




 本文探讨了模仿学习中的关键概念,如observation与state的区别及其与马尔科夫性质的关系,分析了模仿学习中可能遇到的问题,如分布偏移及误差累积,并介绍了几种改进方法。
本文探讨了模仿学习中的关键概念,如observation与state的区别及其与马尔科夫性质的关系,分析了模仿学习中可能遇到的问题,如分布偏移及误差累积,并介绍了几种改进方法。
1.oto_tot与sts_tst的区别:state一般视作马尔科夫状态,而observation则result from state。使用state一般要求更为严格。一般来讲,observation更为低层,如图像;state则可以是抽象的更上一层,例如图像中的实体状态。
“States are the true configuration of the system, and the observation is something results from that state which may or may not be enough to deduce the state.”
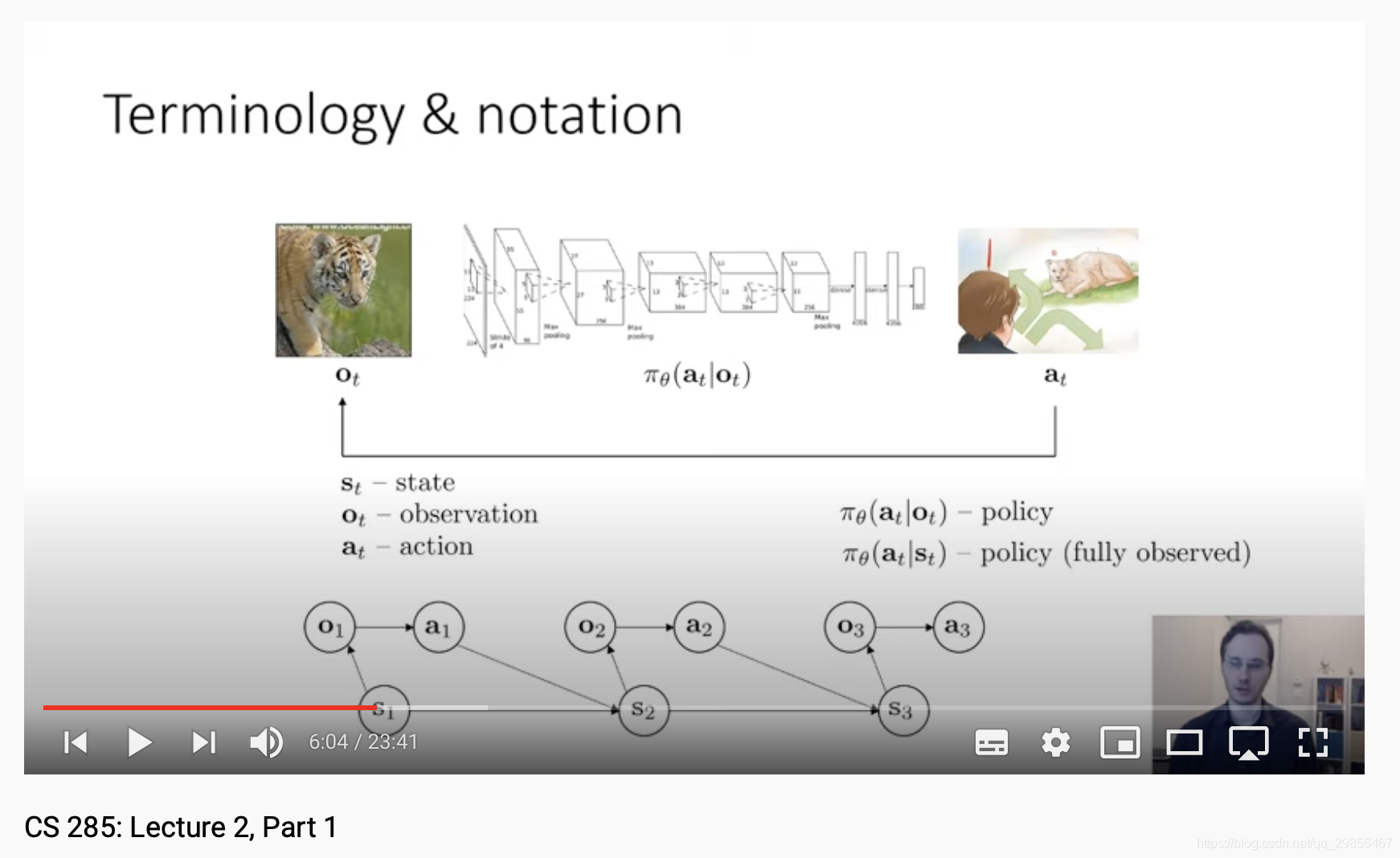
这里其实很像隐马尔科夫(HMM)了。
