







 本文围绕PHP网站缓存展开,介绍了从架构看缓存的目的与合理使用方式,涵盖文件类缓存、内存数据库(memcached、Redis)、浏览器缓存机制、服务器程序缓存(apache、PHP、mysql)等内容,还总结了缓存知识体系及需注意的时效性、可靠性、一致性等问题。
本文围绕PHP网站缓存展开,介绍了从架构看缓存的目的与合理使用方式,涵盖文件类缓存、内存数据库(memcached、Redis)、浏览器缓存机制、服务器程序缓存(apache、PHP、mysql)等内容,还总结了缓存知识体系及需注意的时效性、可靠性、一致性等问题。
文章目录
第一 知识结构
介绍在php网站中主要的缓存知识点,以一个商场的首页和几个核心页为例,实际应用这些技术。点评这些技术的优点和存在的问题
- 从架构看缓存
- 文件类缓存
- 内存数据库之memcached
- 内存数据库之redis
- 浏览器缓存机制
- 服务器程序的缓存
第二 从架构看缓存
2.1 布局缓存的目的
压力均分,减少对瓶颈环节的流量冲击;简化处理流程,提升整个流程的处理速度;持久化和固化数据
2.2 合理使用缓存
适合存放那些内容:缓存实时性变化要求不严格的内容(防止幻读);缓存经常访问但改动不频繁的内容;
2.3 哪些位置适合做缓存
