








1.硬件瓶颈
• CPU、内存、磁盘I/O、网络I/O、进程和线程
2. CPU评估:

字段说明:
Procs(进程)
- r: 运行和等待CPU时间片的进程数,如果长期大于系统CPU的个数,CPU遇到瓶颈,需要扩展CPU。
- b: 等待资源的进程数,比如正在等待磁盘I/O、网络I/O等。
Memory(内存)
- swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
- free: 空闲物理内存大小。
- buff: 用作缓冲的内存大小。
- cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。
Swap
- si: 每秒从交换区写到内存的大小,由磁盘调入内存。
- so: 每秒写入交换区的内存大小,由内存调入磁盘。
注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
IO(现在的Linux版本块的大小为1kb)
- bi: 每秒读取的块数
- bo: 每秒写入的块数
注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
system(系统)
- in: 每秒中断数,包括时钟中断。
- cs: 每秒上下文切换数。
注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
CPU(以百分比表示)
- us: 用户进程执行时间百分比(user time)
us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
- sy: 内核系统进程执行时间百分比(system time)
sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
us + sy参考值为80%,如果us + sy大于80%,说明可能存在CPU不足
- wa: IO等待时间百分比
wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
- id: 空闲时间百分比
3. 内存评估:
[root@PV-portal01 ~]# free -m
total used free shared buffers cached
Mem: 8000 7864 136 0 30 4033
-/+ buffers/cache: 3800 4200
Swap: 12191 4991 7200
• 应用程序可用内存数量: 程序可用 free + cached
– 经验值
- 应用程序可用内存/系统物理内存 > 70% 内存充足
- 应用程序可用内存/系统物理内存<20% 内存不足,需要增加内存
