






参考:https://www.cnblogs.com/pinard/p/10272023.html
前面讲了dqn,他是基于拟合一个能描述在某一状态采取任意动作能获得奖励大小的一个函数。如公式1:
公式1
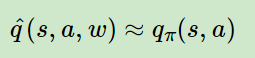
公式1这个函数的含义是:输出是分值,高表示好。s是state,a是action。
而actor-critic将这个问题更细化。具体形象化来说:有一个人,遇到不同的状态会做出不同的选择,如公式2:
公式2
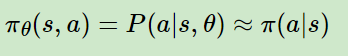
公式2表示给定状态s,一个人选择动作a的概率。
actor-critic将公式1称为critic,公式2为actor。因为公式1是评价每次行动或任意状态的分数,公式2的作用是如何选择每次的行动。
最终评价函数
评价函数只是看起来较复杂,但是其实很简单,就是算从头到位的总收益的大小:
公式3
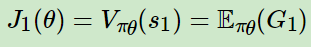
公式4
d是经过一个状态s的概率,v是这个状态的分数,因此这个公式就是p(x)*x,就是基本的求期望公式
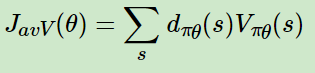
公式5
把公式4后面的那个v改成了在内部求期望值。
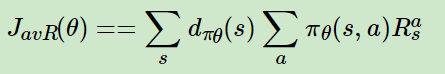
当然,公式3-5都是单纯的actor算法,当把R换成一个要拟合的神经网络以后,就变成了actor-critic算法。
actor-critic算法
虽然下面看起来很多的公式,但是区别只是R(reward)的计算方式不同,具体有哪些优缺点,这个我个人认为是个玄学问题。

