






 本文探讨了如何通过训练均方误差与测试均方误差理解模型性能,重点关注过拟合现象。介绍偏差-方差平衡方法,包括特征提取的训练误差修正与交叉验证,如LOOCV和K折交叉验证。此外,讲解了压缩估计(正则化)如岭回归和Lasso回归,以及如何通过PCA进行降维处理。
本文探讨了如何通过训练均方误差与测试均方误差理解模型性能,重点关注过拟合现象。介绍偏差-方差平衡方法,包括特征提取的训练误差修正与交叉验证,如LOOCV和K折交叉验证。此外,讲解了压缩估计(正则化)如岭回归和Lasso回归,以及如何通过PCA进行降维处理。
文章目录
摘要:在之前的Task中,我们构建了诸如线性回归,回归树等等的模型,了解了他们的不同优缺点,那么接下来,我们就需要学习如何进一步地优化模型,记住,我们的目的不是为了让模型在训练集效果越准越好,而是在测试集上有很好的预测效果。
直播回顾
在此之前补充前面助教留的作业:查询sklearn中树模型的参数意义:
class sklearn.tree.DecisionTreeRegressor(*,
criterion='mse',
splitter='best',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
ccp_alpha=0.0)
criterion : {“mse”, “friedman_mse”, “mae”, “poisson”}, default=”mse”
用来衡量分割质量的功能。支持的标准是均方误差的“ mse”,等于方差减少作为特征选择标准,并使用每个终端节点的均值。
“ friedman_mse”来最小化L2损失,该方法使用均方误差和弗里德曼改进分数作为潜在值分裂,
“ mae”代表平均绝对误差,它使用每个末端节点的中值使L1损失最小化;
“ poisson”则使用泊松偏差的减少来寻找分裂。
splitter : {“best”, “random”}, default=”best”
用于在每个节点上选择拆分的策略。支持的策略是“best”选择最佳拆分,“random”选择最佳随机拆分。
max_depth : int, default=None
树的最大深度。如果为None,则将节点展开,直到所有叶子都是pure的,或者直到所有叶子都包含少于min_samples_split个样本。
min_samples_split : int or float, default=2
拆分内部节点所需的最少样本数(max_depth会用到):
如果为int,则认为min_samples_split是最小值。
如果为float,min_samples_split则为分数, 是每个拆分的最小样本数。ceil(min_samples_split * n_samples)
min_weight_fraction_leaf :float, default=0.0
在叶节点处需要的最小样本数。仅在任何深度的分裂点在min_samples_leaf左分支和右分支中的每个分支上至少留下训练样本时才考虑。尤其是在回归中,这可能具有平滑模型的效果。
同样地,
如果为int,则认为min_samples_leaf是最小值。
如果为float,min_samples_leaf则为分数, 是每个节点的最小样本数。ceil(min_samples_leaf * n_samples)
max_features : int, float or {“auto”, “sqrt”, “log2”}, default=None
寻找最佳分割时要考虑的功能数量:
如果为int,则max_features在每个拆分处考虑要素。
如果为float,max_features则为小数,并 在每次拆分时考虑要素。int(max_features * n_features)
如果为“auto”,则为max_features=n_features。
如果是“ sqrt”,则max_features=sqrt(n_features)。
如果为“ log2”,则为max_features=log2(n_features)。
如果没有,则max_features=n_features。