- 20%<应用程序可用内存/系统物理内存<70%内存基本够用
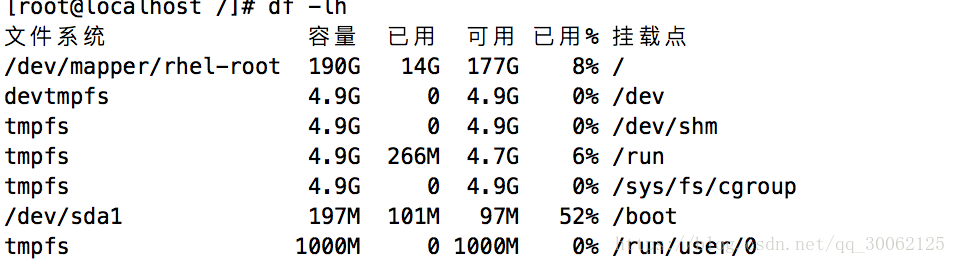
4. 磁盘评估:
iostat -d -k 1 10 #查看TPS和吞吐量信息
iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await)
iostat -c 1 10 #查看cpu状态
[root@localhost ~]# iostat -d -x -k 1

- rkB/s每秒读取数据量kB;
- wkB/s每秒写入数据量kB;
- svctm I/O请求的平均服务时间,单位毫秒;
- await I/O请求的平均等待时间,单位毫秒;值越小,性能越好;
- util 一秒中有百分几的时间用于I/O操作。接近100%时,表示磁盘带宽跑满,需 要优化程序或者增加磁盘;
- rkB/s、wkB/s根据系统应用不同会有不同的值,但有规律遵循:长期、超大数 据读写,肯定不正常,需要优化程序读取。
- svctm的值与await的值很接近,表示几乎没有I/O等待,磁盘性能好,如果await 的值远高于svctm的值,则表示I/O队列等待太长,需要优化程序或更换更快磁 盘。

- tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的。
- kB_read/s:每秒从设备(drive expressed)读取的数据量;
- kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
- kB_read:读取的总数据量;
- kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。上面的例子中,我们可以看到磁盘sda以及它的各个分区的统计数据,下面是各个分区的TPS。(因为是瞬间值,所以总TPS并不严格等于各个分区TPS的总和)
4.1 根据device找到具体的分区和目录
1.查找dm-N对应的挂载点

显示dev253-0,dev253-1,即主设备号为dev253(sda设备号为dev8,这是linux为设备生成的内部设备号),次设备号为0,1
2.查看/dev/dm-N,以及映射


即 dm-0对应 rhel-root, dm-1对应 rhel-swap
3.查看磁盘状况
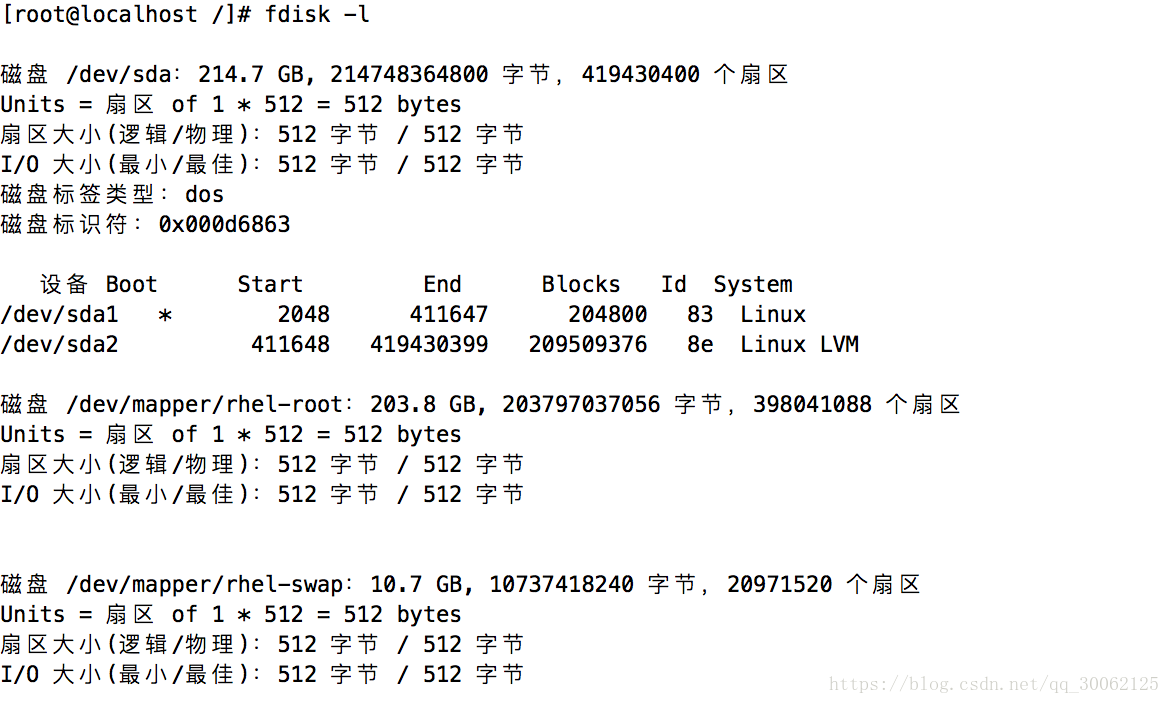
4.查看目录状况
可以看出来dm-0 对应的就是目录 /, dm-1 对应swap分区
5. 网络评估:
5.1 ifstat
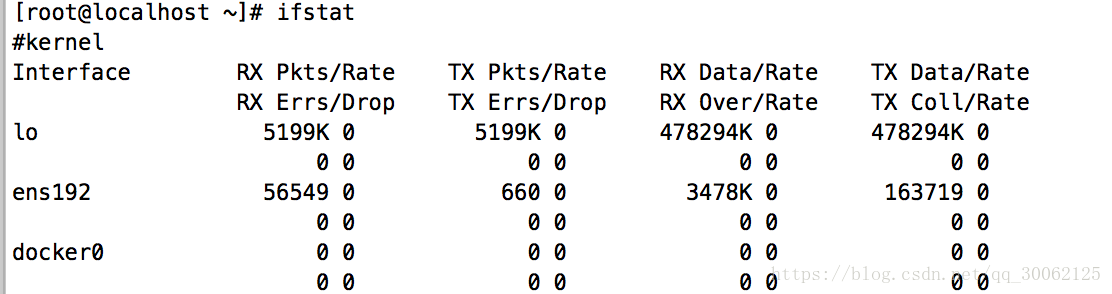
- RX Pkts/Rate 数据包接收流量(包的数量 每秒)
- RX Errs/Drop 丢包
- TX Pkts/Rate 数据包发送流量
