




最近一篇图谱文章很火,翻来看看分享出来。
来自 1微软研究院2微软战略使命和技术部3微软首席技术官办公室 的文章。
文章标题:
From Local To Global: A Graph Rag Approach To Query-Focused Summarization
URL:https://arxiv.org/abs/2311.01011
注:翻译可能存在误差,详细内容建议查看原始文章。
摘要
使用检索增强生成 (RAG) 从外部知识源检索相关信息使大型语言模型 (LLM) 能够回答来自私有和/或之前未见过的文档集合的问题。然而,对于针对整个文本语料库的全局问题,如“数据集中的主要主题是什么?”RAG 却失败了,因为这本质上是一个查询聚焦摘要 (QFS) 任务,而不是一个明确的检索任务。与此同时,先前的 QFS 方法无法扩展到典型 RAG 系统索引的文本数量。为了结合这些对比方法的优点,作者提出了一种图 RAG 方法,用于在私有文本语料库上进行基于问题的回答,该方法可随着用户问题的一般性和待索引源文本的数量而扩展。作者的方法使用 LLM 分两个阶段构建基于图的文本索引:首先从源文档中推导出实体知识图谱,然后为所有紧密相关实体组预生成社区摘要。给定一个问题,每个社区摘要用于生成部分回答,然后将所有部分回答再次汇总为最终的回答提供给用户。对于在大约 100 万令牌范围内的数据集上的一类全局意义解析问题,作者证明了 Graph RAG 在生成答案的全面性和多样性方面相对于简单的 RAG 基线有了实质性改进。
开源、基于 Python 的图 RAG 局部和全局方法实现即将在 https://aka.ms/graphrag 发布。https://aka.ms/graphrag 也将提供开放源代码及 Python 实现版本。
1 引言
在各个领域的人类努力都依赖于作者阅读和分析大量文献的能力,常常得出超越原文本所述内容的结论。随着大型语言模型(LLMs)的出现,作者已经见证了尝试在诸如科学发现(微软,2023年)和情报分析(Ranade 和 Joshi,2023年)等复杂领域自动化类似人类的理解过程,“理解”在这里被定义为
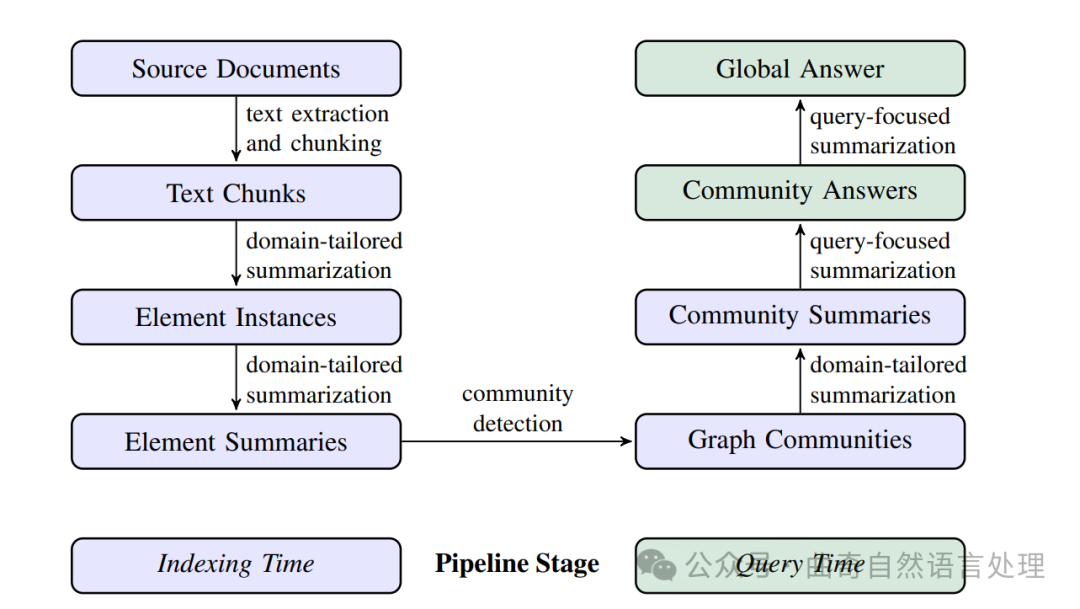
图 1:使用基于LLM的图形索引(由源文档文本生成)的RAG管道。这个索引覆盖了节点(例如,实体)、边(例如,关系)和协变量(例如,主张),它们已被检测、提取,并通过针对数据集领域定制的LLM提示进行了总结。
社区检测(例如,Leiden算法,Traag等人,2019年)用于将图形索引划分为元素组(节点、边、协变量),LLM可以在构建索引和查询时并行地对这些元素进行总结。对于给定查询的“全局答案”是通过最后一轮针对查询的总结生成的,这次总结涵盖所有报告与该查询相关性的社区摘要。
然而,要在整个文献库中支持人类引导的理解过程,需要一种方式让人既能应用又能精炼他们对数据的思维模型(Klein 等人,2006b), 通过提出具有全局性质的问题来实现。