random_state : int, RandomState instance or None, default=None
控制估算器的随机性。
max_leaf_nodes : int, default=None
max_leaf_nodes以最好的方式种植一棵树。最佳节点定义为杂质(impurity )的相对减少。如果为None,则叶节点数不受限制。
min_impurity_decrease : float, default=0.0
如果节点分裂会导致杂质(impurity )的减少大于或等于该值,则该节点将被分裂。
ccp_alpha : non-negative float, default=0.0
用于最小化成本复杂性修剪的复杂性参数。具有最大成本复杂度的子树小于ccp_alpha所选择的子树 。默认情况下,不执行修剪。有关详细信息,
训练均方误差与测试均方误差
在Task2中有提到,使用MSE均方误差作为模型的性能度量指标,
即:
M
S
E
=
1
N
∑
i
=
1
N
(
y
i
−
f
^
(
x
i
)
)
2
MSE = \frac{1}{N}\sum\limits_{i=1}^{N}(y_i -\hat{ f}(x_i))^2
MSE=N1i=1∑N(yi−f^(xi))2,其中
f
^
(
x
i
)
\hat{ f}(x_i)
f^(xi)是样本
x
i
x_i
xi应用建立的模型
f
^
\hat{f}
f^预测的结果。
如果我们所用的数据来自训练集,这个误差为训练均方误差,如果我们使用测试集的数据计算的均方误差,我们称为测试均方误差。
目标:我们建立的模型在测试集上的测试误差最小
PS:一个模型在训练均方误差很小的时候,测试均方误差不一定会同样很小
模型在训练误差很小,但是测试均方误差很大时,我们称这种情况叫模型的过拟合,如下图所示:

左图是又真实函数模拟生成的数据,用黑色曲线表示。而橙黄色曲线代表线性回归,两条光滑样条拟合用绿色和蓝色曲线表示。右图灰色曲线代表训练均方误差,红色曲线代表测试均方误差。方块分别对应左图中三种拟合的训练均方误差和测试均方误差(前提:所有方法都已使测试均方误差尽可能小)
偏差-方差的均衡方法
我们的测试均方误差的期望值可以分解为 f ^ ( x 0 ) \hat{f}(x_0) f^(x0)的方差、 f ^ ( x 0 ) \hat{f}(x_0) f^(x0)的偏差平方和误差项 ϵ \epsilon ϵ的方差。
方差
所谓模型的方差就是:用不同的数据集去估计 𝑓 时,估计函数的改变量。
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
一般来说,模型的复杂度越高,f的方差就会越大。 如加入二次项的模型的方差比线性回归模型的方差要大。
偏差
另一方面,模型的偏差是指:为了选择一个简单的模型去估计真实函数所带入的误差。假如真实的数据X与Y的关系是二次关系,但是我们选择了线性模型进行建模,那由于模型的复杂度引起的这种误差我们称为偏差,它的构成是复杂的。
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力。
“偏差-方差分解”说明:泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。给定学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小。
可以用箭靶的例子来直观感受偏差和方差,如下图所示:

假设红色的靶心区域是学习算法完美的正确预测值,蓝色点为训练数据集所训练出的模型对样本的预测值,当我们从靶心逐渐往外移动时,预测效果逐渐变差。
从上面的图片中很容易可以看到,左边一列的蓝色点比较集中,右边一列的蓝色点比较分散,它们描述的是方差的两种情况。比较集中的属于方差比较小,比较分散的属于方差比较大的情况。
我们再从蓝色点与红色靶心区域的位置关系来看,靠近红色靶心的属于偏差较小的情况,远离靶心的属于偏差较大的情况。
一般而言,增加模型的复杂度,会增加模型的方差,但是会减少模型的偏差,偏差与方差是有冲突的,这称为偏差-方差窘境(bias-variance dilemma)。我们要找到一个方差–偏差的权衡,使得测试均方误差最小。