- RX Data/Rate 数据接收流量 (字节数 每秒)
- TX Data/Rate 数据发送流量
5.2 iftop
1. yum -y install iftop
2. iftop -i ens192

- 第一行:宽带显示
- 中间部分:外部连接列表,即记录了哪些ip正在和本机的网络连接
- 中间部分右边:实时参数分别是该让问ip连接到本机2,10,40秒的平均流量
=>代表发送数据;<=代表接收数据
- 底部三行:代表发送,收到和全部网络流量
- cum:为运行iftop到目前的总流量
- peak:流量峰值
- rates:2s,10s,40s的平均流量
3.使用帮助:
iftop -h 显示帮助
iftop -F 显示指定网段/ip的进出流量
iftop -F 10.10.1.0/24
下面这些选项都可以的通过按键切换:
iftop -n 显示本机的ip,不加-n则显示主机名;也可以iftop进入监控后,按n切换是否显示ip;
iftop -t 切换显示格式为2行/1行/只显示发送的流量/只显示接收的流量
iftop -N 显示端口号或端口服务名称
iftop -S 切换是否显示本机的端口信息
iftop -D 切换是否显示远端目标主机的端口信息
iftop -P 显示端口号;或者进入iftop,按p切换是否显示端口信息
iftop -s 切换是否显示远程目标主机的host信息
iftop 按键切换显示
按p:切换是否显示端口信息
按P:切换暂停/继续显示
按T:切换是否显示每个连接的总流量
按o:切换是否固定只显示当前的连接
按l:打开屏幕过滤功能,输入要过滤的字符,比如ip,按回车后,就只能显示这个ip相关的流量信息
实现iftop -F X.X.X.X/24的功能
按j或k:可以向上或下滚动屏幕显示连接记录
按b:切换是否显示平均流量图形条
按B:切换计算2,10,40秒内的平均流量
按L:切换显示画面上边的刻度,刻度不同,流量图形条就会有变化
按1或2或3:可以根据右侧显示的三列流量数据进行排序
按<:根据左边的本机名和ip排序
按>:根据远端目标主机的主机名或ip排序
按f:编辑过滤代码,很少用
按!:可以使用shell命令,很少用
q:退出监控
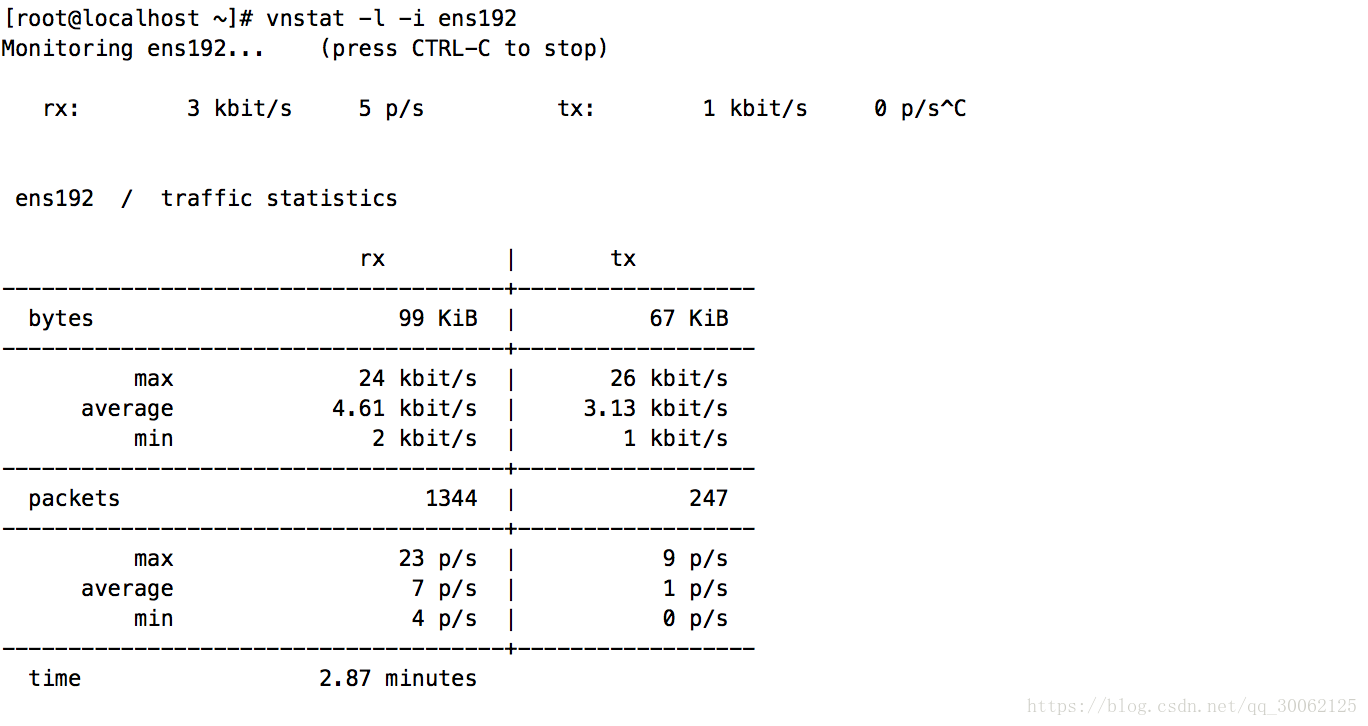
5.3 vnstat
记录指定网卡每日的传输流量日志。是通过分析文件系统/proc实现的,而非基于网络包的过滤,所以nstat不需要root权限就可以使用。
yum -y install vnstat
vnstatd -d 初始化
1. vnstat -i ens192 -h 显示每小时的流量统计,默认eth0网卡,需指定网卡
2. vnstat -l -i ens192 显示实时网卡流量
6. 进程和线程:
6.1 pidstat
