









本文的θ\thetaθ和www都表示权重,σ\sigmaσ、hΘh_{\Theta}hΘ和ggg都表示激活函数。
神经网络的代价函数:
J(Θ)=−1m[∑i=1m∑k=1Kyk(i)log(hΘ(x(i)))k+(1−yk(i))log(1−(hΘ(x(i)))k)]+λ2m∑l=1L−1∑i=1sl∑j=1sl+1(Θji(l))2 \begin{aligned} J(\Theta)=&-\frac{1}{m}\left[\sum_{i=1}^{m} \sum_{k=1}^{K} y_{k}^{(i)} \log \left(h_{\Theta}\left(x^{(i)}\right)\right)_{k}+\left(1-y_{k}^{(i)}\right) \log \left(1-\left(h_{\Theta}\left(x^{(i)}\right)\right)_{k}\right)\right] \\ &+\frac{\lambda}{2 m} \sum_{l=1}^{L-1} \sum_{i=1}^{s_{l}} \sum_{j=1}^{s_{l+1}}\left(\Theta_{j i}^{(l)}\right)^{2} \end{aligned} J(Θ)=−m1[i=1∑mk=1∑Kyk(i)log(hΘ(x(i)))k+(1−yk(i))log(1−(hΘ(x(i)))k)]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θji(l))2
目标:
minΘJ(Θ) \min _{\Theta} J(\Theta) ΘminJ(Θ)
需要计算:
J(Θ) J(\Theta) J(Θ)
∂∂Θij(l)J(Θ) \frac{\partial}{\partial \Theta_{i j}^{(l)}} J(\Theta) ∂Θij(l)∂J(Θ)
假设只有一个训练样本(x,y),
神经网络结构如图:
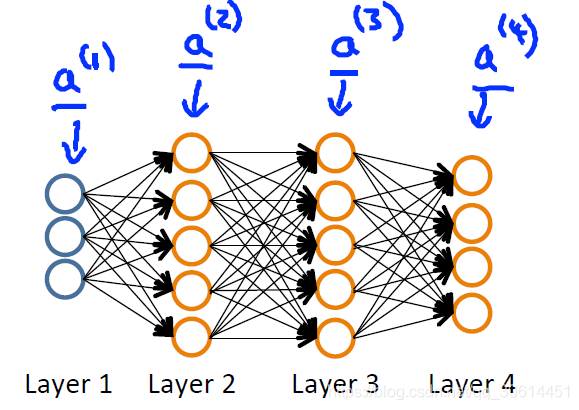
它的前向传播过程如下:
a(1)=xz(2)=Θ(1)a(1)a(2)=g(z(2))( add a0(2))z(3)=Θ(2)a(2)a(3)=g(z(3))( add a0(3))z(4)=Θ(3)a(3)a(4)=hΘ(x)=g(z(4))
\begin{array}{l}{a^{(1)}=x} \\ {z^{(2)}=\Theta^{(1)} a^{(1)}} \\ {a^{(2)}=g\left(z^{(2)}\right)\left(\text { add } a_{0}^{(2)}\right)} \\ {z^{(3)}=\Theta^{(2)} a^{(2)}} \\ {a^{(3)}=g\left(z^{(3)}\right)\left(\text { add } a_{0}^{(3)}\right)} \\ {z^{(4)}=\Theta^{(3)} a^{(3)}} \\ {a^{(4)}=h_{\Theta}(x)=g\left(z^{(4)}\right)}\end{array}
a(1)=xz(2)=Θ(1)a(1)a(2)=g(z(2))( add a0(2))z(3)=Θ(2)a(2)a(3)=g(z(3))( add a0(3))z(4)=Θ(3)a(3)a(4)=hΘ(x)=g(z(4))
反向传播
δj(l)\delta_{j}^{(l)}δj(l) 表示L层j节点处的误差。
对上述一个4层的网络,
反向传播过程中,误差沿着反向传播如下,(公式推导见附录):
δj(4)=aj(4)−yj
\delta_{j}^{(4)}=a_{j}^{(4)}-y_{j}
δj(4)=aj(4)−yj