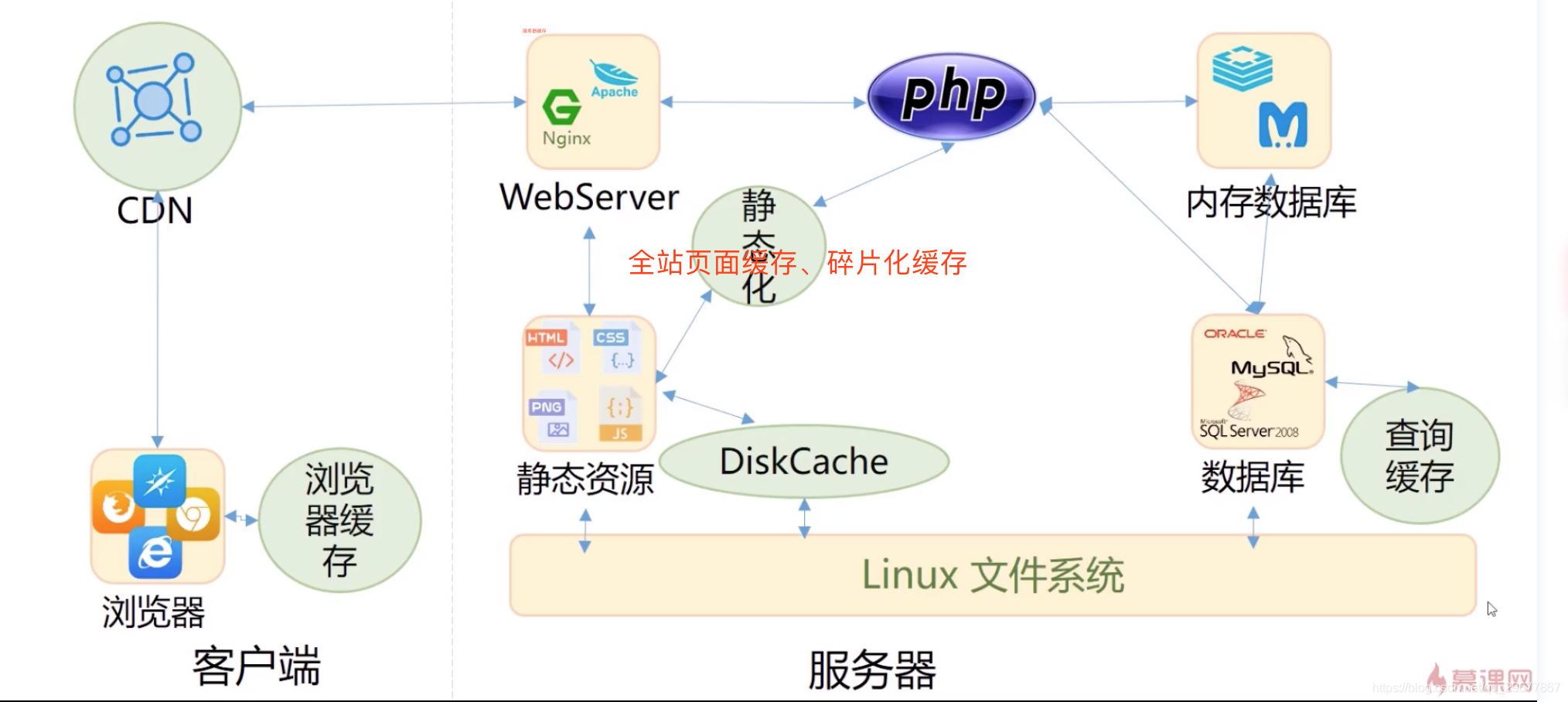
第三章 文件类缓存
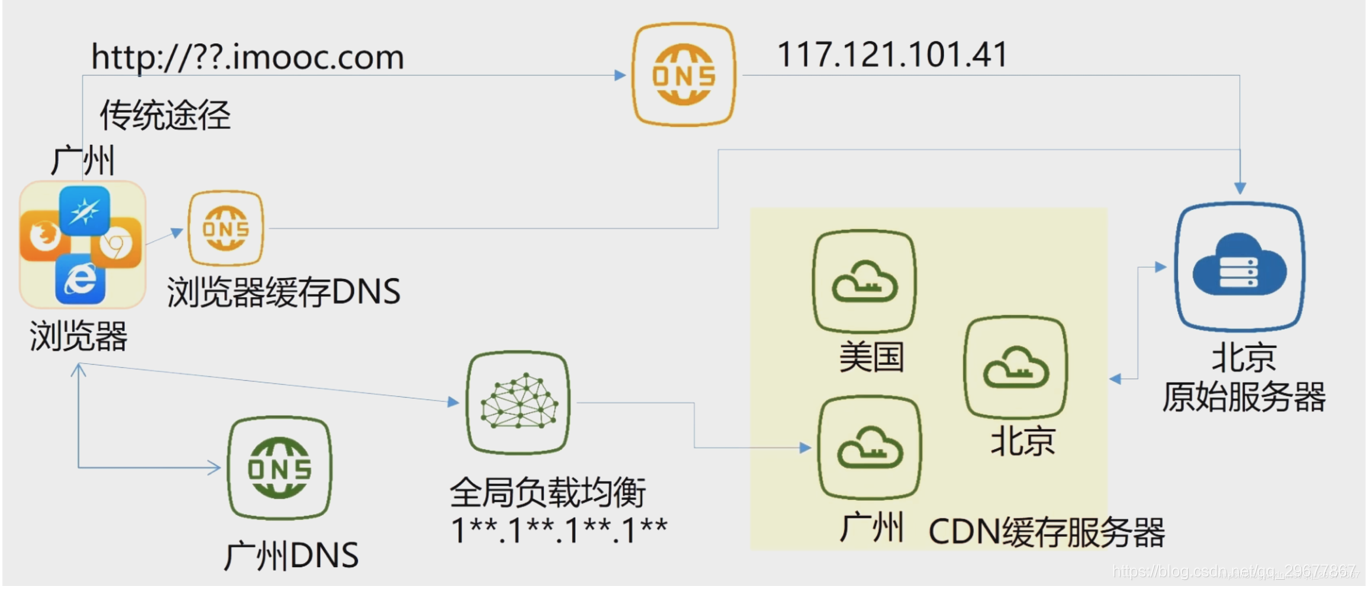
3.1 CDN缓存原理和介绍(涉及到cdn回源,缓存失效+主动推送更新文件)
3.1.1 特点:
- 各地部署多套静态存储服务,本质上是空间成本换时间
- 自动选择最近的节点内容,不存在再请求原始服务器
- 适合存储更新很少的静态内容,文件更新慢
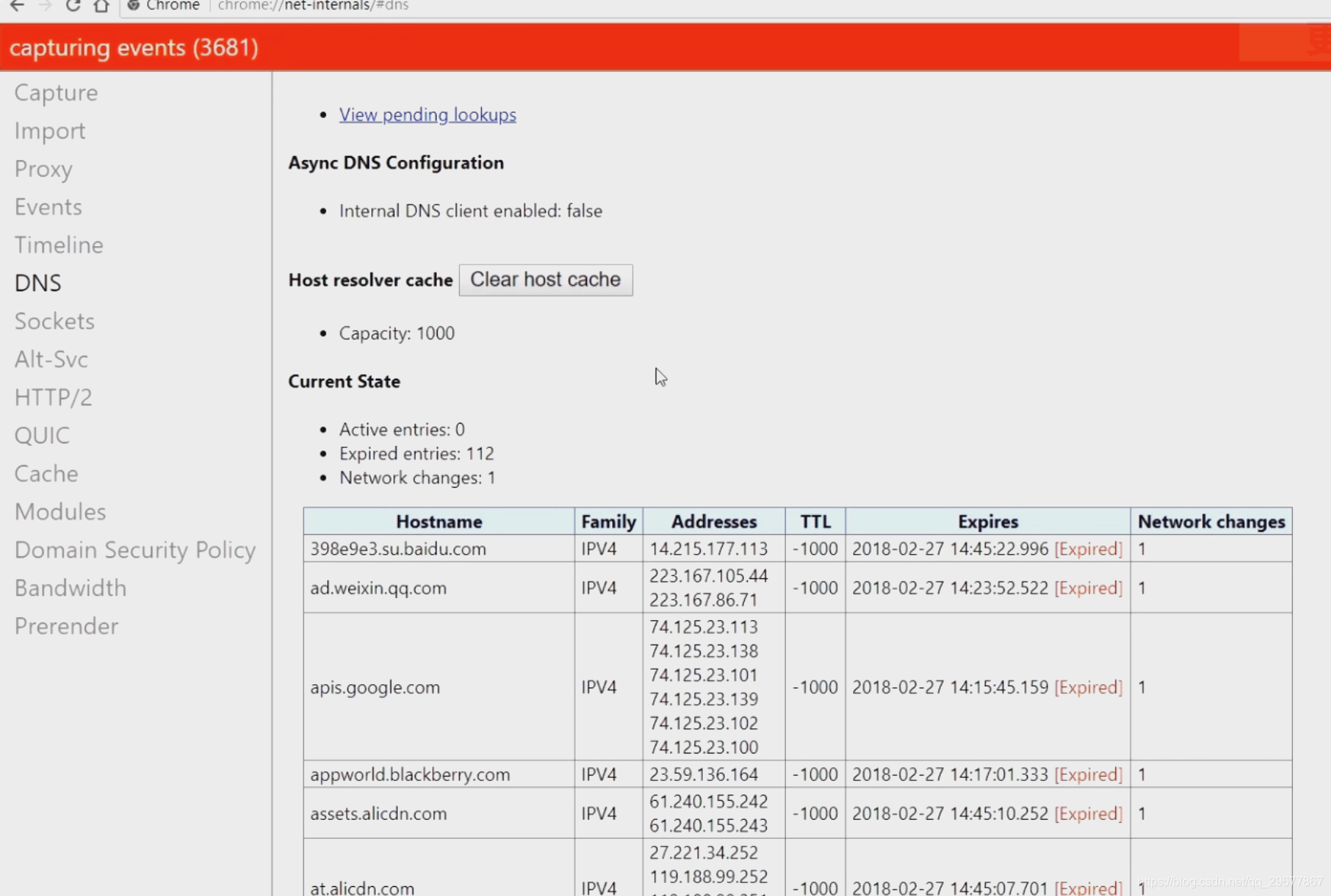
3.1.2 chrome浏览器的dns缓存设置
3.1.3 cdn缓存原理
3.2 数据文件缓存方案

将更新频率极低且读取机率高的数据缓存为文件,获取时不再查询数据库而是直接读和解析文件内容。
3.3 全页面的静态化(利用php函数来动态生成 .html的静态页面)
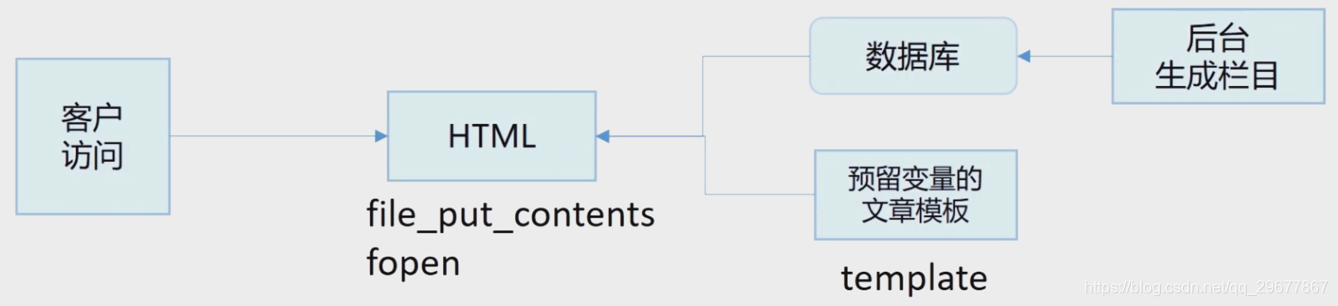
常见于CMS ,使用前后端分离的思路如Smarty把页面共用区域做成模板,并留下变量区域,后台修改内容时,把变量替换入模板,并生成HTML。用户访问时,直接显示HTML页面
特点:
- 有利于搜索引擎优化seo,加快收录速度
- 减轻服务器负担,减少数据库请求和运算量
- 加快页面打开速度,便于cdn加速
