




 本文介绍了一种使用Java和Spring Boot框架从汽车之家网站抓取汽车评测数据的方法,包括环境搭建、数据库设计、API服务实现及定时任务调度。
本文介绍了一种使用Java和Spring Boot框架从汽车之家网站抓取汽车评测数据的方法,包括环境搭建、数据库设计、API服务实现及定时任务调度。
java抓取汽车之家上的汽车评测数据
一、环境准备
1. 使用技术
- java8
- Springboot2.2.2
- Mybatis-plus3.2.0
- HttpClient4.5.10
- Jsoup1.11.3
- Quartz5.1.9.RELEASE
2.创建springboot项目,引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.2.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>cn.helin9s.crawler.autohome</groupId>
<artifactId>crawler-autohome</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>crawler-autohome</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--常用工具类-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.8.1</version>
</dependency>
<!--定时任务Quartz-->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>5.1.9.RELEASE</version>
</dependency>
<!--HttpClient-->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</dependency>
<!--jsoup-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
<!--mybatisplus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.2.0</version>
<exclusions>
<exclusion>
<artifactId>jsqlparser</artifactId>
<groupId>com.github.jsqlparser</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.12</version>
<exclusions>
<exclusion>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
</exclusion>
<exclusion>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--mysql连接驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
3. 配置yml文件
- application.yml
spring:
profiles:
active: dev
server:
port: 8080
mybatis-plus:
global-config:
db-config:
id-type: auto
mapper-locations: classpath:mapper/*.xml
configuration:
map-underscore-to-camel-case: true
pagehelper:
helper-dialect: mysql
params: count=countSql
support-methods-arguments: true
- application-dev.yml
logging:
level:
cn.helin9s.crawler.autohome.crawlerautohome.dao: trace
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/crawler?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: 123456
hikari:
auto-commit: true
connection-test-query: select 1
4. 测试数据库连接
创建mapper接口和xml
package cn.helin9s.crawler.autohome.crawlerautohome.dao;
import org.springframework.stereotype.Repository;
/**
* @author helin
* @project crawler-autohome
* @package cn.helin9s.crawler.autohome.crawlerautohome.dao
* @description @TODO
* @create 2020-01-01 21:26
*/
@Repository
public interface TestDao {
public String getNow();
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.helin9s.crawler.autohome.crawlerautohome.dao.TestDao">
<select id="getNow" resultType="java.lang.String">
select NOW();
</select>
</mapper>
测试
package cn.helin9s.crawler.autohome.crawlerautohome;
import cn.helin9s.crawler.autohome.crawlerautohome.dao.TestDao;
import cn.helin9s.crawler.autohome.crawlerautohome.service.ApiService;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class CrawlerAutohomeApplicationTests {
@Autowired
private TestDao testDao;
@Test
public void test(){
String now = testDao.getNow();
System.out.println(now);
}
}
测试通过后开发环境准备完成。
二、 开发分析
1.流程分析
测评页面的url是 https://www.autohome.com.cn/bestauto/1
最后一个参数是当前页码,我们只需要按照顺序从第一页开始把所有页面都抓取下来即可。
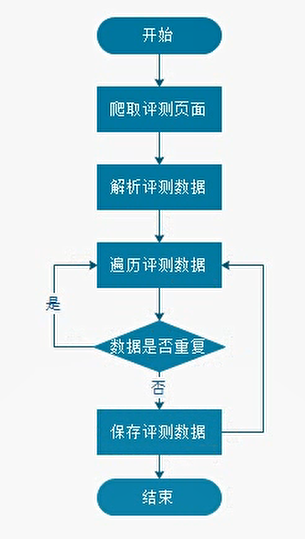
- 根据url抓取html页面
- 对html页面进行解析,获取该页面所有的评测数据
- 遍历所有的评测数据
- 判断遍历的评测数据是否已经保存,如果已经保存则再次遍历下一条评测数据
- 如果没保存则保存数据。
2. 数据库表设计
创建数据库 crawler
CREATE DATABASE crawler;
创建汽车之家评测表 car_test
CREATE TABLE `car_test` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT '' COMMENT '评测车辆名称',
`test_speed` int(150) unsigned DEFAULT '0' COMMENT '评测项目-加速(0-100公里/小时),单位毫秒',
