






目录
1 VOC数据
2.COCO数据
1.VOC数据
VOC数据集全称Visual Object Classes(视觉对象类别)数据集,是一个广泛应用于计算机视觉领域的数据集,特别是在目标检测、图像分割和图像分类等任务中。VOC数据集最初由英国牛津大学的计算机视觉小组创建,并在PASCAL VOC挑战赛中使用,该数据包含大量的带有标注信息的图像,用于训练和评估图像识别算法。VOC数据集涵盖了多个年度的发布,每个年度都包含了训练集、验证集和测试集。
VOC数据集下载————百度飞桨
VOCdevkit_数据集-飞桨AI Studio星河社区![]() https://aistudio.baidu.com/datasetdetail/28147包含VOC2007和VOC2012两个年份的。
https://aistudio.baidu.com/datasetdetail/28147包含VOC2007和VOC2012两个年份的。
以VOC2007为例,进行介绍。
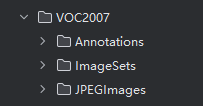
图1 VOC数据集介绍
其中Annotation,存放的是文件的注解,包含bbox和种类,图片id等等。文件格式为xml格式。
ImagesSets,存放的是数据集的划分,train,test,val。其中trainval文件没有用。
JPEGImages,存放的是图片
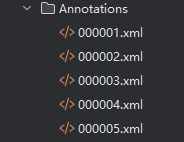
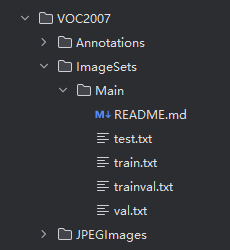
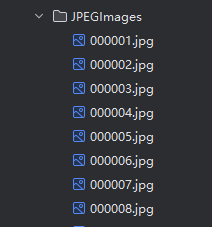
图2 VOC数据集详细介绍
2. COCO数据集
COCO(Common Objects in Context)数据集是一个大型的、丰富的图像数据集,广泛用与计算机视觉领域,特别是目标检测、分割、姿态估计和图像标题生成等任务。COCO数据集由微软提供,旨在推动场景理解的研究。
以印刷版电路PCB数据集为例进行介绍
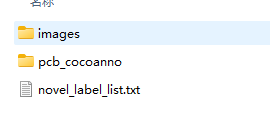
图3 pcb数据集介绍
其中,images文件夹,存放的是图片。每张图片的文件名包含类型。
pcbcocoanno文件夹,存放的是文件的分割和注解。json文件是一种轻量级的数据交换格式,其设计初衷是使之易于阅读和编写,并且便于机器解析和生成。

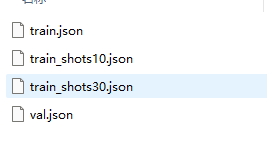
3. 数据格式转换
(1)coco转voc(此代码是将json转换为xml)
from xml.dom import minidom
import json
import glob
import os
from shutil import copyfile
def Convert_coco_to_voc(annotation_path, JPEGImage_path, out_path):
'''
将coco数据转换为voc数据
:param annotation_path:coco标记文件的地址
:param JPEGImage_path: coco图片数据集的位置
:param out_path: 生成的voc数据集保存的位置
:return:
'''
# 先创建voc输出文件夹标准格式
outdir = out_path
# 创建各级文件夹
train_xml_out = os.path.join(outdir, 'VOC2007/Annotations')
if not os.path.exists(train_xml_out):
os.makedirs(train_xml_out)
train_img_out = os.path.join(outdir, 'VOC2007/JPEGImages')
if not os.path.exists(train_img_out):
os.makedirs(train_img_out)
data = json.load(open(annotation_path, 'r'))
imgs = data['images']
annotations = data['annotations']
categories = data["categories"]
cate_list = list()
print('JSON文件中_图片总数:' + str(len(imgs)))
for i in range(len(categories)):
for ca in categories:
if ca["id"] == i:
cate_list.append(ca["name"]) # 修改这里,使用"name"而不是"supercategory"
print("JSON文件中_标注类别:" + str(cate_list))
# 遍历图片json列表
for img in imgs:
filename = img['file_name']
print(filename)
img_w = img['width']
img_h = img['height']
img_id = img['id']
ana_txt_name = filename.split('.')[0] + '.txt'
roi_list = list()
# 遍历图片标注信息列表
for ann in annotations:
if ann['image_id'] == img_id:
# 图片和标记匹配
box = convert_boxshape((img_w, img_h), ann['bbox'])
roi_list.append([cate_list[ann['category_id']], box[0], box[1], box[2], box[3]])
print(box)
get_xml(filename, [img_w, img_h, 3], roi_list, train_xml_out)
copyfile(os.path.join(JPEGImage_path, filename), os.path.join(train_img_out, filename))
def convert_boxshape(size, box):
'''
coco数据集标注是xmin,ymin,width,height 而voc和yolo是xmin ymin xmax ynax 需要进行转换
:param size: 图片宽 图片高
:param box:
:return:
'''
dw = size[0] # 图像实际宽度
dh = size[1] # 图像实际高度
x = box[0] # 标注区域X坐标
y = box[1] # 标注区域Y坐标
w = box[2] # 标注区域宽度
h = box[3] # 标注区域高度
xmin = int(x)
ymin = int(y)
xmax = int(x + w)
ymax = int(y + h)
return (xmin, ymin, xmax, ymax)
def get_xml(img_name, size, roi, outpath):
'''
传入每张图片的名称 大小 和标记点列表生成和图片名相同的xml标记文件
:param img_name: 图片名称
:param size:[width,height,depth]
:param roi:[["label1",xmin,ymin,xmax,ymax]["label2",xmin,ymin,xmax,ymax].....]
