




 本文详细介绍Solr的安装步骤、环境配置流程以及如何集成IK中文分词器。此外,还介绍了Solr的基本使用方法,包括如何进行文档的增删查操作,并提供了Spring Boot环境下SolrJ客户端的使用示例。
本文详细介绍Solr的安装步骤、环境配置流程以及如何集成IK中文分词器。此外,还介绍了Solr的基本使用方法,包括如何进行文档的增删查操作,并提供了Spring Boot环境下SolrJ客户端的使用示例。
Solr 安装和部署
- 下载 Solr 安装包并解压
- 创建 Solr 的家目录
E:\solr\solrHome - 将
D:\software\solr-x.x.x\example\solr下的所有文件拷贝到E:\solr\solrHome下 - 将
D:\software\solr-x.x.x下的contrib 和 dist拷贝到E:\solr\下,与 solrHome 同级 修改
E:\solr\solrHome\collection1\conf\solrconfig.xml<!-- 调整引用的 jar 文件的路径,这里仅给出了一对修改的样例,所有类似这样的都需要修改 引用的 jar 文件在 solrHome 同级的 contrib 和 dist 目录下 solr.install.dir:表示 collection1 所在的目录 solrHome --> <!-- 原内容: --> <lib dir="${solr.install.dir:../../../}/contrib/extraction/lib" regex=".*\.jar" /> <lib dir="${solr.install.dir:../../../}/dist/" regex="solr-cell-\d.*\.jar" /> <!-- 修改后: --> <lib dir="${solr.install.dir:../}/contrib/extraction/lib" regex=".*\.jar" /> <lib dir="${solr.install.dir:../}/dist/" regex="solr-cell-\d.*\.jar" /> <!-- 配置查询时返回的数据格式 --> <requestHandler name="/select" class="solr.SearchHandler"> <lst name="defaults"> <str name="echoParams">explicit</str> <int name="rows">10</int><!--显示数量--> <str name="wt">json</str><!--显示格式--> <str name="df">text</str><!--默认搜索字段--> </lst> </requestHandler>将
D:\software\solr-x.x.x\dist下的 solr.war 拷贝到 tomcat 的 webapps 下,改名为 solr.war,启动 tomcat- 将
D:\software\solr-x.x.x\example\lib\ext下的所有 jar 文件拷贝到 tomcat 下的webapps\solr\WEB-INF\lib 修改
webapps\solr\WEB-INF\web.xml<!-- 放开这段代码,修改 env-entry-value,如下 --> <env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>e:\solr\solrHome</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry>将
D:\software\solr-x.x.x\example\resources\log4j.properties拷贝到webapps\solr\WEB-INF\classes- 重启 tomcat,访问
http://localhost:8080/solr
配置 IK 中文分词器
- 下载 IK 中文分词器
- 将 jar 文件拷贝到
E:\solr\contrib\IKAnalyzer\lib,IKAnalyzer 和 lib 文件夹需要创建 - 将 jar 文件拷贝到 tomcat 下
webapps\solr\WEB-INF\lib - 修改
E:\solr\solrHome\collection1\conf\solrconfig.xml
<lib dir="${solr.install.dir:../}/contrib/IKAnalyzer/lib" regex=".*\.jar" />
将
IKAnalyzer.cfg.xml、stopword.dic、ext.dic拷贝到 tomcat 下webapps\solr\WEB-INF\classes,ext.dic、stopword.dic必须要UTF-8 无 BOM 格式编码<properties> <comment>IK Analyzer 扩展配置</comment> <entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">stopword.dic;</entry> </properties><!-- ext.dic 扩展词库 --> 盲僧修改
E:\solr\solrHome\collection1\conf\schema.xml<!-- IKAnalyzer--> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> <field name="stu_name" type="text_ik" indexed="true" stored="true"/> <field name="stu_scores" type="string" indexed="false" stored="true" multiValued="true"/> <field name="stu_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/> <copyField source="stu_name" dest="stu_keywords"/>
自定义 fieldType 和 field
indexed="true" 的 field 才可以当作查询条件,例如 goods_shop_id 的 indexed="false",使用 q 和 fq 查询时,什么都查不到
