




 本文介绍如何在Scrapy中实现携带Cookie登录、POST请求登录及设置随机User-Agent的方法,并探讨了下载中间件的使用,包括请求头和代理的设置。
本文介绍如何在Scrapy中实现携带Cookie登录、POST请求登录及设置随机User-Agent的方法,并探讨了下载中间件的使用,包括请求头和代理的设置。
携带cookie登录
在scrapy中,携带cookie需要重新定义一个start_requests方法。`
def start_requests(self):
cookies = “ ”
cookies = {i.split("=")[0]:i.split("=")[1] for i in cookies.split("; ")}
yield scrapy.Request(
self.start_urls[0],
callback=self.parse,
cookies= cookies
)
cookie是一个字典的形式,把获取下来的分割成字典。

setting此项设置为False,不会对机器人协议进行请求,让他不遵守协议。
post请求登录
在scrapy中可以通过yield scrapy.FormRequest来进行表单的提交进行登录,也可以通过yield scrapy.FormRequest.from_response来进行一个模拟登录。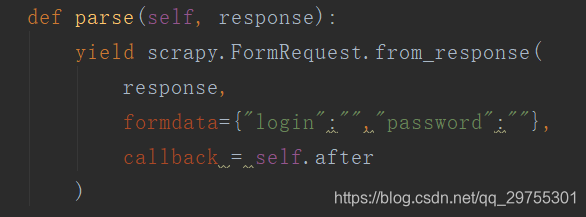
它会自动寻找表单进行数据的提交,formdata就填写账号密码即可,键名需要自己去查看下提交的input的名字来确定。
请求头的设置
下载一个scrapy-fake-useragent的包,pip安装即可,然后去setting把下载中间件打开,然后写下以下的代码
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None,# 关闭默认的方法
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware':543,# 开启
然后每次请求就会随机的user-agent。
下载中间件
建立一个middlewares的py文件,一般建项目时就存在的,然后定义类,定义方法,一般定义2个方法,分别是process_requests(self,request,spider)和process_response(self,request,response,spider) 中间件会先通过前一个方法再进去到第二个方法,通过下载中间件可以设置请求头,代理。设置代理时,设置一个request.meata["proxy"] = "协议+ip地址+端口"即request.meata["proxy"] = "https://255.255.255.255:999"。process_response的方法需要return一个request或者response对象。 在中间件中还可以设置对错误的一些处理方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