实践代码
代码解读:
actor是一个很简单的网络,输出连softmax。
critic输出是分值
代码中存在的问题及解释
代码虽然可以运行,但是参考博客中并未说明更新actor的算法为什么是这样的!导致这一点拿去移植道其他地方就会感觉很迷茫。
self.neg_log_prob = tf.nn.softmax_cross_entropy_with_logits(logits=self.softmax_input,
labels=self.tf_acts)
self.exp = tf.reduce_mean(self.neg_log_prob * self.td_error)
这里为啥这么算:
其中tf_acts是一个onehot向量,这样不就是让模型拟合这个onehot向量了么?而且这个动作还是随机选的。他这个假如batch=1那肯定是错的,当batch变的很大的时候,可以认为是拟合了一种理想的情况,这个理想的情况是:处于状态s,要尝试所有的动作,然后计算所有动作的分值,最后来算loss,但是实际情况下是无法提供这种情况的,因此这样改动做一个理想情况的拟合。
#######################################################################
# Copyright (C) #
# 2016 - 2019 Pinard Liu(liujianping-ok@163.com) #
# https://www.cnblogs.com/pinard #
# Permission given to modify the code as long as you keep this #
# declaration at the top #
#######################################################################
## https://www.cnblogs.com/pinard/p/10272023.html ##
## 强化学习(十四) Actor-Critic ##
import gym
import tensorflow as tf
import numpy as np
import random
from collections import deque
# Hyper Parameters
GAMMA = 0.95 # discount factor
LEARNING_RATE = 0.01
class Actor():
def __init__(self, env, sess):
# init some parameters
self.time_step = 0
self.state_dim = env.observation_space.shape[0]
self.action_dim = env.action_space.n
self.create_softmax_network()
# Init session
self.session = sess
self.session.run(tf.global_variables_initializer())
def create_softmax_network(self):
# network weights
W1 = self.weight_variable([self.state_dim, 20])
b1 = self.bias_variable([20])
W2 = self.weight_variable([20, self.action_dim])
b2 = self.bias_variable([self.action_dim])
# input layer
self.state_input = tf.placeholder("float", [None, self.state_dim])
self.tf_acts = tf.placeholder(tf.int32, [None, 2], name="actions_num")
self.td_error = tf.placeholder(tf.float32, None, "td_error") # TD_error
# hidden layers
h_layer = tf.nn.relu(tf.matmul(self.state_input, W1) + b1)
# softmax layer
self.softmax_input = tf.matmul(h_layer, W2) + b2
# softmax output
self.all_act_prob = tf.nn.softmax(self.softmax_input, name='act_prob')
self.neg_log_prob = tf.nn.softmax_cross_entropy_with_logits(logits=self.softmax_input,
labels=self.tf_acts)
self.exp = tf.reduce_mean(self.neg_log_prob * self.td_error)
# 这里需要最大化当前策略的价值,因此需要最大化self.exp,即最小化-self.exp
self.train_op = tf.train.AdamOptimizer(LEARNING_RATE).minimize(-self.exp)
def weight_variable(self, shape):
initial = tf.truncated_normal(shape)
return tf.Variable(initial)
def bias_variable(self, shape):
initial = tf.constant(0.01, shape=shape)
return tf.Variable(initial)
def choose_action(self, observation):
prob_weights = self.session.run(self.all_act_prob, feed_dict={self.state_input: observation[np.newaxis, :]})
action = np.random.choice(range(prob_weights.shape[1]),
p=prob_weights.ravel()) # select action w.r.t the actions prob
return action
def learn(self, state, action, td_error):
s = state[np.newaxis, :]
one_hot_action = np.zeros(self.action_dim)
one_hot_action[action] = 1
a = one_hot_action[np.newaxis, :]
# train on episode
self.session.run(self.train_op, feed_dict={
self.state_input: s,
self.tf_acts: a,
self.td_error: td_error,
})
EPSILON = 0.01 # final value of epsilon
REPLAY_SIZE = 10000 # experience replay buffer size
BATCH_SIZE = 32 # size of minibatch
REPLACE_TARGET_FREQ = 10 # frequency to update target Q network
class Critic():
def __init__(self, env, sess):
# init some parameters
self.time_step = 0
self.epsilon = EPSILON
self.state_dim = env.observation_space.shape[0]
self.action_dim = env.action_space.n
self.create_Q_network()
self.create_training_method()
# Init session
self.session = sess
self.session.run(tf.global_variables_initializer())
def create_Q_network(self):
# network weights
W1q = self.weight_variable([self.state_dim, 20])
b1q = self.bias_variable([20])
W2q = self.weight_variable([20, 1])
b2q = self.bias_variable([1])
self.state_input = tf.placeholder(tf.float32, [1, self.state_dim], "state")
# hidden layers
h_layerq = tf.nn.relu(tf.matmul(self.state_input, W1q) + b1q)
# Q Value layer
self.Q_value = tf.matmul(h_layerq, W2q) + b2q
def create_training_method(self):
self.next_value = tf.placeholder(tf.float32, [1, 1], "v_next")
self.reward = tf.placeholder(tf.float32, None, 'reward')
with tf.variable_scope('squared_TD_error'):
self.td_error = self.reward + GAMMA * self.next_value - self.Q_value
self.loss = tf.square(self.td_error)
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(self.epsilon).minimize(self.loss)
def train_Q_network(self, state, reward, next_state):
s, s_ = state[np.newaxis, :], next_state[np.newaxis, :]
v_ = self.session.run(self.Q_value, {self.state_input: s_})
td_error, _ = self.session.run([self.td_error, self.train_op],
{self.state_input: s, self.next_value: v_, self.reward: reward})
return td_error
def weight_variable(self, shape):
initial = tf.truncated_normal(shape)
return tf.Variable(initial)
def bias_variable(self, shape):
initial = tf.constant(0.01, shape=shape)
return tf.Variable(initial)
# Hyper Parameters
ENV_NAME = 'CartPole-v0'
EPISODE = 3000 # Episode limitation
STEP = 3000 # Step limitation in an episode
TEST = 10 # The number of experiment test every 100 episode
def main():
# initialize OpenAI Gym env and dqn agent
sess = tf.InteractiveSession()
env = gym.make(ENV_NAME)
actor = Actor(env, sess)
critic = Critic(env, sess)
for episode in range(EPISODE):
# initialize task
state = env.reset()
# Train
for step in range(STEP):
action = actor.choose_action(state) # e-greedy action for train
next_state, reward, done, _ = env.step(action)
td_error = critic.train_Q_network(state, reward, next_state) # gradient = grad[r + gamma * V(s_) - V(s)]
actor.learn(state, action, td_error) # true_gradient = grad[logPi(s,a) * td_error]
state = next_state
if done:
break
# Test every 100 episodes
if episode % 100 == 0:
total_reward = 0
for i in range(TEST):
state = env.reset()
for j in range(STEP):
env.render()
action = actor.choose_action(state) # direct action for test
state, reward, done, _ = env.step(action)
total_reward += reward
if done:
break
ave_reward = total_reward / TEST
print('episode: ', episode, 'Evaluation Average Reward:', ave_reward)
if __name__ == '__main__':
main()

















 4682
4682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