使用 multiValued="true" 时,这个数据是个数组
stored="true" 的 field 是存储了原数据的,就是说在检索的时候,这个 field 是可以看到的,如果使用了 store="false",则表示只将其中的字段分词,但是检索的时候,原数据不会展示
copyField 可以将多个 field 的索引整合到一个 field 中以商品信息为例:
修改schema.xml文件
<!-- 定义分词时使用的类型,这里是 IK 分词器提供的类型 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!-- 定义域,注意 type,如果属性需要分词的话,type 使用上面定义的 fieldType -->
<!-- indexed="true" 的 field 才可以当作查询条件,例如 goods_shop_id 的 indexed="false",使用 q 和 fq 查询时,什么都查不到 -->
<field name="goods_name" type="text_ik" indexed="true" stored="true"/>
<field name="goods_category_id" type="string" indexed="true" stored="true"/>
<field name="goods_category_name" type="text_ik" indexed="true" stored="true"/>
<field name="goods_price" type="float" indexed="true" stored="true"/>
<field name="goods_description" type="text_ik" indexed="true" stored="false"/>
<!-- 使用 multiValued="true" 时,这个数据是个数组 -->
<field name="goods_picture" type="string" indexed="false" stored="true" multiValued="true"/>
<field name="goods_shop_id" type="string" indexed="false" stored="true"/>
<!-- 定义关键词搜索域 -->
<field name="goods_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<!-- 定义关键词搜索域要搜索的范围,例如这里的范围是 goods_name 和 goods_description -->
<!--
例如:goods_category_name 有一条数据为“农药”,
但是 goods_category_name 的 field 有索引,但没有指向 goods_keywords ,
因此使用 q 查询时:
goods_keywords:农药
查询不出结果,
但是
goods_category_name:农药
可以查处结果,因为它的 indexed="true"
-->
<copyField source="goods_name" dest="goods_keywords"/>
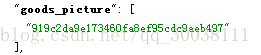
<copyField source="goods_description" dest="goods_keywords"/> goods_picture设置为multiValued="true"的效果展示,multiValued="true"这个参数一般用在copyField指向的field
Solr 解压后的文件及解释
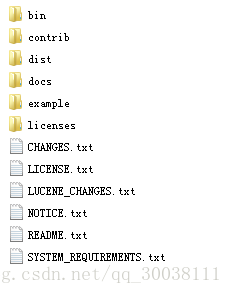
bin:可执行程序、脚本
contrib:存放了一些扩展的包,用于索引和搜索
dist:其中有一个solr-4.10.3.war 将其部署到tomcat容器中,运行solr
docs:使用说明文档
example:存储了很多solr开发使用的例子工程及目录结构等。
example/solr:
该目录是一个包含了默认配置信息的Solr的Core目录。
example/multicore:
该目录包含了在Solr的multicore中设置的多个Core目录。
example/webapps:
该目录中包括一个solr.war,该war可作为solr的运行实例工程。
licenses:solr相关的一些许可信息
licenses:许可
Solr 的查询语法
q查询关键字goods_keywords:娃哈哈 and goods_category_name:火腿fq(filter query)过滤查询,在q查询结果中过滤查询!!!注意:是在q的结果集中过滤goods_price:[1 TO 20] goods_price:[* TO 20]sort排序,格式:field_name [desc | asc],field_name [desc | asc]…start,rows分页显示,start开始记录下标,rows返回多少条,实际应用中,根据当前页码和每页条数计算开始下标start = rows * (curPage -1)fl(field list)指定返回字段,用逗号或空格分隔多个goods_price,goods_namedf指定一个搜索field,也可以在solrconfig.xml中指定默认搜索field,然后直接在q查询条件中输入关键字即可goods_keywords<requestHandler name="/select" class="solr.SearchHandler"> <lst name="defaults"> <str name="echoParams">explicit</str> <int name="rows">10</int> <str name="wt">json</str> <!-- 默认的搜索域 --> <str name="df">text</str> </lst> </requestHandler>wt(writer type)指定输出格式,可以使用xml、json、php等
SolrJ 的简单用法
这里给出范例,详解请参考solrJ的查询参数、标准查询操作符、转义字符等内容。
Springboot 注入 SolrJ 客户端
spring:
data:
solr:
host: http://127.0.0.1:8080/solr@Autowired
private SolrClient solrClient;新增:
@Test
public void testUpdate() throws SolrServerException, IOException{
// 更新或添加索引,根据 id 判断,如果 id 存在进行更新索引,如果不存在进行添加索引
// 创建 document 文档
SolrInputDocument doc = new SolrInputDocument();
// 向文档中添加域
doc.addField("id", "7758521");
doc.addField("goods_shop_id", "123456789");
doc.addField("goods_price", 666f);
doc.addField("goods_category_name", "营养快乐");
doc.addField("goods_category_id", "987654321");
doc.addField("goods_picture", "000000");
doc.addField("goods_name", "旺仔营养快乐");
solrClient.add(doc);
solrClient.commit();
}删除:
@Test
public void testUDelete() throws SolrServerException, IOException{
// 删除索引
// 按照 id 删除
// solrClient.deleteById("7758521");
// 自定义查询条件删除
solrClient.deleteByQuery("id:7758521");
solrClient.commit();
}查询:
@Test
public void testSearch() throws SolrServerException, IOException {
SolrQuery query = new SolrQuery();
// 查询关键字,q不能省略,必须写q
query.set("q", "goods_keywords:娃哈哈 and goods_category_name:火腿");
// 不等于
// query.set("q", "-goods_keywords:娃哈哈");
// 指定过虑
// query.set("fq", "product_price:[1 TO 10]");
// 要添加多个 过虑
query.add("fq", "goods_price:8");
query.add("fq", "goods_category_name:火腿");
// 过滤条件不等于
// query.add("fq", "-goods_price:8");
// 排序
// 参数:field域,排序类型(asc、desc)
query.addSort("goods_price", ORDER.desc);
// 加多个排序
// query.addSort(field, order)
// 分页
// 根据当前页码和每页显示的个数最后求出开始下标
int curPage = 1;
int rows = 15;
// 计算出开始记录下标
int start = rows * (curPage - 1);
// 向 query中设置分页参数
query.setStart(start);
query.setRows(rows);
// 指定显示的field
// query.addField("product_name");
// query.addField("id");
// 指定默认搜索域
query.set("df", "goods_keywords");
// 开启高亮
query.setHighlight(true);
// 设置高亮 参数
query.addHighlightField("goods_name");
// 可以添加多个域高亮
// query.addHighlightField(f)
// 设置高亮前缀和后缀
query.setHighlightSimplePre("<span style=\"color:red\">");
query.setHighlightSimplePost("</span>");
QueryResponse response = solrClient.query(query);
// 从响应中得到结果
SolrDocumentList docs = response.getResults();
// 匹配到的总记录数
long numFound = docs.getNumFound();
System.out.println("匹配到的总记录数:" + numFound);
// 从响应中获取高亮信息
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
for (SolrDocument doc : docs) {
System.out.println("商品id:" + doc.get("id"));
System.out.println("商品名称:" + doc.get("goods_name"));
System.out.println("商品价格:" + doc.get("goods_price"));
System.out.println("商品分类名称:" + doc.get("goods_category_name"));
System.out.println("商品图片:" + doc.get("goods_picture"));
// 要获取高亮的信息
if (highlighting != null) {
// 根据主键获取高亮信息
Map<String, List<String>> map = highlighting.get(doc.get("id"));
if (map != null) {
// 获取高亮信息
List<String> list = map.get("product_name");
if (list != null) {
System.out.println("高亮后:" + list.get(0));
}
}
}
}
}

















 2642
2642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