检索增强型生成 (RAG,Lewis 等人,2020 的工作) 是回答整个数据集上用户问题的一种公认方法,但它针对的是答案在文本区域中的局部位置的情况,这些文本的检索为生成任务提供了充分的基础。
相比之下,一个更为合适的问题框架是查询聚焦摘要(QFS,Dang,2006),特别是在查询聚焦抽象性摘要的情况下,它生成自然语言摘要而不仅仅是拼接摘录(Baumel 等人,2018;Laskar 等人,2020;Yao 等人,2017)。然而近年来,在抽象性和提取性、通用性与查询聚焦,以及单文档和多文档之间的摘要任务的这些区别已经不太明显。尽管起初,Transformer 架构在所有此类摘要任务上对当前最佳表现有了实质性提高(Goodwin 等人,2020;Laskar 等人,2022;Liu 和 Lapata,2019),但这些任务如今已被现代 LLMs 例如 GPT(Achiam 等人,2023;Brown 等人,2020)、Llama(Touvron 等人,2023)和 Gemini(Anil 等人,2023 系列简化。所有这些 LLMs 都可以使用在境况中学习的方法汇总在它们的上下文窗口内提供的任何内容。然而对整个文献库进行查询聚焦抽象性摘要的挑战依然存在。如此大量的文本可能已大大超过 LLM 上下文窗口的极限,并且仅仅是扩展这样的窗口或许并不足以防止长期上下文中信息"遗失于中间"(Kuratov 等人,2024;Liu 等人,2023)。此外,尽管在传统的 RAG 中直接检索文本块对于 QFS 任务可能不足,但有可能以预索引的另类形式来支持一种特针对全局摘要的新式 RAG 方法。
在此论文中,作者提出了一种基于 LLM 构建的知识图谱全局性摘要图形 RAG(见 图 1)的方法。与利用图形索引结构检索和操作属性的相关工作不同(第 4.2 小节),作者的重点放在了在这个环境中图的未被开发的质量上:它们固有的模块化 (Newman,2006) 和使用社区检测算法将图形分割为由紧密相关的节点组成模块性社区的能力 (例如:Louvain 方法, Blondel 等人 2008; Leiden 方法 Traag 等人 2019)。"
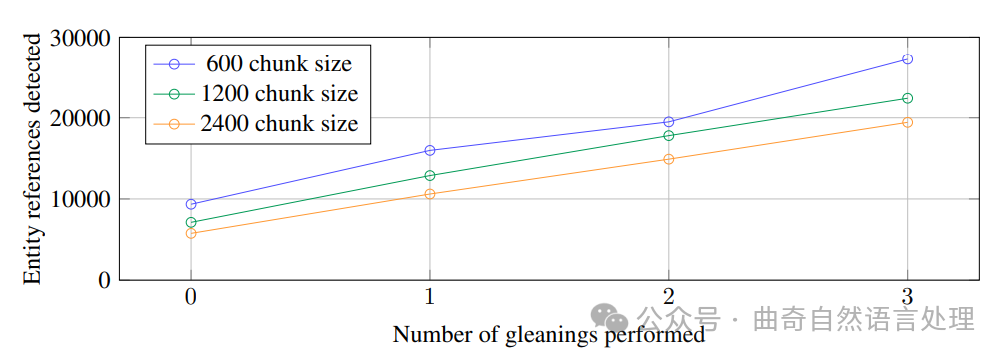
图 2:HotPotQA 数据集中检测到的实体引用(Yang 等人,2018 年)如何随着作者的通用实体提取提示与 gpt-4-turbo 的块大小和收获而变化。
社区描述提供了基础图形索引及其所代表的输入文档的完整覆盖。然后,通过映射-归约(map-reduce)方法,实现了对整个语料库以查询为中心的摘要:首先独立并行地使用每个社区摘要来回答查询,然后将所有相关的部分答案汇总成最终的全局答案。
为了评估这种方法,作者利用了LLM从两个代表性的现实世界数据集的简短描述中生成一组多样化的活动中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2646
2646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