`test_brake` int(150) unsigned DEFAULT '0' COMMENT '评测项目-刹车(100-0公里/小时),单位毫米',
`test_oil` int(150) unsigned DEFAULT '0' COMMENT '评测项目-实测油耗(升/100公里),单位毫升',
`editor_name1` varchar(10) COLLATE utf8mb4_unicode_ci DEFAULT '' COMMENT '评测编辑1',
`editor_remark1` varchar(1000) COLLATE utf8mb4_unicode_ci DEFAULT '' COMMENT '点评内容1',
`editor_name2` varchar(10) COLLATE utf8mb4_unicode_ci DEFAULT '' COMMENT '评测编辑2',
`editor_remark2` varchar(1000) COLLATE utf8mb4_unicode_ci DEFAULT '' COMMENT '点评内容2',
`editor_name3` varchar(10) COLLATE utf8mb4_unicode_ci DEFAULT '' COMMENT '评测编辑3',
`editor_remark3` varchar(1000) COLLATE utf8mb4_unicode_ci DEFAULT '' COMMENT '点评内容3',
`image` varchar(1000) COLLATE utf8mb4_unicode_ci DEFAULT '' COMMENT '评测图片,5张图片名,中间用,分隔',
`created` datetime DEFAULT NULL COMMENT '创建时间',
`updated` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='汽车之家评测表';
用idea的database工具连接数据库
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gsg65aZy-1580035541769)(https://i.loli.net/2020/01/02/snfT9uNybOGqALP.png)]
右键点击创建好的car_test表,生成pojo对象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VyAkUFQl-1580035541770)(https://i.loli.net/2020/01/02/DxgsJknPpb2KwAH.png)]
改造对象
package cn.helin9s.crawler.autohome.crawlerautohome.pojo.model;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.*;
import java.util.Date;
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
@EqualsAndHashCode
@TableName("car_test")
public class CarTestModel {
private Long id;
private String title;
private Long testSpeed;
private Long testBrake;
private Long testOil;
private String editorName1;
private String editorRemark1;
private String editorName2;
private String editorRemark2;
private String editorName3;
private String editorRemark3;
private String image;
private Date created;
private Date updated;
}
三、爬取数据实现ApiService
1. 编写连接池管理
- 编写连接池管理器
package cn.helin9s.crawler.autohome.crawlerautohome.config;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author helin
* @project crawler-autohome
* @package cn.helin9s.crawler.autohome.crawlerautohome.config
* @description @TODO
* @create 2020-01-01 22:35
*/
@Configuration
public class HttpClientConnectManagerCfg {
@Bean
public PoolingHttpClientConnectionManager poolingHttpClientConnectionManager(){
//创建连接管理器
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
//设置最大连接数
cm.setMaxTotal(200);
//设置每个主机的最大连接数
cm.setDefaultMaxPerRoute(20);
return cm;
}
}
- 编写定时任务调度器
package cn.helin9s.crawler.autohome.crawlerautohome.config;
import cn.helin9s.crawler.autohome.crawlerautohome.config.job.CloseConnectJob;
import org.quartz.Trigger;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.quartz.CronTriggerFactoryBean;
import org.springframework.scheduling.quartz.JobDetailFactoryBean;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;
/**
* @author helin
* @project crawler-autohome
* @package cn.helin9s.crawler.autohome.crawlerautohome.config
* @description @TODO
* @create 2020-01-01 22:42
*/
@Configuration
public class SchedledCfg {
/**
* 定义关闭无效连接任务
* @return
*/
@Bean("closeConnectJobBean")
public JobDetailFactoryBean jobDetailFactoryBean(){
//创建任务描述的工厂bean
JobDetailFactoryBean jb = new JobDetailFactoryBean();
//设置spirng容器的key,任务中可以根据这个key获取spring容器
jb.setApplicationContextJobDataKey("context");
//设置任务
jb.setJobClass(CloseConnectJob.class);
//设置当没有触发器和任务绑定,不会删除任务
jb.setDurability(true);
return jb;
}
/**
* 定义关闭无效连接触发器
* //@Qualifier注解是通过名字注入bean,
* @return
*/
@Bean
public CronTriggerFactoryBean cronTriggerFactoryBean(
@Qualifier(value = "closeConnectJobBean") JobDetailFactoryBean itemJobBean){