cpu使用情况统计(-u)
内存使用情况统计(-r)
IO情况统计(-d)
[root@sx-sj-dportal-nengli-1 ~]# jps
25126 Jps
16189 Bootstrap
--cpu查看
[root@sx-sj-dportal-nengli-1 ~]# pidstat -p 16189 -u 1 5 -u 监控cpu
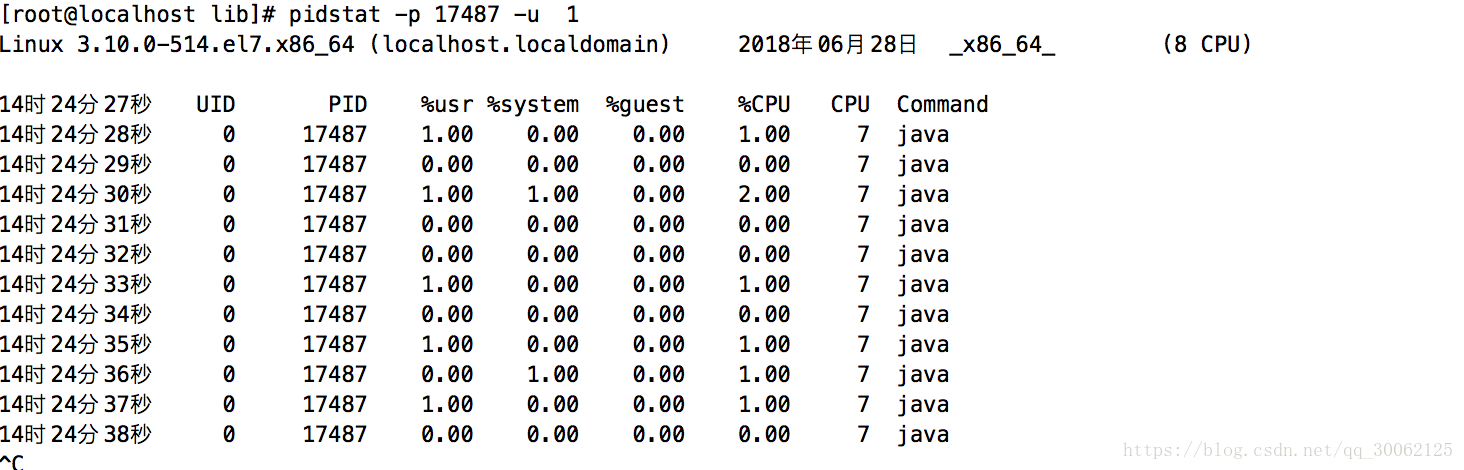
以上输出,除最开头一行显示内核版本、主机名、日期和cpu架构外,主要列含义如下:
- 09:48:12: pidstat获取信息时间点
- PID: 进程pid
- %usr: 进程在用户态运行所占cpu时间比率
- %system: 进程在内核态运行所占cpu时间比率
- %CPU: 进程运行所占cpu时间比率
- CPU: 指示进程在哪个核运行
- Command: 拉起进程对应的命令
- 执行pidstat默认输出信息为系统启动后到执行时间点的统计信息,因而即使当前某进程的cpu占用率很高,输出中的值有可能仍为0。
[root@sx-sj-dportal-nengli-1 ~]# pidstat -p 16189 -u 1 5 -t -t监控进程中的线程
Linux 3.10.0-693.11.1.el7.x86_64 (sx-sj-dportal-nengli-1.novalocal) 05/22/2018 _x86_64_ (8 CPU)
09:49:31 PM UID TGID TID %usr %system %guest %CPU CPU Command
09:49:32 PM 0 16189 - 0.00 0.00 0.00 0.00 0 java
09:49:32 PM 0 - 16189 0.00 0.00 0.00 0.00 0 |__java
09:49:32 PM 0 - 16191 0.00 0.00 0.00 0.00 1 |__java
09:49:32 PM 0 - 16192 0.00 0.00 0.00 0.00 4 |__java
09:49:32 PM 0 - 16193 0.00 0.00 0.00 0.00 0 |__java
-- 内存查看
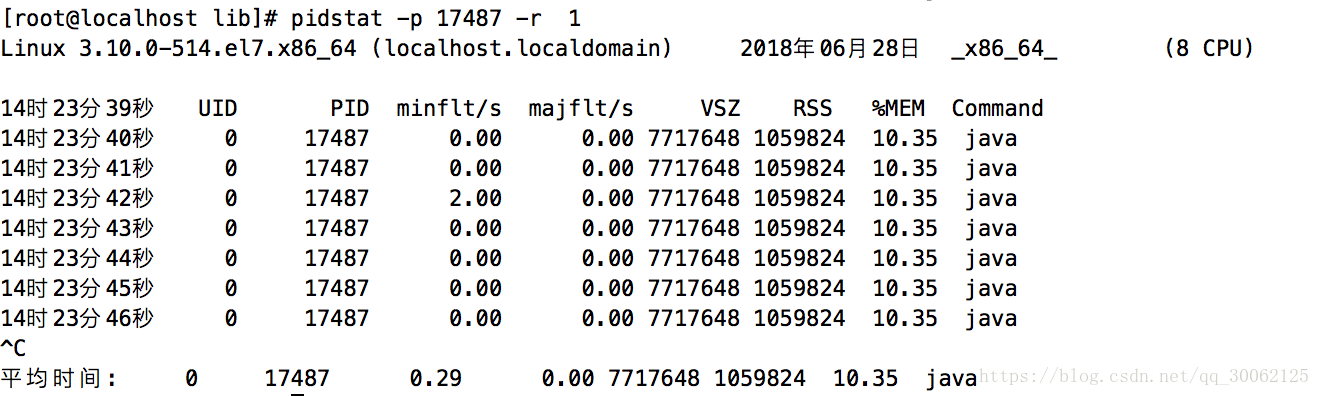
以上各列输出的含义如下:
- minflt/s: 每秒次缺页错误次数(minor page faults),次缺页错误次数意即虚拟内存地址映射成物理内存地址产生的page fault次数
- majflt/s: 每秒主缺页错误次数(major page faults),当虚拟内存地址映射成物理内存地址时,相应的page在swap中,这样的page fault为major page fault,一般在内存使用紧张时产生