δ(3)=(Θ(3))Tδ(4)⋅∗g′(z(3))δ(2)=(Θ(2))Tδ(3)⋅∗g′(z(2)) \begin{array}{l}{\delta^{(3)}=\left(\Theta^{(3)}\right)^{T} \delta^{(4)} \cdot * g^{\prime}\left(z^{(3)}\right)} \\ {\delta^{(2)}=\left(\Theta^{(2)}\right)^{T} \delta^{(3)} \cdot * g^{\prime}\left(z^{(2)}\right)}\end{array} δ(3)=(Θ(3))Tδ(4)⋅∗g′(z(3))δ(2)=(Θ(2))Tδ(3)⋅∗g′(z(2))
其中,g′(z)=a⋅∗(1−a)g^{\prime}\left(z^{}\right)=a^{} \cdot *\left(1-a^{}\right)g′(z)=a⋅∗(1−a)
表示sigmoid函数的导数。
这里的δj(l)\delta_{j}^{(l)}δj(l)其实就是代价函数对zj(l)z_{j}^{(l)}zj(l)的偏导,可以对代价函数公式求偏导即可得证。
δj(l)=∂∂zj(l)cost(i)\delta_{j}^{(l)}=\frac{\partial}{\partial z_{j}^{(l)}} \operatorname{cost}(\mathrm{i})δj(l)=∂zj(l)∂cost(i)
其中,单个样品的代价函数表示如下:
cost(i)=y(i)loghΘ(x(i))+(1−y(i))loghΘ(x(i))\operatorname{cost}(\mathrm{i})=y^{(i)} \log h_{\Theta}\left(x^{(i)}\right)+\left(1-y^{(i)}\right) \log h_{\Theta}\left(x^{(i)}\right)cost(i)=y(i)loghΘ(x(i))+(1−y(i))loghΘ(x(i))
其中,hΘ(x(i))=ah_{\Theta}\left(x^{(i)}\right)=ahΘ(x(i))=a,表示每一层的输出,hΘh_{\Theta}hΘ就是sigmoid激活函数,与前文的g()一样。
误差函数对权重 θij(l)\theta_{i j}^{(l)}θij(l)的导数如下:
∂∂θij(l)J(Θ)=aj(l)δi(l+1)
\frac{{\partial}}{{\partial} \theta_{i j}^{(l)}} J(\Theta)=a_{j}^{(l)} \delta_{i}^{(l+1)}
∂θij(l)∂J(Θ)=aj(l)δi(l+1)
这个式子忽略正则项,λ\lambdaλ为0.
对多个样本如何进行反向传播算法?
对训练集 {(x(1),y(1)),…,(x(m),y(m))}\left\{\left(x^{(1)}, y^{(1)}\right), \ldots,\left(x^{(m)}, y^{(m)}\right)\right\}{(x(1),y(1)),…,(x(m),y(m))},
训练过程如下:
首先,置△ij(l)=0( for all l,i,j)\triangle_{i j}^{(l)}=0(\text { for all } l, i, j)△ij(l)=0( for all l,i,j)
接着,遍历训练集:
For i=1i=1i=1 to mmm
{
令 a(1)=x(i)a^{(1)}=x^{(i)}a(1)=x(i)
通过前向传播计算 a(l)a^{(l)}a(l) for l=2,3,…,Ll=2,3, \ldots, Ll=2,3,…,L
使用 y(i),y^{(i)},y(i), 计算误差 δ(L)=a(L)−y(i)\delta^{(L)}=a^{(L)}-y^{(i)}δ(L)=a(L)−y(i)
通过反向传播计算每一层的误差, δ(L−1),δ(L−2),…,δ(2)\delta^{(L-1)}, \delta^{(L-2)}, \ldots, \delta^{(2)}δ(L−1),δ(L−2),…,δ(2)
△ij(l):=△ij(l)+aj(l)δi(l+1)\triangle_{i j}^{(l)} :=\triangle_{i j}^{(l)}+a_{j}^{(l)} \delta_{i}^{(l+1)}△ij(l):=△ij(l)+aj(l)δi(l+1)