- 防止漏洞和入侵
- 非常适合文章类网站
3.4 从页面片段缓存到Facebook的BigPipe技术
解决首页加载慢,渲染多少,传输多少
3.4.1 特点:
- 将页面划分成一个个小块
- 利用ob_flush() 与 flush() 将缓冲区的内容提前输出给浏览器
- 浏览器在一个请求中不断的接收并渲染到页面,逐个小块显示出来(注:js部分,不需要立刻执行的部分,可以最后再eval进来 program data >> php buffer >> tcp buffer >> client browers)
3.4.2 做法:
修改nginx.conf
#新增
proxy_buffering off;
fastcgi_keep_conn on;
修改php.ini
;打开并修改output_buffering的值
output_buffering = off
重启nginx,php服务
sudo service nginx restart
sudo service php restart
3.4.3 相关的ob_函数 :
| 方法 | 作用 | 解释 |
|---|---|---|
| ob_start() | 打开输出缓冲区 | |
| flush() | 将当期为止TCP buffer中的内容发送到用户的浏览器 | 该函数不会对服务器或客户端浏览器的缓存模式产生影响。因此必须同时使用ob_flush()和flush()函数来刷新输出缓冲 |
| ob_flush() | 将PHP buffer中的内容送出到TCP buffer中 | 调用ob_flush()之后缓冲区内容将别丢弃 |
| ob_get_contents() | 返回内部缓冲区的内容 | 只是得到输出缓冲区的内容,但不清除它,没有激活则返回FALSE |
| ob_get_length() | 返回内部缓冲区的长度 | |
| ob_end_clean() | 删除内部缓冲区的内容,并且关闭内部缓冲区 | |
| Ob_end_flush() | 发送内部缓冲区的控制到浏览器,并且关不输出缓冲区 | |
| ob_implicit_flush() | 默认为关闭缓冲区 | 打开绝对输出后,每个脚本输出都直接发送到浏览器,不再需要调用flush(). |
第四章 内存数据库之memcached
4.1 内存数据库 in-memory database
- 内存数据库是将数据放在内存中直接操作的数据库(实际解决的是数据使用和存取的效率问题,而不是数据的持久化问题)
- 解决数据使用效率的问题,减少IO消耗
- 分为关系型内存数据库和非关系型内存数据库
- 常见:memcached、Redis、FastDB、eXtremeDB