- VSZ: 该进程使用的虚拟内存(以kB为单位)
- RSS: 该进程使用的物理内存(以kB为单位)
- %MEM: 该进程使用内存的百分比
- Command: 拉起进程对应的命令
--io查看
[root@mytest1 ~]# pidstat -p 18513 1 1 -d -t
Linux 3.10.0-514.el7.x86_64 (mytest1) 2018年05月22日 _x86_64_ (8 CPU)
21时54分53秒 UID TGID TID kB_rd/s kB_wr/s kB_ccwr/s Command
21时54分54秒 0 18513 - 0.00 3.96 0.00 java
21时54分54秒 0 - 18513 0.00 0.00 0.00 |__java
21时54分54秒 0 - 18514 0.00 0.00 0.00 |__java
21时54分54秒 0 - 18515 0.00 0.00 0.00 |__java
21时54分54秒 0 - 18516 0.00 0.00 0.00 |__java
21时54分54秒 0 - 18517 0.00 0.00 0.00 |__java
- kB_rd/s: 每秒进程从磁盘读取的数据量(以kB为单位)
- kB_wr/s: 每秒进程向磁盘写的数据量(以kB为单位)
- Command: 拉起进程对应的命令
7.系统负载
7.1 top
[root@master ~]# top
top - 05:34:32 up 162 days, 6:45, 5 users, load average: 0.02, 0.01, 0.00
Tasks: 244 total, 1 running, 243 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.1%us, 0.2%sy, 0.0%ni, 99.6%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 16335704k total, 7641236k used, 8694468k free, 232644k buffers
Swap: 8241144k total, 0k used, 8241144k free, 4891276k cached
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况
7.2 uptime
[root@master ~]# uptime
05:34:47 up 162 days, 6:45, 5 users, load average: 0.02, 0.01, 0.00



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