最关键的在于,observation一般不满足马尔科夫性质;而state可以结合pre observation,使之能够包含之前的信息,从而满足马尔科夫性质。这里感觉和RNN很像了。
2.Imitation Learning
2.1 Behavior Cloning
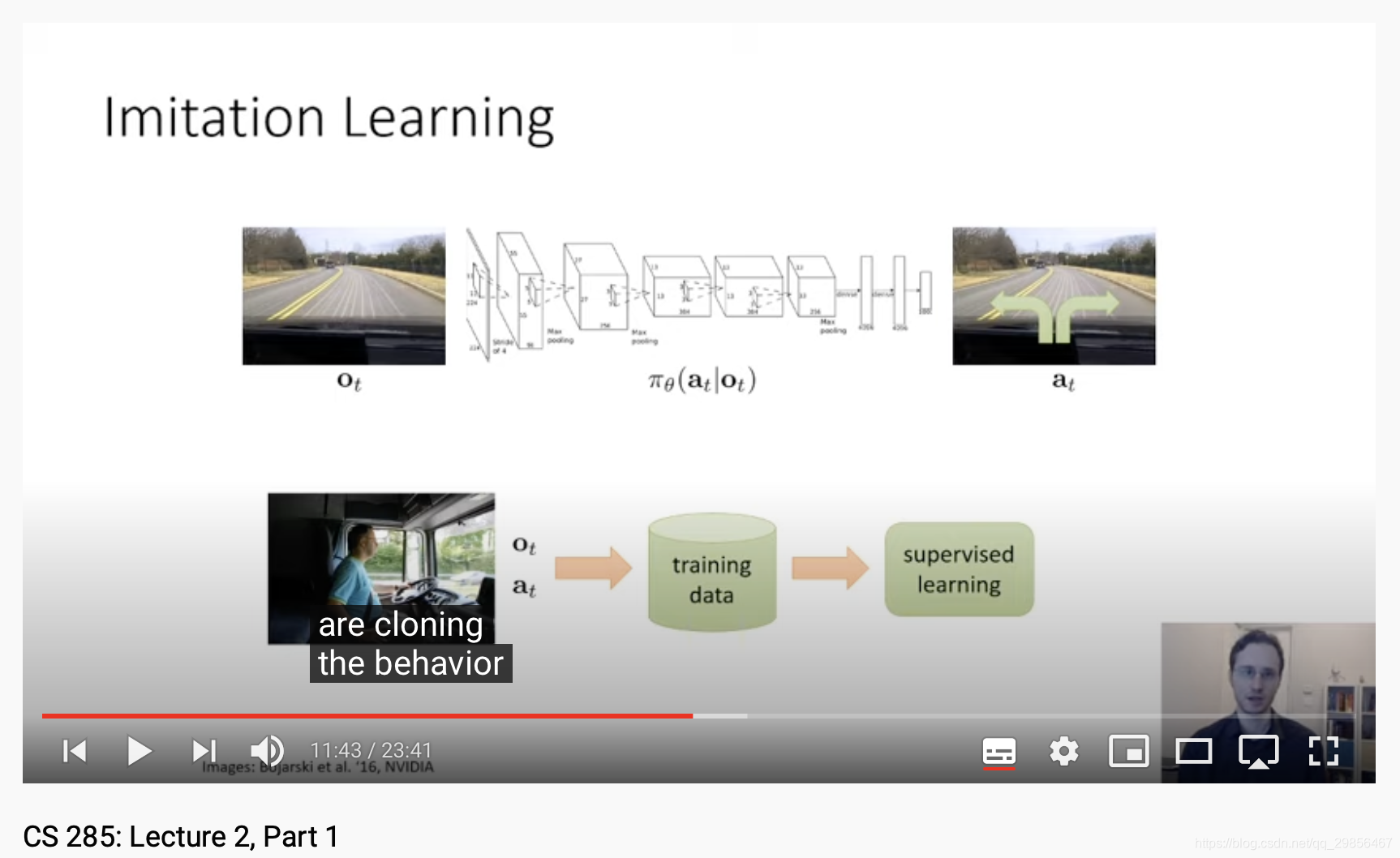
这种方法的问题在于,直接对observation到action进行了监督学习,而由observation到state往往是有误差的,但这种方法并几乎没有考虑到pre observation的前后关系,从而使误差扩大,在实际的trojectory中,最终得到较大误差。忽略时序关系导致了误差扩大。但其实有时每一步的observation很可能也与pre action相关,而pre action与pre observation相关,这从某种程度上是修正了误差。
2.2 误差产生的本质原因
通常pdata(ot)≠pπθ(ot)p_{data}(o_t) \neq p_{\pi_{\theta}}(o_t)pdata(ot)=pπθ(ot)
distributional shift
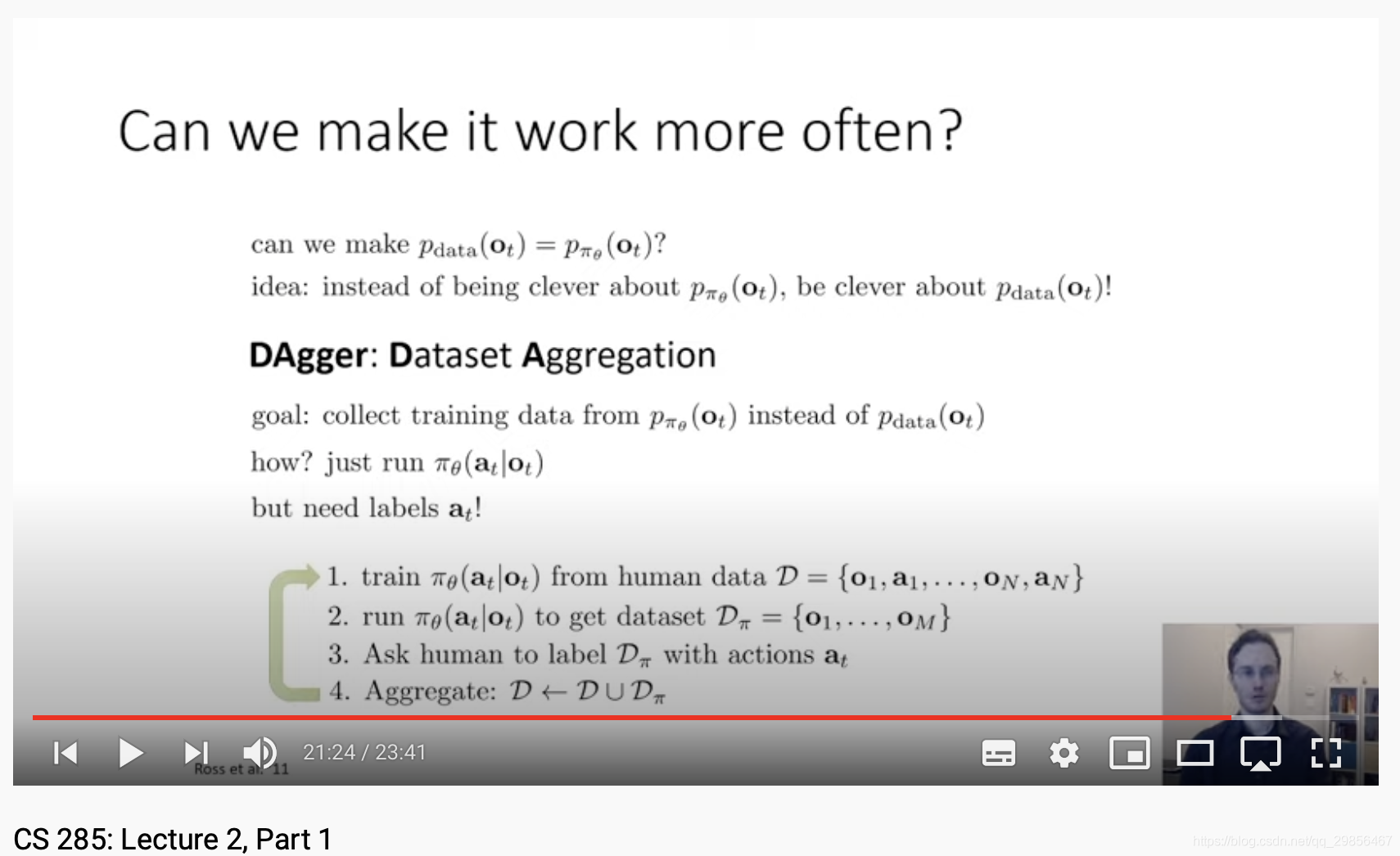
使用数据集增强(DAgger, Dataset Aggregation)
2.3 马尔科夫性质的重要性
从本质上来说,它降低了模型结果的随机性,使用了关键性的假设,使结果趋近于确定。感觉从本质上看,是使用更广泛的信息,增强了数据预测的确定性。
2.4 问题所在
非马尔科夫性,这个可以通过RNN来解决。
2.5 casual confusion
有时而外的信息会使因果分析更为confusion,反而不利于策略推断。
2.6 多模型的混合可能会带来一定的误差。
2.6.1 高斯混合模型
2.6.2 隐变量模型
2.6.3 Autogressive discretization
类似action分解搜索
3.模仿学习的另一问题在于数据
人类难以给出大量的最优的数据供模型训练。
既然如此,agent能否具有自主得到最优解数据的能力。

4.模仿学习如果发生distributional shift,则误差是O(ϵT2)O(\epsilon T^2)O(ϵT2)的。
5.Goal-conditioned behavioral cloning

















 1790
1790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