:return:
'''
impl = minidom.getDOMImplementation()
doc = impl.createDocument(None, None, None)
# 创建根节点
orderlist = doc.createElement("annotation")
doc.appendChild(orderlist)
# c创建二级节点
filename = doc.createElement("filename")
filename.appendChild(doc.createTextNode(img_name))
orderlist.appendChild(filename)
# size节点
sizes = doc.createElement("size")
width = doc.createElement("width")
width.appendChild(doc.createTextNode(str(size[0])))
height = doc.createElement("height")
height.appendChild(doc.createTextNode(str(size[1])))
depth = doc.createElement("depth")
depth.appendChild(doc.createTextNode(str(size[2])))
sizes.appendChild(width)
sizes.appendChild(height)
sizes.appendChild(depth)
orderlist.appendChild(sizes)
# object 节点
for ri in roi:
object = doc.createElement("object")
name = doc.createElement("name")
name.appendChild(doc.createTextNode(ri[0]))
object.appendChild(name)
bndbox = doc.createElement("bndbox")
xmin = doc.createElement("xmin")
xmin.appendChild(doc.createTextNode(str(ri[1])))
bndbox.appendChild(xmin)
ymin = doc.createElement("ymin")
ymin.appendChild(doc.createTextNode(str(ri[2])))
bndbox.appendChild(ymin)
xmax = doc.createElement("xmax")
xmax.appendChild(doc.createTextNode(str(ri[3])))
bndbox.appendChild(xmax)
ymax = doc.createElement("ymax")
ymax.appendChild(doc.createTextNode(str(ri[4])))
bndbox.appendChild(ymax)
object.appendChild(bndbox)
orderlist.appendChild(object)
# 将dom对象写入本地xml文件
# 打开test.xml文件 准备写入
f = open(os.path.join(outpath, img_name[:-4] + '.xml'), 'w')
# 写入文件
doc.writexml(f, addindent=' ', newl='\n')
# 关闭
f.close()
if __name__ == "__main__":
# 传入coco的annotations.json地址,image文件存放的地址 和输出的voc数据存放地址
Convert_coco_to_voc("D:\\project\\faster-rcnn-pytorch-master\\data_coco2voc\\pcb_coco\\pcb_cocoanno\\val.json",
"D:\\project\\faster-rcnn-pytorch-master\\data_coco2voc\\pcb_coco\\images",
"D:\\project\\faster-rcnn-pytorch-master\\data_coco2voc\\pcb_voc", )
def gen_txt(images_dir, output_file):
# 获取文件夹下所有文件名
filenames = os.listdir(images_dir)
# 过滤出图片文件(假设图片扩展名为jpg或png)
image_filenames = [os.path.splitext(filename)[0] for filename in filenames if filename.endswith(('.jpg', '.png'))]
# 按字母顺序排序文件名
image_filenames.sort()
# 将文件名写入txt文件
with open(output_file, 'w') as f:
for filename in image_filenames:
f.write(filename + '\n')(2)voc数据集中数据集划分,以及txt文件的生成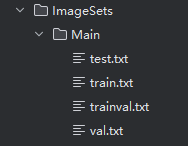
split_data.py文件代码
import os
import numpy as np
root = r"D:\project\faster-rcnn-pytorch-master\data_coco2voc\pcb_voc\VOC2007\JPEGImages"
output = r"D:\project\faster-rcnn-pytorch-master\data_coco2voc\pcb_voc\VOC2007\ImageSets\Main"
filename = []