特征提取
我们已经明确一个目标,就是:我们要选择一个测试误差达到最小的模型。但是实际上我们很难对实际的测试误差做精确的计算,因此我们要对测试误差进行估计,估计的方式有两种:训练误差修正与交叉验证。
训练误差修正
前面的讨论我们已经知道,模型越复杂,训练误差越小,测试误差先减后增。因此,我们先构造一个特征较多的模型使其过拟合,此时训练误差很小而测试误差很大,那这时我们加入关于特征个数的惩罚。因此,当我们的训练误差随着特征个数的增加而减少时,惩罚项因为特征数量的增加而增大,抑制了训练误差随着特征个数的增加而无休止地减小。
交叉验证
如果说上一中方法是间接方法,那么而交叉验证则是对测试误差的直接估计。而且在实际问题中交叉验证会用得更多。交叉认证主要分为以下三种:
The Validation Set Approach
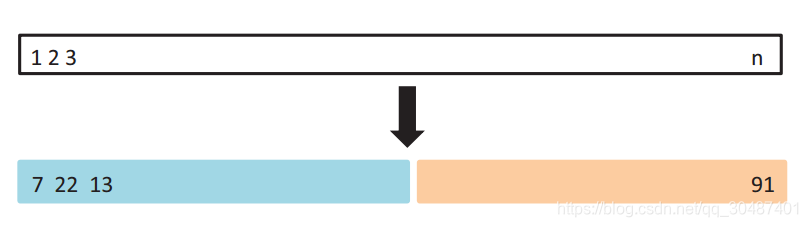
第一种是最简单的,也是很容易就想到的。我们可以把整个数据集分成两部分,一部分用于训练,一部分用于验证,这也就是我们经常提到的训练集(training set)和测试集(test set)。不过这样简单的方法也存在极大的弊端:
1、最终模型与参数的选取将极大程度依赖于你对训练集和测试集的划分方法。
2、该方法只用了部分数据进行模型的训练
LOOCV(Leave-one-out cross-validation)
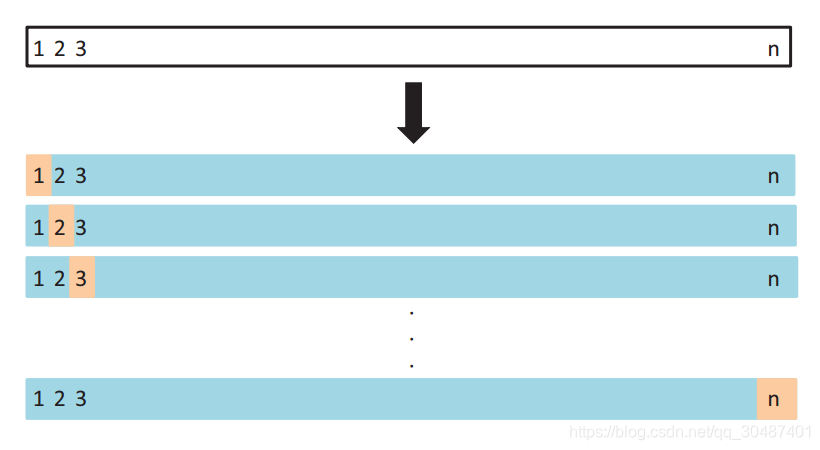
像Test set approach一样,LOOCV方法也包含将数据集分为训练集和测试集这一步骤。但是不同的是,我们现在只用一个数据作为测试集,其他的数据都作为训练集,并将此步骤重复N次(N为数据集的数据数量)。
如上图所示,假设我们现在有n个数据组成的数据集,那么LOOCV的方法就是每次取出一个数据作为测试集的唯一元素,而其他n-1个数据都作为训练集用于训练模型和调参。结果就是我们最终训练了n个模型,每次都能得到一个MSE。而计算最终test MSE则就是将这n个MSE取平均。
C
V
(
n
)
=
1
n
∑
i
=
1
n
M
S
E
i
CV_{(n)} = \frac{1}{n}\sum\limits_{i=1}^{n}MSE_i
CV(n)=n1i=1∑nMSEi
它也有很大的缺陷:计算量过大
K折交叉验证
我们把训练样本分成K等分,然后用K-1个样本集当做训练集,剩下的一份样本集为验证集去估计由K-1个样本集得到的模型的精度,这个过程重复K次取平均值得到测试误差的一个估计。
C
V
(
K
)
=
1
K
∑
i
=
1
K
M
S
E
i
CV_{(K)} = \frac{1}{K}\sum\limits_{i=1}^{K}MSE_i
CV(K)=K1i=1∑KMSEi
5折交叉验证如下图:(蓝色的是训练集,黄色的是验证集)

压缩估计(正则化)
了刚刚讨论的直接对特征自身进行选择以外,我们还可以对回归的系数进行约束或者加罚的技巧对p个特征的模型进行拟合,显著降低模型方差,这样也会提高模型的拟合效果。具体来说,就是将回归系数往零的方向压缩,这也就是为什么叫压缩估计的原因了。
岭回归
在线性回归中,我们的损失函数为 J ( w ) = ∑ i = 1 N ( y i − w 0 − ∑ j = 1 p w j x i j ) 2 J(w) = \sum\limits_{i=1}^{N}(y_i-w_0-\sum\limits_{j=1}^{p}w_jx_{ij})^2 J(w)=i=1∑N(yi−w0−j=1∑pwjxij)2,回归系数为 w ^ = ( X T X ) − 1 X T Y \hat{w} = (X^TX)^{-1}X^TY w^=(XTX)−1XTY
我们在线性回归的损失函数的基础上添加对系数的约束或者惩罚,即:
J
(
w
)
=
∑
i
=
1
N
(
y
i
−
w
0
−
∑
j
=
1
p
w
j
x
i
j
)
2
+
λ
∑
j
=
1
p
w
j
2
,
其
中
,
λ
≥
0
w
^