}
计算完之后,跳出循环,计算下式:
Dij(l):=1m△ij(l)+λΘij(l) if j≠0Dij(l):=1m△ij(l) if j=0
\begin{array}{ll}{D_{i j}^{(l)} :=\frac{1}{m} \triangle_{i j}^{(l)}+\lambda \Theta_{i j}^{(l)} \text { if } j \neq 0} \\ {D_{i j}^{(l)} :=\frac{1}{m} \triangle_{i j}^{(l)}} & {\text { if } j=0}\end{array}
Dij(l):=m1△ij(l)+λΘij(l) if j̸=0Dij(l):=m1△ij(l) if j=0
就可以得到偏导数:
∂∂Θij(l)J(Θ)=Dij(l)
\frac{\partial}{\partial \Theta_{i j}^{(l)}} J(\Theta)=D_{i j}^{(l)}
∂Θij(l)∂J(Θ)=Dij(l)
参考自:吴恩达机器学习视频
下面整理一下反向传播的过程:
第一步:输入训练集;
第二步:对于训练集中的每个样本x,设置输入层(Input layer)对应的激活值a1a^{1}a1:
第三步:前向传播:
zl=wlal−1+bl,al=σ(zl)z^{l}=w^{l} a^{l-1}+b^{l}, a^{l}=\sigma\left(z^{l}\right)zl=wlal−1+bl,al=σ(zl)
第四步: 计算输出层产生的错误:
δL=∇aC⊙σ′(zL)\delta^{L}=\nabla_{a} C \odot \sigma^{\prime}\left(z^{L}\right)δL=∇aC⊙σ′(zL)
也可以表示为:δL=aj−yj\delta^{L}=a_{j}-y_{j}δL=aj−yj
第五步: 反向传播计算每一层的错误:
δl=((wl+1)Tδl+1)⊙σ′(zl)\delta^{l}=\left(\left(w^{l+1}\right)^{T} \delta^{l+1}\right) \odot \sigma^{\prime}\left(z^{l}\right)δl=((wl+1)Tδl+1)⊙σ′(zl)
第六步: 使用梯度下降(gradient descent),训练参数:
wl→wl−ηm∑xδx,l(ax,l−1)Tw^{l} \rightarrow w^{l}-\frac{\eta}{m} \sum_{x} \delta^{x, l}\left(a^{x, l-1}\right)^{T}wl→wl−mη∑xδx,l(ax,l−1)T
bl→bl−ηm∑xδx,lb^{l} \rightarrow b^{l}-\frac{\eta}{m} \sum_{x} \delta^{x, l}bl→bl−mη∑xδx,l
附录
符号说明:
wjklw_{j k}^{l}wjkl表示第l-1层的第k个神经元连接到第l层的第j个神经元之间的权重;
bjlb_{j}^{l}bjl表示第l层的第j个神经元的偏置;
zjlz_{j}^{l}zjl表示第l层的第j个神经元的输入,即:
zjl=∑kwjklakl−1+bjlz_{j}^{l}=\sum_{k} w_{j k}^{l} a_{k}^{l-1}+b_{j}^{l}zjl=∑kwjklakl−1+bjl
ajla_{j}^{l}ajl表示第l层第j个神经元的输出,即:
ajl=σ(∑kwjklakl−1+bjl)a_{j}^{l}=\sigma\left(\sum_{k} w_{j k}^{l} a_{k}^{l-1}+b_{j}^{l}\right)ajl=σ(∑kwjklakl−1+bjl)
σ\sigmaσ表示激活函数。(本文激活函数用不同的符号都表示过,但其实是一样的,从很多地方整理而来,懒得去改了)
⊙\odot⊙表示Hadamard乘积,用于矩阵或向量之间点对点的乘法运算.