//创建一个表达式触发器工厂bean
CronTriggerFactoryBean cronTriggerFactoryBean = new CronTriggerFactoryBean();
//设置任务描述到触发器
cronTriggerFactoryBean.setJobDetail(itemJobBean.getObject());
//设置Cron表达式(从第0秒开始每隔5秒执行一次)
cronTriggerFactoryBean.setCronExpression("0/5 * * * * ? ");
return cronTriggerFactoryBean;
}
/**
* 定义调度器
* @return
*/
@Bean
public SchedulerFactoryBean schedulerFactoryBean(Trigger cronTriggerImpl){
//创建任务调度器的工厂bean
SchedulerFactoryBean bean = new SchedulerFactoryBean();
//给任务调度器设置触发器
bean.setTriggers(cronTriggerImpl);
return bean;
}
}
- 编写定时任务(定时关闭失效连接)
package cn.helin9s.crawler.autohome.crawlerautohome.config.job;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.quartz.DisallowConcurrentExecution;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.context.ApplicationContext;
import org.springframework.scheduling.quartz.QuartzJobBean;
/**
* @author helin
* @project crawler-autohome
* @package cn.helin9s.crawler.autohome.crawlerautohome.config
* @description 定时关闭HttpClient的无效连接
* @create 2020-01-01 23:18
*/
//当定时任务没有执行完的情况下,不会再次启动新的任务
@DisallowConcurrentExecution
public class CloseConnectJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
//System.out.println("CloseConnectJob");
//todo 获取Spring容器
ApplicationContext applicationContext =(ApplicationContext)context.getJobDetail().getJobDataMap().get("context");
//todo 从Spring容器中获取HttpClient的连接管理器,关闭无效连接
applicationContext.getBean(PoolingHttpClientConnectionManager.class).closeExpiredConnections();
}
}
2.编写和实现ApiService接口
- 接口层
package cn.helin9s.crawler.autohome.crawlerautohome.service;
/**
* @author helin
* @project crawler-autohome
* @package cn.helin9s.crawler.autohome.crawlerautohome.service
* @description 1.Get请求获取页面数据 2.Get请求下载图片
* @create 2020-01-02 11:01
*/
public interface ApiService {
/**
* Get请求获取页面数据
* @param url
* @return
*/
public String getHtml(String url);
/**
* Get请求下载图片
* @param url
* @return
*/
public String getImage(String url);
}
- 实现层
package cn.helin9s.crawler.autohome.crawlerautohome.service.impl;
import cn.helin9s.crawler.autohome.crawlerautohome.service.ApiService;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.util.EntityUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Optional;
import java.util.UUID;
/**
* @author helin
* @project crawler-autohome
* @package cn.helin9s.crawler.autohome.crawlerautohome.service.impl
* @description @TODO
* @create 2020-01-02 11:04
*/
@Service
public class ApiServiceImpl implements ApiService {
@Autowired
private PoolingHttpClientConnectionManager cm;
/**
* 获取请求参数对象
* @return
*/
private RequestConfig getConfig(){
return RequestConfig.custom()
.setConnectTimeout(1000) //设置创建连接的 超时时间
.setConnectionRequestTimeout(500) //设置获取连接的超时时间
.setSocketTimeout(10000) //设置连接的超时时间
.build();
}
@Override
public String getHtml(String url) {
//todo 1.获取HttpClient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(cm).build();
//todo 2.声明HttpGet请求对象
HttpGet httpGet = new HttpGet(url);
//todo 3.设置用户代理信息
httpGet.setHeader("User-Agent", "");
//todo 4.设置请求参数RequestConfig
httpGet.setConfig(getConfig());
//todo 5.使用HttpClient发起请求,返回response
String html="";
try(CloseableHttpResponse response = httpClient.execute(httpGet)) {
//todo 6.解析response返回数据
html = Optional.ofNullable(response).map(resp -> {
if (resp.getStatusLine().getStatusCode() == 200) {
return resp.getEntity();
} else {
return null;
}
}).map(entity -> {
try {
return EntityUtils.toString(entity, "UTF-8");
} catch (IOException e) {
e.printStackTrace();
}
return "";
}).orElse("");