#从存放原图的目录中遍历所有图像文件
# dirs = os.listdir(root)
for root, dir, files in os.walk(root):
for file in files:
print(file)
filename.append(file[:-4]) # 去除后缀,存储
#打乱文件名列表
np.random.shuffle(filename)
#划分训练集、测试集,默认比例6:2:2
train = filename[:int(len(filename)*0.6)]
trainval = filename[int(len(filename)*0.6):int(len(filename)*0.8)]
val = filename[int(len(filename)*0.8):]
#分别写入train.txt, test.txt
with open(os.path.join(output,'train.txt'), 'w') as f1, open(os.path.join(output,'trainval.txt'), 'w') as f2,open(os.path.join(output,'val.txt'), 'w') as f3:
for i in train:
f1.write(i + '\n')
for i in trainval:
f2.write(i + '\n')
for i in val:
f3.write(i + '\n')
print('成功!')运行voc_annotation.py文件
其中,分类的话不要自行添加序号,否则会出测。
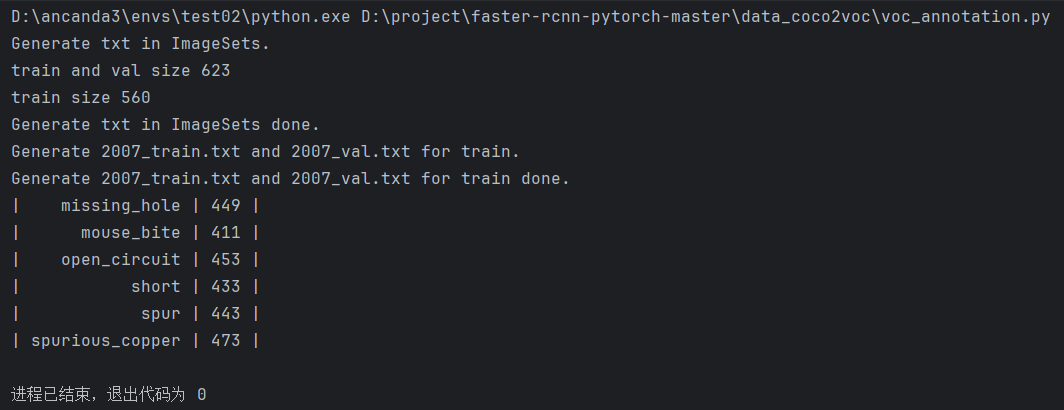
novel_label_list.txt文件内容,如下所示
missing_hole
mouse_bite
open_circuit
short
spur
spurious_copper运行代码,将生成2007_val.txt和2007_train.txt两个文件
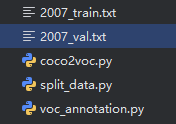
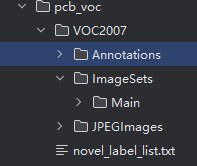
注解:其中coco2voc文件是用来将json转换为xml,并将xml文件存入Annotations文件夹下,同时将对应图片移动到JPEGImages文件夹下)
split_data文件是数据划分的。并保存在ImageSets的main文件夹下。
运行voc_annotation.py文件,软件显示界面结果
当前将coco数据转换为voc数据即完成了,可以利用本文另一篇博文训练自己的数据集了(精度不高,由于训练的轮次少)

推理结果
另外公开数据集网站
1、DataSearch :https://datasetsearch.research.google.com
2、OpenDatalab : https://opendatalab.com/
3、Kaggle :https://www.kaggle.com/
4、github:https ://github.com/Bio-Datasets/bio-datasets
5、huggingface :https://huggingface.co/datasets/arcee-ai/EvolKit-20k-vi
6、arXiv : https://arxiv.org/
7、魔搭社区:https://modelscope.cn/datasets
8、FindData:https://www.findata.cn/
9、DataCite Commons : https://commons.datacite.org/doi.org
10、MendeleyData: https://data.mendeley.com/
11、超神经:https://hyper.ai/cn
12、DataONE : https://search.dataone.org/data
13、Harvard Dataverse: https://dataverse.harvard.edu/
14、MagicHub开源社区:https://magichub.com/
15、DataCite Commons:https://commons.datacite.org/doi.org
16、Papers with Code :https://paperswithcode.com/
17、DataHub :https://datahub.io/
18:data.public.lu:https://data.public.lu/
19、帕依提提:https://www.payititi.com/
20、data.gov:https://catalog.data.gov/dataset
21、和鲸社区:https://www.heywhale.com/
22、data.europa:https://data.europa.eu/data/datasets?locale=en&minScoring=0
23、AI_Studio:https://aistudio.baidu.com/
24、Opendata cern:https://opendata.cern.ch
25、PANGAEA:https://www.pangaea.de/
26、极市:https://www.cvmart.net/
27、Roboflow:https://universe.roboflow.com/
28、IEEE:https://ieee-dataport.org/datasets
29、Stanford:http://snap.stanford.edu/data/
30、GBIF: https://www.gbif.org/dataset/search
31、阿里云天池:https://tianchi.aliyun.com/

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