误差的推导:
δl=((wl+1)Tδl+1)⊙σ′(zl)\delta^{l}=\left(\left(w^{l+1}\right)^{T} \delta^{l+1}\right) \odot \sigma^{\prime}\left(z^{l}\right)δl=((wl+1)Tδl+1)⊙σ′(zl)
推导过程:
∵δjl=∂C∂zjl=∑k∂C∂zkl+1⋅∂zkl+1∂ajl⋅∂ajl∂zjl\because \delta_{j}^{l}=\frac{\partial C}{\partial z_{j}^{l}}=\sum_{k} \frac{\partial C}{\partial z_{k}^{l+1}} \cdot \frac{\partial z_{k}^{l+1}}{\partial a_{j}^{l}} \cdot \frac{\partial a_{j}^{l}}{\partial z_{j}^{l}}∵δjl=∂zjl∂C=∑k∂zkl+1∂C⋅∂ajl∂zkl+1⋅∂zjl∂ajl
=∑kδkl+1⋅∂(wkjl+1ajl+bkl+1)∂ajl⋅σ′(zjl)=\sum_{k} \delta_{k}^{l+1} \cdot \frac{\partial\left(w_{k j}^{l+1} a_{j}^{l}+b_{k}^{l+1}\right)}{\partial a_{j}^{l}} \cdot \sigma^{\prime}\left(z_{j}^{l}\right)=∑kδkl+1⋅∂ajl∂(wkjl+1ajl+bkl+1)⋅σ′(zjl)
=∑kδkl+1⋅wkjl+1⋅σ′(zjl)=\sum_{k} \delta_{k}^{l+1} \cdot w_{k j}^{l+1} \cdot \sigma^{\prime}\left(z_{j}^{l}\right)=∑kδkl+1⋅wkjl+1⋅σ′(zjl)
∴δl=((wl+1)Tδl+1)⊙σ′(zl)\therefore \delta^{l}=\left(\left(w^{l+1}\right)^{T} \delta^{l+1}\right) \odot \sigma^{\prime}\left(z^{l}\right)∴δl=((wl+1)Tδl+1)⊙σ′(zl)
权重导数的推导:
∂C∂wjkl=akl−1δjl\frac{\partial C}{\partial w_{j k}^{l}}=a_{k}^{l-1} \delta_{j}^{l}∂wjkl∂C=akl−1δjl
推导过程:
∂C∂wjkl=∂C∂zjl⋅∂zjl∂wjkl=δjl⋅∂(wjklakl−1+bjl)∂wjkl=akl−1δjl\frac{\partial C}{\partial w_{j k}^{l}}=\frac{\partial C}{\partial z_{j}^{l}} \cdot \frac{\partial z_{j}^{l}}{\partial w_{j k}^{l}}=\delta_{j}^{l} \cdot \frac{\partial\left(w_{j k}^{l} a_{k}^{l-1}+b_{j}^{l}\right)}{\partial w_{j k}^{l}}=a_{k}^{l-1} \delta_{j}^{l}∂wjkl∂C=∂zjl∂C⋅∂wjkl∂zjl=δjl⋅∂wjkl∂(wjklakl−1+bjl)=akl−1δjl
偏置导数的推导:
∂C∂bjl=δjl\frac{\partial C}{\partial b_{j}^{l}}=\delta_{j}^{l}∂bjl∂C=δjl
推导过程:
∂C∂bjl=∂C∂zjl⋅∂zjl∂bjl=δjl⋅∂(wjklakl−1+bjl)∂bjl=δjl\frac{\partial C}{\partial b_{j}^{l}}=\frac{\partial C}{\partial z_{j}^{l}} \cdot \frac{\partial z_{j}^{l}}{\partial b_{j}^{l}}=\delta_{j}^{l} \cdot \frac{\partial\left(w_{j k}^{l} a_{k}^{l-1}+b_{j}^{l}\right)}{\partial b_{j}^{l}}=\delta_{j}^{l}∂bjl∂C=∂zjl∂C⋅∂bjl∂zjl=δjl⋅∂bjl∂(wjklakl−1+bjl)=δjl

















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