} catch (IOException e) {
e.printStackTrace();
}
return html;
}
@Override
public String getImage(String url) {
//todo 1.获取HttpClient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(cm).build();
//todo 2.声明HttpGet请求对象
HttpGet httpGet = new HttpGet(url);
//todo 3.设置用户代理信息
httpGet.setHeader("User-Agent", "");
//todo 4.设置请求参数RequestConfig
httpGet.setConfig(getConfig());
//todo 5.使用HttpClient发起请求,返回response
String imageName="";
try(CloseableHttpResponse response = httpClient.execute(httpGet)) {
//todo 6.解析response返回数据
imageName = Optional.ofNullable(response).map(resp -> {
if (resp.getStatusLine().getStatusCode() == 200) {
return resp.getEntity();
} else {
return null;
}
}).map(entity -> {
//获取文件类型(image/gif、image/png等)
String extName = "." + entity.getContentType().getValue().split("/")[1];
//todo 使用uuid生成图片名称
String imgName = UUID.randomUUID().toString()+extName;
//todo 输出的文件地址
String path="F:/images/";
try {
//todo 声明输出的文件
OutputStream outputStream = new FileOutputStream(new File(path+imgName));
//todo 使用响应体输出文件
entity.writeTo(outputStream);
} catch (Exception e) {
e.printStackTrace();
}
return imgName;
}).orElse("");
} catch (IOException e) {
e.printStackTrace();
}
return imageName;
}
}
- 测试
package cn.helin9s.crawler.autohome.crawlerautohome;
import cn.helin9s.crawler.autohome.crawlerautohome.service.ApiService;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class CrawlerAutohomeApplicationTests {
@Autowired
private ApiService apiService;
public static final String URL="https://www.autohome.com.cn/bestauto/1";
public static final String IMGURL="https://car2.autoimg.cn/cardfs/product/g27/M06/0B/BD/1024x0_1_q95_autohomecar__ChcCQF4B36qALfbDAAcdSW2oROc338.jpg";
@Test
public void getHtml(){
String html = apiService.getHtml(URL);
Document dom = Jsoup.parse(html);
System.out.println(dom.select("title").first().text());
}
@Test
public void getImage(){
String image = apiService.getImage(IMGURL);
System.out.println(image);
}
}
3.去重过滤器
-
布隆过滤器
布隆过滤器主要用于判断一个元素是否在一个集合中,它可以使用一个位数组简洁的表示一个数组。它的空间效率和查询时间远远超过一般的算法,但是它存在一定的误判的概率,适用于容忍误判的场景。如果布隆过滤器判断元素存在于一个集合中,那么大概率是存在在集合中,如果它判断元素不存在一个集合中,那么一定不存在于集合中。常常被用于大数据去重。
算法思想
布隆过滤器算法主要思想就是利用k个哈希函数计算得到不同的哈希值,然后映射到相应的位数组的索引上,将相应的索引位上的值设置为1。判断该元素是否出现在集合中,就是利用k个不同的哈希函数计算哈希值,看哈希值对应相应索引位置上面的值是否是1,如果有1个不是1,说明该元素不存在在集合中。但是也有可能判断元素在集合中,但是元素不在,这个元素所有索引位置上面的1都是别的元素设置的,这就导致一定的误判几率。布隆过滤的思想如下图所示:

java实现简单布隆过滤器(hash+bitset):
import java.util.ArrayList; import java.util.BitSet; import java.util.List; public class BloomFilter { /*BitSet初始分配2^24个bit*/ private static final int DEFAULT_SIZE = 2 << 24; /*不同哈希函数的种子,一般应取质数*/ private static final int[] seeds = new int[] { 5, 7, 11, 13, 31, 37, 61 }; private BitSet bits = new BitSet(DEFAULT_SIZE); /*哈希函数对象*/ private SimpleHash[] func = new SimpleHash[seeds.length]; public BloomFilter() { for (int i = 0; i < seeds.length; i++) { func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]); } } /*将需要去重的元素标记到bits中*/ public void add(String value) { for (SimpleHash f : func) { bits.set(f.hash(value), true); } } public boolean contains(String value) { if (value == null) { return false; } boolean ret = true; for (SimpleHash f : func) { ret = ret && bits.get(f.hash(value)); } return ret; } /*哈希函数内部类*/ public static class SimpleHash { private int cap; private int seed; public SimpleHash(int cap, int seed) { this.cap = cap; this.seed = seed; } public int hash(String value) { int result = 0; int len = value.length(); for (int i = 0; i < len; i++) { result = seed * result + value.charAt(i); } return (cap - 1) & result; } } public static void main(String[] args) { BloomFilter bf = new BloomFilter(); List<String> strs = new ArrayList<String>(); strs.add("123456"); strs.add("hello word"); strs.add("transDocId"); strs.add("123456"); strs.add("transDocId"); strs.add("hello word"); strs.add("test"); for (int i=0;i<strs.size();i++) { String s = strs.get(i); boolean bl = bf.contains(s); if(bl){ System.out.println(i+","+s); }else{ bf.add(s); } } } } -
