一个抽象类,代表着
json
串的某一个元素。这个元素可以是一个
Json(JsonObject)
、可以是一个
数组
(JsonArray)
、可以是一个
Java
的基本类型
(JsonPrimitive)
、当然也可以为
null(JsonNull);JsonObject,JsonArray,JsonPrimitive
,
JsonNull
都是
JsonElement
这个抽象类的子类。
JsonElement
提供了一系列的方法来判断当前的
JsonElement
各个
JsonElement
的关系可以用如下图表示:
JsonObject
对象可以看成
name/values
的集合,而这写
values
就是一个个
JsonElement,
他们的结构可以
用如下图表示:
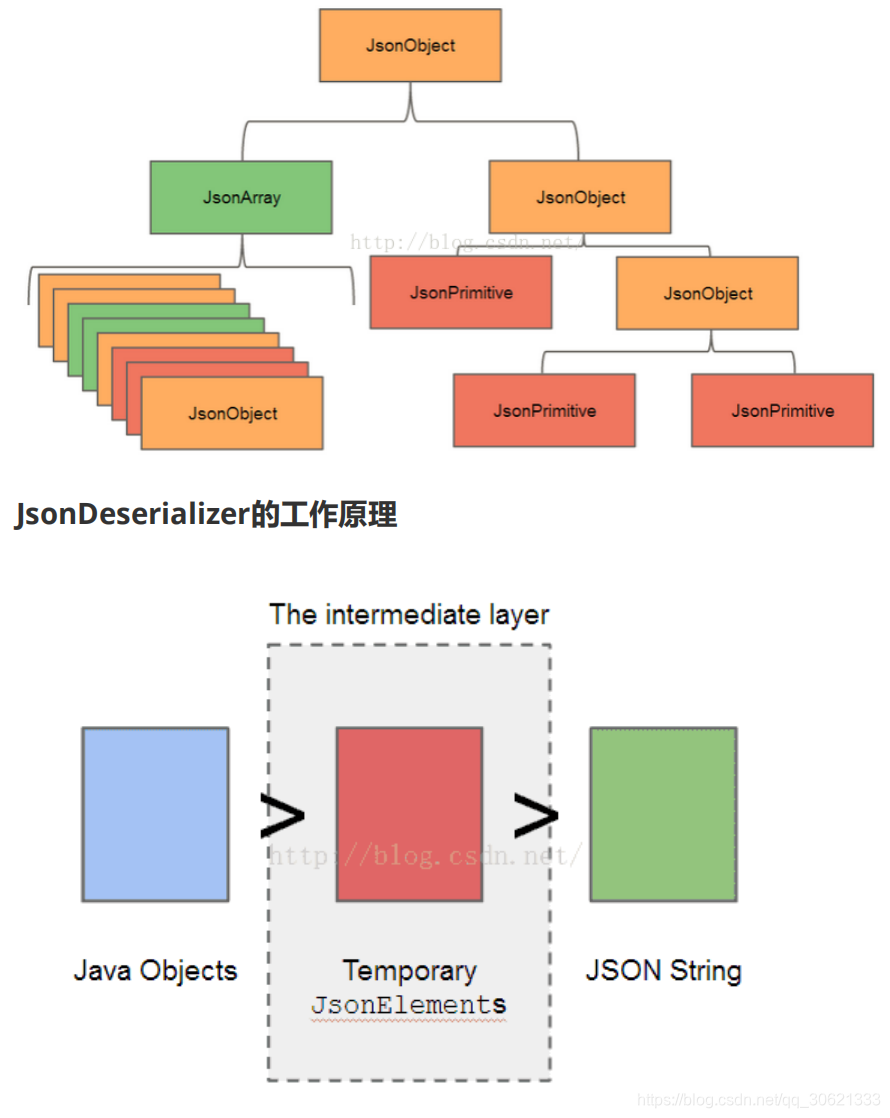
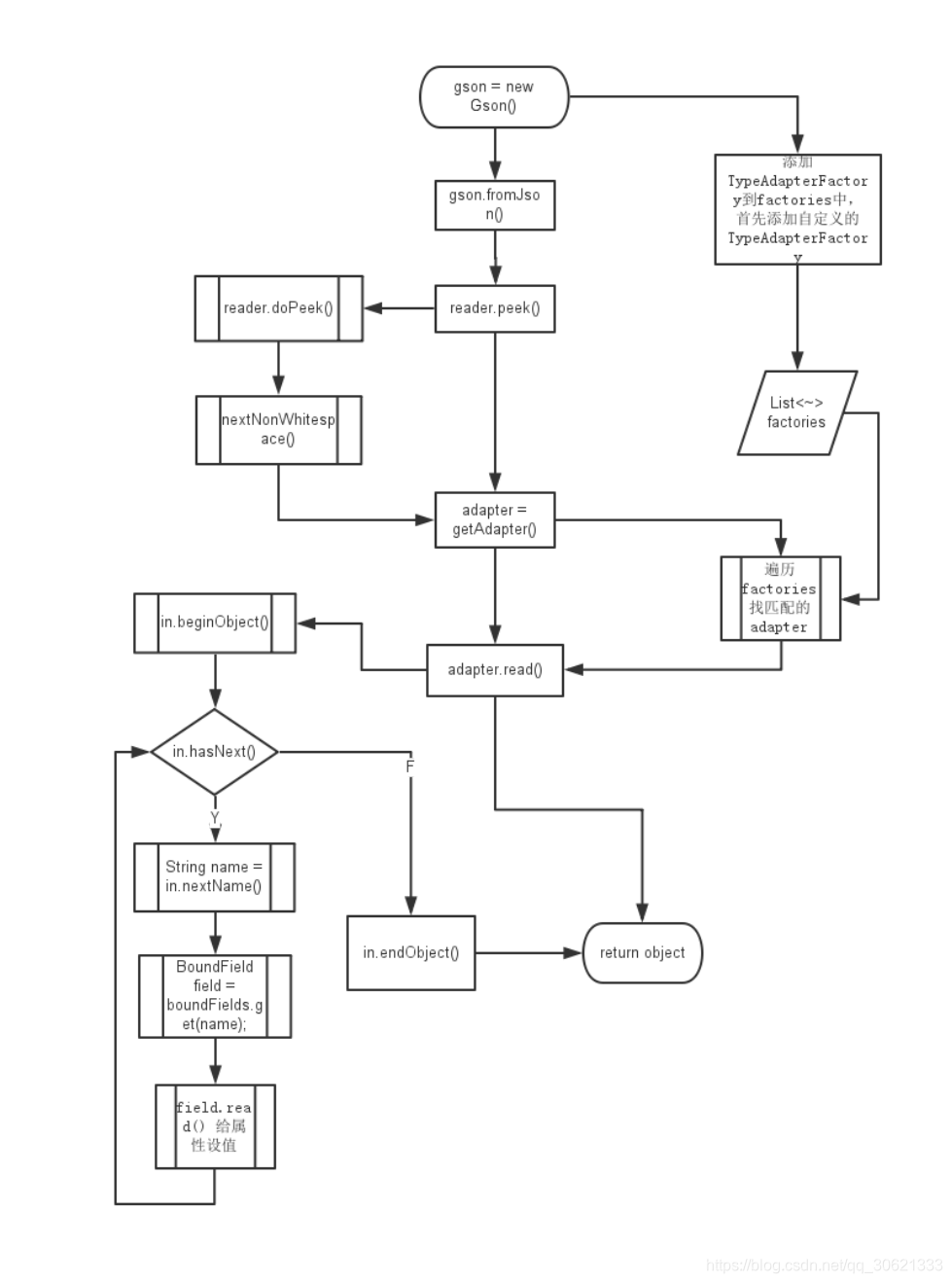
TypeAdapter
的工作原理
Gson
的整体解析原理
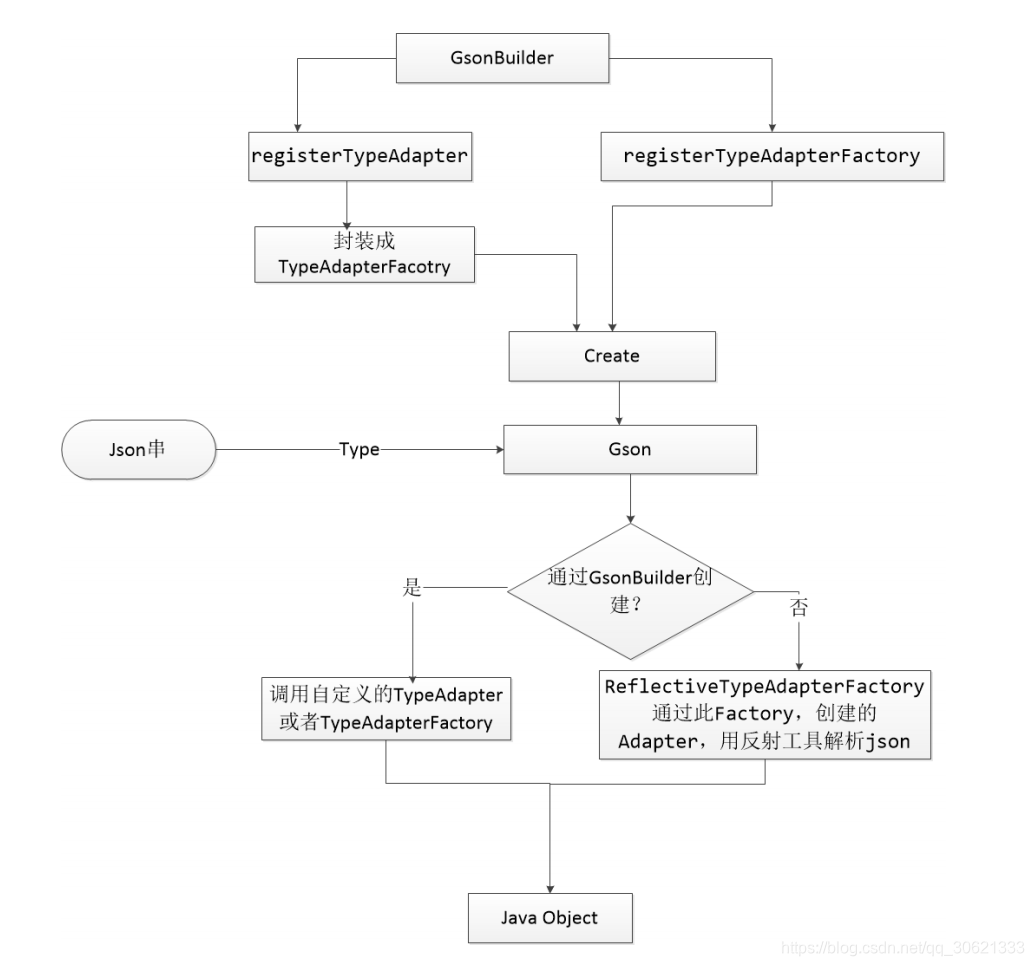
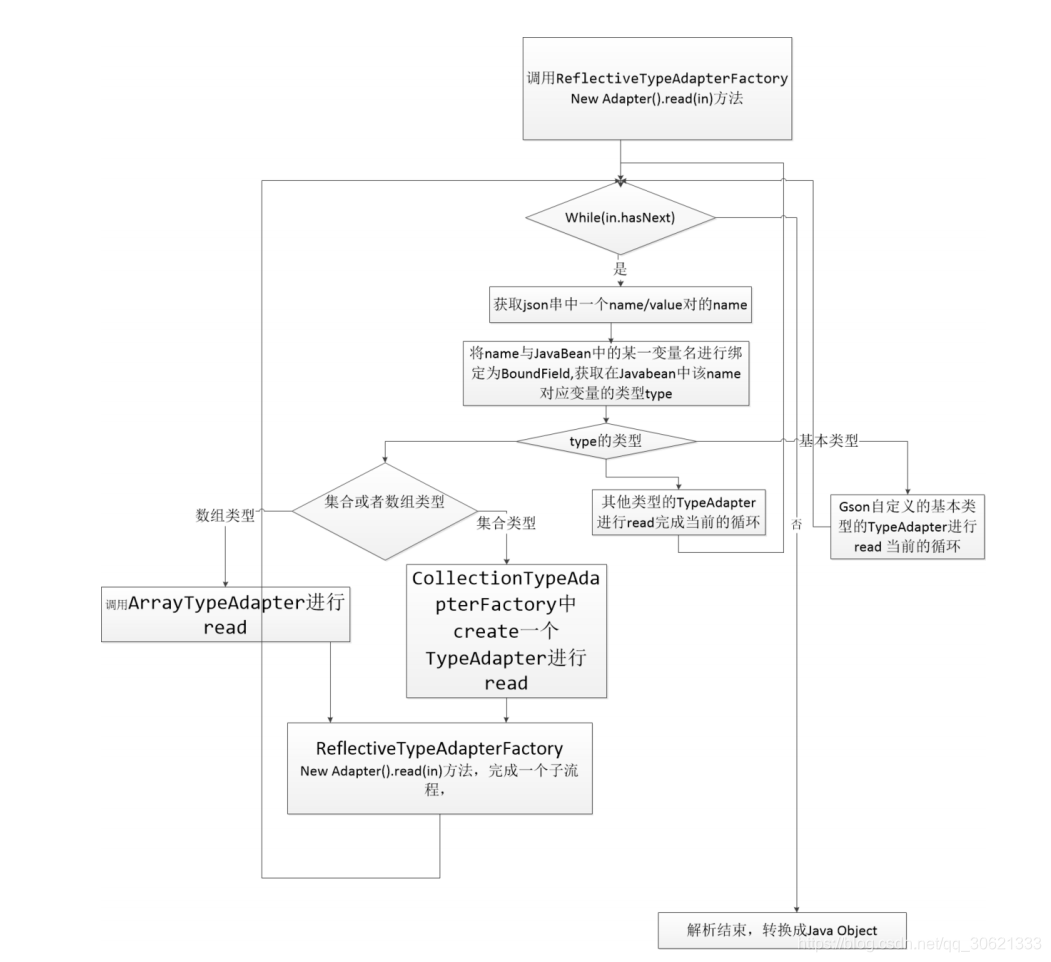
Gson
的反射解析机制
Gson
解析常见的错误
Expected BEGIN_ARRAY but was STRING at line 1 column 27
这种错误一般都是原来是一个字段需要是数组类型,但是事实上给的是
””,
导致的
-
解决办法
1.
让返回
null
即可解决问题
2.
用
Gson
自带的解决方案



















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