=
(
X
T
X
+
λ
I
)
−
1
X
T
Y
J(w) = \sum\limits_{i=1}^{N}(y_i-w_0-\sum\limits_{j=1}^{p}w_jx_{ij})^2 + \lambda\sum\limits_{j=1}^{p}w_j^2,\;\;其中,\lambda \ge 0\\ \hat{w} = (X^TX + \lambda I)^{-1}X^TY
J(w)=i=1∑N(yi−w0−j=1∑pwjxij)2+λj=1∑pwj2,其中,λ≥0w^=(XTX+λI)−1XTY
调节参数
λ
\lambda
λ的大小是影响压缩估计的关键,
λ
\lambda
λ越大,惩罚的力度越大,系数则越趋近于0,反之,选择合适的
λ
\lambda
λ对模型精度来说十分重要。岭回归通过牺牲线性回归的无偏性降低方差,有可能使得模型整体的测试误差较小,提高模型的泛化能力。
实例:
from sklearn import linear_model
reg_rid = linear_model.Ridge(alpha=.5)
reg_rid.fit(X,y)
reg_rid.score(X,y)
0.7140164719858566
Losso回归
岭回归的一个很显著的特点是:将模型的系数往零的方向压缩,但是岭回归的系数只能呢个趋于0但无法等于0,换句话说,就是无法做特征选择。能否使用压缩估计的思想做到像特征最优子集选择那样提取出重要的特征呢?答案是肯定的!我们只需要使用系数向量的L1范数替换岭回归中的L2范数:
J
(
w
)
=
∑
i
=
1
N
(
y
i
−
w
0
−
∑
j
=
1
p
w
j
x
i
j
)
2
+
λ
∑
j
=
1
p
∣
w
j
∣
,
其
中
,
λ
≥
0
J(w) = \sum\limits_{i=1}^{N}(y_i-w_0-\sum\limits_{j=1}^{p}w_jx_{ij})^2 + \lambda\sum\limits_{j=1}^{p}|w_j|,\;\;其中,\lambda \ge 0
J(w)=i=1∑N(yi−w0−j=1∑pwjxij)2+λj=1∑p∣wj∣,其中,λ≥0
实例:
from sklearn import linear_model
reg_lasso = linear_model.Lasso(alpha = 0.5)
reg_lasso.fit(X,y)
reg_lasso.score(X,y)
0.7140164719858566

椭圆形曲线为RSS等高线,菱形和圆形区域分别代表了L1和L2约束,Lsaao回归和岭回归都是在约束下的回归,因此最优的参数为椭圆形曲线与菱形和圆形区域相切的点。但是Lasso回归的约束在每个坐标轴上都有拐角,因此当RSS曲线与坐标轴相交时恰好回归系数中的某一个为0,这样就实现了特征提取。反观岭回归的约束是一个圆域,没有尖点,因此与RSS曲线相交的地方一般不会出现在坐标轴上,因此无法让某个特征的系数为0,因此无法做到特征提取。
降维
到目前为止,我们所讨论的方法对方差的控制有两种方式:一种是使用原始变量的子集,另一种是将变量系数压缩至零。但是这些方法都是基于原始特征 x 1 , . . . , x p x_1,...,x_p x1,...,xp得到的,现在我们探讨一类新的方法:将原始的特征空间投影到一个低维的空间实现变量的数量变少,如:将二维的平面投影至一维空间。
在很多算法中,降维算法成为了数据预处理的一部分,如接下来要介绍的PCA。
主成分分析(英语:Principal components analysis,PCA)是一种分析、简化数据集的技术。主成分分析经常用于减少数据集的维数,同时保持数据集中的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。由于主成分分析依赖所给数据,所以数据的准确性对分析结果影响很大。
在进行下一步推导之前,我们先把样本均值和样本协方差矩阵推广至矩阵形式:
样本均值Mean:
x
ˉ
=
1
N
∑
i
=
1
N
x
i
=
1
N
X
T
1
N
,
其
中
1
N
=
(
1
,
1
,
.