配置过滤器
package cn.helin9s.crawler.autohome.crawlerautohome.config;
import cn.helin9s.crawler.autohome.crawlerautohome.dao.CarTestDao;
import cn.helin9s.crawler.autohome.crawlerautohome.pojo.model.CarTestModel;
import cn.helin9s.crawler.autohome.crawlerautohome.util.TitleFilter;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
/**
* @author helin
* @project crawler-autohome
* @package cn.helin9s.crawler.autohome.crawlerautohome.config
* @description @TODO
* @create 2020-01-02 16:08
*/
@Configuration
public class TitleFilterCfg {
@Autowired
private CarTestDao carTestDao;
@Bean
public TitleFilter titleFilter(){
TitleFilter titleFilter;
//声明页码数
Integer page=1;
//声明分页大小
Integer pageSize=100;
for (;;){
titleFilter = new TitleFilter();
//查询数据库中title数据,因为数据量过大,最好分页查询
List<CarTestModel> list = carTestDao.getList(page-1, pageSize);
for (CarTestModel carTestModel : list) {
//初始化数据,把数据库中已有数据的汽车标题放到去重过滤器中
titleFilter.add(carTestModel.getTitle());
}
//执行完成后页码加1
page++;
//如果最后一页则退出
if (!pageSize.equals(list.size())){
break;
}
}
return titleFilter;
}
}
- 查询数据接口
package cn.helin9s.crawler.autohome.crawlerautohome.dao;
import cn.helin9s.crawler.autohome.crawlerautohome.pojo.model.CarTestModel;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Param;
import org.springframework.stereotype.Repository;
import java.util.List;
/**
* @author helin
* @project crawler-autohome
* @package cn.helin9s.crawler.autohome.crawlerautohome.dao
* @description @TODO
* @create 2020-01-01 22:32
*/
@Repository
public interface CarTestDao extends BaseMapper<CarTestModel> {
List<CarTestModel> getList(@Param("pageNum") Integer pageNum,@Param("pageSize") Integer pageSize);
}
- 查询数据mybatis实现
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.helin9s.crawler.autohome.crawlerautohome.dao.CarTestDao">
<select id="getList" resultType="cn.helin9s.crawler.autohome.crawlerautohome.pojo.model.CarTestModel">
select * from car_test limit #{pageNum},#{pageSize}
</select>
</mapper>
4.实现爬取测试方法
- 提前通过测试方法获取一个页面存在本地
package cn.helin9s.crawler.autohome.crawlerautohome;
import cn.helin9s.crawler.autohome.crawlerautohome.service.ApiService;
import org.apache.commons.io.FileUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.File;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
//@SpringBootTest
class CrawlerAutohomeApplicationTests {
@Test
public void testJsoupGetHtml() throws Exception {
//解析url地址,第一个参数是需要解析的url,第二个参数是连接的超时时间(ms)
Document dom = Jsoup.parse(new URL("https://www.autohome.com.cn/bestauto/1"), 10000);
//获取页面信息,输出为html文件
FileUtils.writeStringToFile(new File("C:/Users/he/Desktop/test1.html"), dom.html(), "UTF-8");
//使用dom对象解析页面,获取title标签的内容
String title = dom.getElementsByTag("title").first().text();
System.out.println(title);
}
}
- 然后在springboot的测试方法中编写对该页面的解析逻辑
package cn.helin9s.crawler.autohome.crawlerautohome;
import cn.helin9s.crawler.autohome.crawlerautohome.pojo.model.CarTestModel;
import cn.helin9s.crawler.autohome.crawlerautohome.service.ApiService;
import cn.helin9s.crawler.autohome.crawlerautohome.service.ICarTestService;
