







工作中碰见一个问题
就是把name列的值全部替换成project的值,开始思路
UPDATE student SET NAME=project,project=NAME WHERE id IN(1,2,3,4,5)
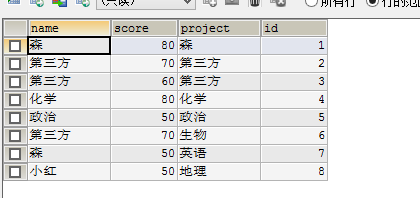
然而并没有成功出现了如图,只是把name列换成了project。第一张是原始数据,第二张是我执行完我开始思路的数据。
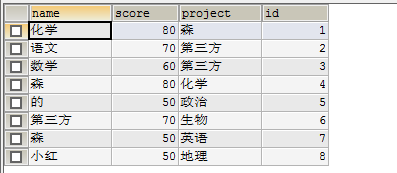
SELECT * FROM student
最后在网上查了一下
这么写可以实现
UPDATE student AS a, student AS b SET a.name=b.project, a.project=b.name WHERE a.id=b.id AND a.id IN(1,2,3);

















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