4.2 memcached的特征
- 协议简单,使用简单的基于文本行的协议
- 基于libevent事件处理,灵活调整服务器的连接数
- 内存存储,存读速度快
- 不互相通信的分布式,每个服务器只对自己的数据进行管理(crc32计算键值,把资料分散在不同的机器上)
- 缺乏认证以及安全管理机制(把memcache放在防火墙之后,切不可将memcached端口放在外网当中)
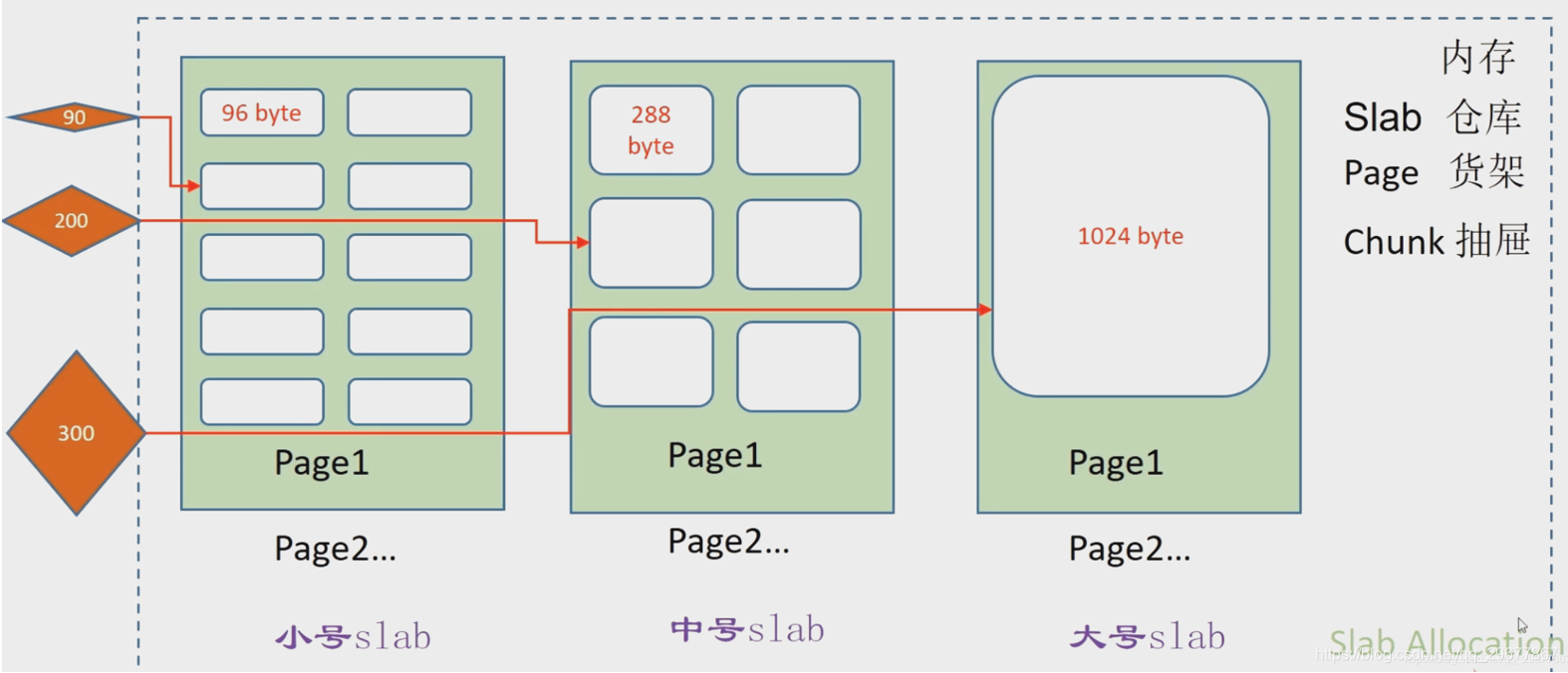
4.3 Memcached工作原理和内存管理
4.4 Memcached 和 PHP 组件 安装使用
telnet HOST PORT #验证是否成功
4.5 Memcached 基本使用
| 命令 | 说明 | cli命令示例 | PHP写法 |
|---|---|---|---|
| set | 存储 | set key flags exptime bytes [noreply] vlaue | set(key,value,time()+300); setMulti([key=>value],time()+300); |
| add | 不存在则存储 | add key flags exptime bytes [noreply] value | add(key,value,3600); |