import cn.helin9s.crawler.autohome.crawlerautohome.util.TitleFilter;
import org.apache.commons.lang3.ArrayUtils;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* @author helin
* @project crawler-autohome
* @package cn.helin9s.crawler.autohome.crawlerautohome
* @description @TODO
* @create 2020-01-03 17:06
*/
@SpringBootTest
public class AutohomeCrawlerTest {
@Autowired
private ApiService apiService;
@Autowired
private ICarTestService carTestService;
@Autowired
private TitleFilter titleFilter;
@Test
public void testCrawler() throws IOException {
//todo 使用jsoup解析页面
Document dom = Jsoup.parse(new File("C:/Users/he/Desktop/test1.html"), "UTF-8");
//todo 获取所有评测的div
Elements divs = dom.select("#bestautocontent div.uibox");
//todo 遍历当前页所有评测数据
for (Element div : divs) {
//去重过滤,重复的数据就不需要再处理了
String title = div.select("div.uibox-title").first().text();
if (titleFilter.contains(title)){
//如果数据存在,表示重复,进行下次遍历
continue;
}
//解析页面,获取评测数据对象
CarTestModel carTestModel = getCarTestModel(div);
//解析页面,下载车辆评测图片
String carImage = getCarImage(div);
//把汽车数据存到数据库
carTestModel.setImage(carImage);
carTestService.save(carTestModel);
}
}
/**
* 解析传递进来的元素,封装为汽车评测对象
* @param div
* @return
*/
private CarTestModel getCarTestModel(Element div){
CarTestModel carTestModel = new CarTestModel(null,
div.select("div.uibox-title").first().text(),
changeStr2Num(div.select(".tabbox1 dd:nth-child(2) div.dd-div2").first().text()),
changeStr2Num(div.select(".tabbox1 dd:nth-child(3) div.dd-div2").first().text()),
changeStr2Num(div.select(".tabbox1 dd:nth-child(4) div.dd-div2").first().text()),
div.select(".tabbox2 dd:nth-child(2) > div.dd-div1").first().text(),
div.select(".tabbox2 dd:nth-child(2) > div.dd-div3").first().text(),
div.select(".tabbox2 dd:nth-child(3) > div.dd-div1").first().text(),
div.select(".tabbox2 dd:nth-child(3) > div.dd-div3").first().text(),
div.select(".tabbox2 dd:nth-child(4) > div.dd-div1").first().text(),
div.select(".tabbox2 dd:nth-child(4) > div.dd-div3").first().text(),
null,
new Date(),
new Date());
return carTestModel;
}
/**
* 解析传递进来的元素,下载评测图片
* @param div
* @return 下载后的图片名字
*/
private String getCarImage(Element div){
//声明存放图片的集合
List<String> images = new ArrayList<>();
//获取图的url地址
Elements page = div.select("ul.piclist02 li");
//遍历评测图片的元素
for (Element element : page) {
//获取评测图片的展示地址
String imagePage = "https:" + element.select("a").attr("href");
//获取图片展示页面
String html = apiService.getHtml(imagePage);
//解析图片展示页面
Document dom = Jsoup.parse(html);
//获取图片地址
String imageUrl ="https:" + dom.getElementById("img").attr("src");
//下载图片并返回图片名称
String imageName = apiService.getImage(imageUrl);
images.add(imageName);
}
return ArrayUtils.toString(images);
}
/**
* 把字符串最后一个字符去掉,转为数字,再乘以1000
* @param str
*/
private long changeStr2Num(String str){
String substring = StringUtils.substring(str, 0, str.length() - 1);
substring = isNumeric(substring.trim())?substring.trim():"0";
//把字符串转为小数,必须用Number接收,否则会有精度丢失的问题
Number num = substring.isEmpty() ? 0 : Double.parseDouble(substring.trim())*1000;
return num.longValue();
}
/**
* 判断字符串是否为数字
* @param str
* @return
*/
public boolean isNumeric(String str) {
//看它是否能转化为一个数
try {
double db=Double.parseDouble(str);
} catch (Exception e) {
return false;
}
return true;
}
}
当测试通过后就可以用定时任务开始遍历这些逻辑代码了
5. 编写自动爬取数据的定时任务
- 给定时任务中添加一个新的触发器
package cn.helin9s.crawler.autohome.crawlerautohome.config;
import cn.helin9s.crawler.autohome.crawlerautohome.config.job.CloseConnectJob;
import cn.helin9s.crawler.autohome.crawlerautohome.config.job.CrawlerAutohomeJobBean;