.
.
,
1
)
N
T
\bar{x} = \frac{1}{N}\sum\limits_{i=1}^{N}x_i = \frac{1}{N}X^T1_N,\;\;\;其中1_N = (1,1,...,1)_{N}^T
xˉ=N1i=1∑Nxi=N1XT1N,其中1N=(1,1,...,1)NT
样本协方差矩阵
S
2
=
1
N
∑
i
=
1
N
(
x
i
−
x
ˉ
)
(
x
i
−
x
ˉ
)
T
=
1
N
X
T
H
X
,
其
中
,
H
=
I
N
−
1
N
1
N
1
N
T
S^2 = \frac{1}{N}\sum\limits_{i=1}^{N}(x_i-\bar{x})(x_i-\bar{x})^T = \frac{1}{N}X^THX,\;\;\;其中,H = I_N - \frac{1}{N}1_N1_N^T
S2=N1i=1∑N(xi−xˉ)(xi−xˉ)T=N1XTHX,其中,H=IN−N11N1NT
最大投影方差的步骤:
(i) 中心化:
x
i
−
x
ˉ
x_i - \bar{x}
xi−xˉ
(ii) 计算每个点
x
1
,
.
.
.
,
x
N
x_1,...,x_N
x1,...,xN至
u
⃗
1
\vec{u}_1
u1方向上的投影:
(
x
i
−
x
ˉ
)
u
⃗
1
,
∣
∣
u
⃗
1
∣
∣
=
1
(x_i-\bar{x})\vec{u}_1,\;\;\;||\vec{u}_1|| = 1
(xi−xˉ)u1,∣∣u1∣∣=1
(iii) 计算投影方差:
J
=
1
N
∑
i
=
1
N
[
(
x
i
−
x
ˉ
)
T
u
⃗
1
]
2
,
∣
∣
u
⃗
1
∣
∣
=
1
J = \frac{1}{N}\sum\limits_{i=1}^{N}[(x_i-\bar{x})^T\vec{u}_1]^2,\;\;\;||\vec{u}_1|| = 1
J=N1i=1∑N[(xi−xˉ)Tu1]2,∣∣u1∣∣=1
(iv) 最大化投影方差求
u
⃗
1
\vec{u}_1
u1:
u
ˉ
1
=
a
r
g
m
a
x
u
1
1
N
∑
i
=
1
N
[
(
x
i
−
x
ˉ
)
T
u
⃗
1
]
2
s
.
t
.