import org.quartz.Trigger;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.quartz.CronTriggerFactoryBean;
import org.springframework.scheduling.quartz.JobDetailFactoryBean;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;
/**
* @author helin
* @project crawler-autohome
* @package cn.helin9s.crawler.autohome.crawlerautohome.config
* @description @TODO
* @create 2020-01-01 22:42
*/
@Configuration
public class SchedledCfg {
/**
* 获取spring容器
* @return
*/
@Bean("crawlerAutohomeJobBean")
public JobDetailFactoryBean crawlerAutohomeJobBean(){
//创建任务描述的工厂bean
JobDetailFactoryBean jb = new JobDetailFactoryBean();
//设置spirng容器的key,任务中可以根据这个key获取spring容器
jb.setApplicationContextJobDataKey("context");
//设置任务
jb.setJobClass(CrawlerAutohomeJobBean.class);
//设置当没有触发器和任务绑定,不会删除任务
jb.setDurability(true);
return jb;
}
/**
* 定义数据爬取的触发器
* //@Qualifier注解是通过名字注入bean,
* @return
*/
@Bean("crawlerAutohomeJobTrigger")
public CronTriggerFactoryBean crawlerAutohomeJobTrigger(
@Qualifier(value = "crawlerAutohomeJobBean") JobDetailFactoryBean itemJobBean){
//创建一个表达式触发器工厂bean
CronTriggerFactoryBean cronTriggerFactoryBean = new CronTriggerFactoryBean();
//设置任务描述到触发器
cronTriggerFactoryBean.setJobDetail(itemJobBean.getObject());
//设置Cron表达式(从第0秒开始每隔5秒执行一次)
cronTriggerFactoryBean.setCronExpression("0/5 * * * * ? ");
return cronTriggerFactoryBean;
}
/**
* 定义关闭无效连接任务
* @return
*/
@Bean("closeConnectJobBean")
public JobDetailFactoryBean jobDetailFactoryBean(){
//创建任务描述的工厂bean
JobDetailFactoryBean jb = new JobDetailFactoryBean();
//设置spirng容器的key,任务中可以根据这个key获取spring容器
jb.setApplicationContextJobDataKey("context");
//设置任务
jb.setJobClass(CloseConnectJob.class);
//设置当没有触发器和任务绑定,不会删除任务
jb.setDurability(true);
return jb;
}
/**
* 定义关闭无效连接触发器
* //@Qualifier注解是通过名字注入bean,
* @return
*/
@Bean("closeConnectJobTrigger")
public CronTriggerFactoryBean cronTriggerFactoryBean(
@Qualifier(value = "closeConnectJobBean") JobDetailFactoryBean itemJobBean){
//创建一个表达式触发器工厂bean
CronTriggerFactoryBean cronTriggerFactoryBean = new CronTriggerFactoryBean();
//设置任务描述到触发器
cronTriggerFactoryBean.setJobDetail(itemJobBean.getObject());
//设置Cron表达式(从第0秒开始每隔5秒执行一次)
cronTriggerFactoryBean.setCronExpression("0/5 * * * * ? ");
return cronTriggerFactoryBean;
}
/**
* 定义调度器
* @return
*/
@Bean
public SchedulerFactoryBean schedulerFactoryBean(Trigger[] cronTriggerImpl){
//创建任务调度器的工厂bean
SchedulerFactoryBean bean = new SchedulerFactoryBean();
//给任务调度器设置触发器
bean.setTriggers(cronTriggerImpl);
return bean;
}
}
- 编写一个新的定时任务,循环爬取所有页面的数据
package cn.helin9s.crawler.autohome.crawlerautohome.config.job;
import cn.helin9s.crawler.autohome.crawlerautohome.pojo.model.CarTestModel;
import cn.helin9s.crawler.autohome.crawlerautohome.service.ApiService;
import cn.helin9s.crawler.autohome.crawlerautohome.service.ICarTestService;
import cn.helin9s.crawler.autohome.crawlerautohome.util.TitleFilter;
import org.apache.commons.lang3.ArrayUtils;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.quartz.DisallowConcurrentExecution;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.scheduling.quartz.QuartzJobBean;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* @author helin
* @project crawler-autohome
* @package cn.helin9s.crawler.autohome.crawlerautohome.config.job
* @description @TODO
* @create 2020-01-04 15:51
*/
//当前任务没有结束不开启下一个任务
@DisallowConcurrentExecution
public class CrawlerAutohomeJobBean extends QuartzJobBean {
@Autowired
private ApiService apiService;
@Autowired
private ICarTestService carTestService;
@Autowired
private TitleFilter titleFilter;
public static final String URL="https://www.autohome.com.cn/bestauto/";
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
//获取spring容器
ApplicationContext applicationContext =(ApplicationContext) context.getJobDetail().getJobDataMap().get("context");
this.apiService = applicationContext.getBean(ApiService.class);
this.carTestService= applicationContext.getBean(ICarTestService.class);
this.titleFilter= applicationContext.getBean(TitleFilter.class);
//循环165页并爬取其中数据
for (int i = 1; i <= 165; i++) {
try {
crawler(URL+i);
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 解析并保存数据
* @param url
* @throws IOException
*/
private void crawler(String url) throws IOException {
//todo 1.使用apiService爬取数据
String html=apiService.getHtml(url);
//todo 2.使用jsoup解析页面
Document dom = Jsoup.parse(html);
//todo 3.获取所有评测的div
Elements divs = dom.select("#bestautocontent div.uibox");
//todo 4.遍历当前页所有评测数据
for (Element div : divs) {
//去重过滤,重复的数据就不需要再处理了
String title = div.select("div.uibox-title").first().text();
if (titleFilter.contains(title)){
//如果数据存在,表示重复,进行下次遍历
continue;
}
//解析页面,获取评测数据对象
CarTestModel carTestModel = getCarTestModel(div);
//解析页面,下载车辆评测图片
String carImage = getCarImage(div);
//把汽车数据存到数据库
carTestModel.setImage(carImage);
carTestService.save(carTestModel);
}
}
/**
* 解析传递进来的元素,封装为汽车评测对象
* @param div
* @return
*/
private CarTestModel getCarTestModel(Element div){
CarTestModel carTestModel = new CarTestModel(null,
div.select("div.uibox-title").first().text(),
changeStr2Num(div.select(".tabbox1 dd:nth-child(2) div.dd-div2").first().text()),
changeStr2Num(div.select(".tabbox1 dd:nth-child(3) div.dd-div2").first().text()),
changeStr2Num(div.select(".tabbox1 dd:nth-child(4) div.dd-div2").first().text()),
div.select(".tabbox2 dd:nth-child(2) > div.dd-div1").first().text(),
div.select(".tabbox2 dd:nth-child(2) > div.dd-div3").first().text(),
div.select(".tabbox2 dd:nth-child(3) > div.dd-div1").first().text(),
div.select(".tabbox2 dd:nth-child(3) > div.dd-div3").first().text(),
div.select(".tabbox2 dd:nth-child(4) > div.dd-div1").first().text(),
div.select(".tabbox2 dd:nth-child(4) > div.dd-div3").first().text(),
null,
new Date(),
new Date());
return carTestModel;
}
/**
* 解析传递进来的元素,下载评测图片
* @param div
* @return 下载后的图片名字
*/
private String getCarImage(Element div){
//声明存放图片的集合
List<String> images = new ArrayList<>();
//获取图的url地址
Elements page = div.select("ul.piclist02 li");
//遍历评测图片的元素
for (Element element : page) {
//获取评测图片的展示地址
String imagePage = "https:" + element.select("a").attr("href");
//获取图片展示页面
String html = apiService.getHtml(imagePage);
//解析图片展示页面
Document dom = Jsoup.parse(html);
//获取图片地址
String imageUrl ="https:" + dom.getElementById("img").attr("src");
//下载图片并返回图片名称
String imageName = apiService.getImage(imageUrl);
images.add(imageName);
}
return ArrayUtils.toString(images);
}
/**
* 把字符串最后一个字符去掉,转为数字,再乘以1000
* @param str
*/
private long changeStr2Num(String str){
String substring = StringUtils.substring(str, 0, str.length() - 1);
substring = isNumeric(substring.trim())?substring.trim():"0";
//把字符串转为小数,必须用Number接收,否则会有精度丢失的问题
Number num = substring.isEmpty() ? 0 : Double.parseDouble(substring.trim())*1000;
return num.longValue();
}
/**
* 判断字符串是否为数字
* @param str
* @return
*/
public boolean isNumeric(String str) {
//看它是否能转化为一个数
try {
double db=Double.parseDouble(str);
} catch (Exception e) {
return false;
}
return true;
}
}
至此,爬虫功能以及全部开发完毕。

















 250
250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