u
⃗
1
T
u
⃗
1
=
1
(
u
⃗
1
往
后
不
带
向
量
符
号
)
\bar{u}_1 = argmax_{u_1}\;\;\frac{1}{N}\sum\limits_{i=1}^{N}[(x_i-\bar{x})^T\vec{u}_1]^2 \\ \;\;\;s.t. \vec{u}_1^T\vec{u}_1 = 1 (\vec{u}_1往后不带向量符号)
uˉ1=argmaxu1N1i=1∑N[(xi−xˉ)Tu1]2s.t.u1Tu1=1(u1往后不带向量符号)
得到:
J
=
1
N
∑
i
=
1
N
[
(
x
i
−
x
ˉ
)
T
u
⃗
1
]
2
=
1
N
∑
i
=
1
N
[
u
1
T
(
x
i
−
x
ˉ
)
(
x
i
−
x
ˉ
)
T
u
1
]
=
u
1
T
[
1
N
∑
i
=
1
N
(
x
i
−
x
ˉ
)
(
x
i
−
x
ˉ
)
T
]
u
1
=
u
1
T
S
2
u
1
J = \frac{1}{N}\sum\limits_{i=1}^{N}[(x_i-\bar{x})^T\vec{u}_1]^2 = \frac{1}{N}\sum\limits_{i=1}^{N}[u_1^T(x_i-\bar{x})(x_i-\bar{x})^Tu_1]\\ \; = u_1^T[\frac{1}{N}\sum\limits_{i=1}^{N}(x_i-\bar{x})(x_i - \bar{x})^T]u_1 = u_1^TS^2u_1
J=N1i=1∑N[(xi−xˉ)Tu1]2=N1i=1∑N[u1T(xi−xˉ)(xi−xˉ)Tu1]=u1T[N1i=1∑N(xi−xˉ)(xi−xˉ)T]u1=u1TS2u1
即:
u
^
1
=
a
r
g
m
a
x
u
1
u
1
T
S
2
u
1
,
s
.
t
.
u
1
T
u
1
=
1
L
(
u
1
,
λ
)
=
u
1
T
S
2
u
1
+
λ
(
1
−
u
1
T
u
1
)
∂
L
∂
u
1
=
2
S
2
u
1
−
2
λ
u
1
=
0
即
:
S
2
u
1
=
λ
u
1
\hat{u}_1 = argmax_{u_1}u_1^TS^2u_1,\;\;\;s.t.u_1^Tu_1 = 1\\ L(u_1,\lambda) = u_1^TS^2u_1 + \lambda (1-u_1^Tu_1)\\ \frac{\partial L}{\partial u_1} = 2S^2u_1-2\lambda u_1 = 0\\ 即:S^2u_1 = \lambda u_1
u^1=argmaxu1u1TS2u1,s.t.u1Tu1=1L(u1,λ)=u1TS2u1+λ(1−u1Tu1)∂u1∂L=2S2u1−2λu1=0即:S2u1=λu1
可以看到:
λ
\lambda
λ为
S
2
S^2
S2的特征值,
u
1
u_1
u1为
S
2
S^2
S2的特征向量。因此我们只需要对中心化后的协方差矩阵进行特征值分解,得到的特征向量即为投影方向。如果需要进行降维,那么只需要取p的前M个特征向量即可。
PCA的优点在于降低数据的复杂性,识别最重要的多个特征;而缺点在于可能损失有用信息。
真实的训练数据总是存在各种各样的问题:
比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余。
拿到一个数学系的本科生期末考试成绩单,里面有三列,一列是对数学的兴趣程度,一列是复习时间,还有一列是考试成绩。我们知道要学好数学,需要有浓厚的兴趣,所以第二项与第一项强相关,第三项和第二项也是强相关。那是不是可以合并第一项和第二项呢?
拿到一个样本,特征非常多,而样例特别少,这样用回归去直接拟合非常困难,容易过度拟合。比如北京的房价:假设房子的特征是(大小、位置、朝向、是否学区房、建造年代、是否二手、层数、所在层数),搞了这么多特征,结果只有不到十个房子的样例。要拟合房子特征->房价的这么多特征,就会造成过度拟合。
在信号传输过程中,由于信道不是理想的,信道另一端收到的信号会有噪音扰动,那么怎么滤去这些噪音呢?
这时可以采用主成分分析(PCA)的方法来解决部分上述问题。PCA的思想是将n维特征映射到k维上(k<n),这k维是全新的正交特征。这k维特征称为主元,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征。
小结
本task介绍了多种基础模型优化,知识点比较多,特别是特征提取中的交叉验证,之前在kaggle房价预测中有遇到过,但是现在才补上了相关基础,另外,PCA还不太能看懂,仍需在随后的直播中好好消化


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