| replace | 存在则替换 | replace key flags exptime bytes [noreply] value | replace(key, value, time()+300); |
| append | 已存在键后追加数据 | append key flags exptime bytes [noreply] value | append(key, value); |
| prepend | 已存在键前追加数据 | prepend key flags exptime bytes [noreply] value | prepend(key, value); |
| cas | 最后一次取值后未修改再写入 | cas key flags exptime bytes unique_cas_token [noreply] vlaue | case(cas_token, key, value); |
| get | 取值 | get key gets key1 key2 | get(key); getMulti([key1,key2]); |
| gets | 获取带有cas令牌的值 | get key gets key1 key2 | get(key, cas); getMulti([key1,key2], cas) |
| delete | 删除 | delete key [noreply] | delete(key, time); |
| incr | 数字自增 | incr key number | increment(key, number); |
| decr | 数字自减 | decr key number | decrement(key, number); |
| stats | 统计信息 | stats | getStatus(); |
4.6 使用memcached 实现分布式算法
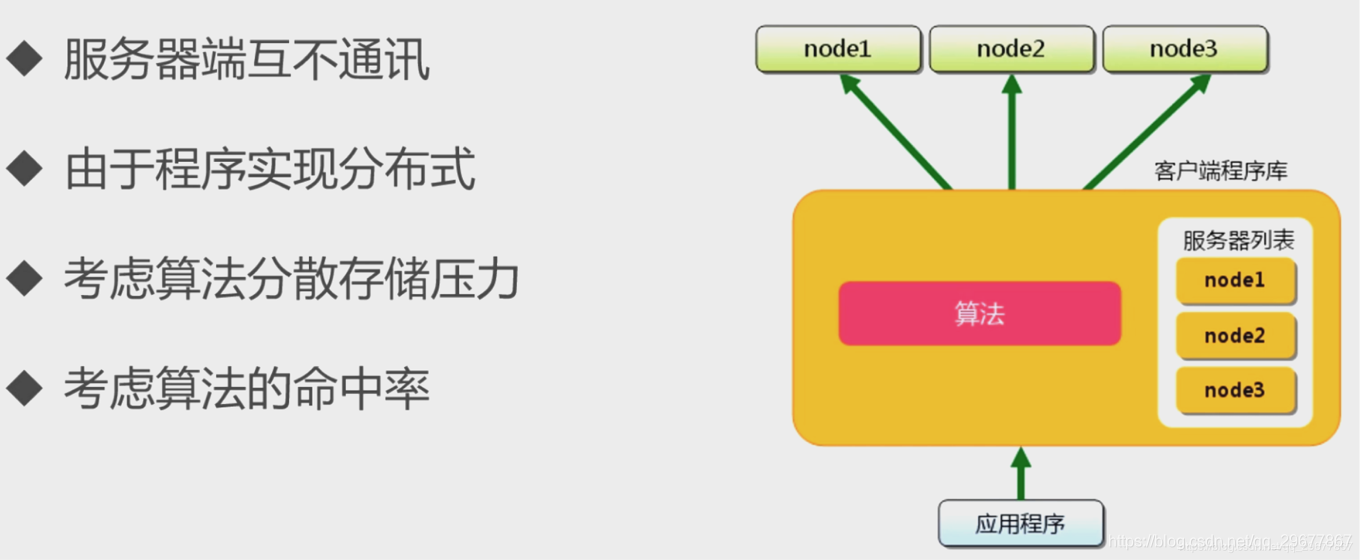
4.6.1 分布式算法之余数计算分散法
根据key来计算CRC ,然后结果对服务器数进行取模得到memcached服务器节点。服务器无法连接的时候,将尝试的连接次数加到key后面重新计算
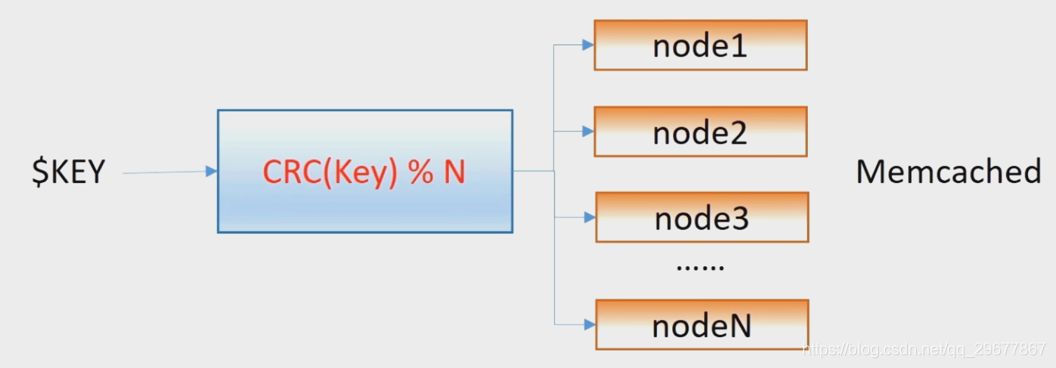
缺点:添加或移除服务器时,几乎所有缓存要重建,还考虑雪崩式崩溃问题

4.6.2 分布式算法之一致性哈希算法
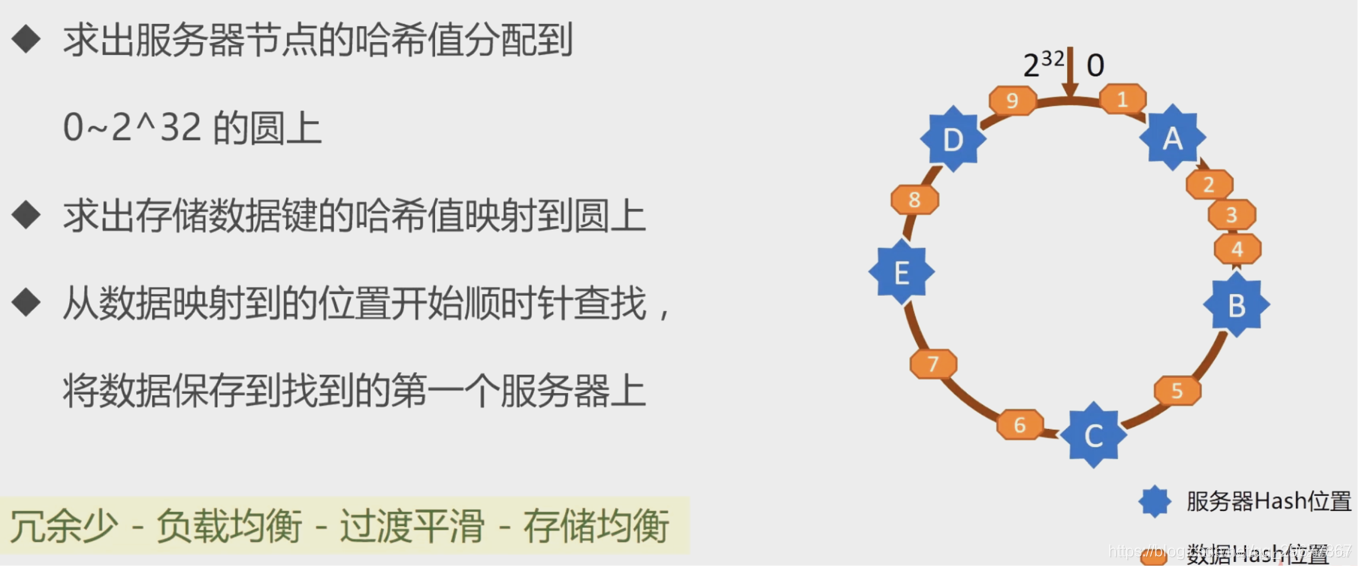
4.7 使用Memcached实现Session共享
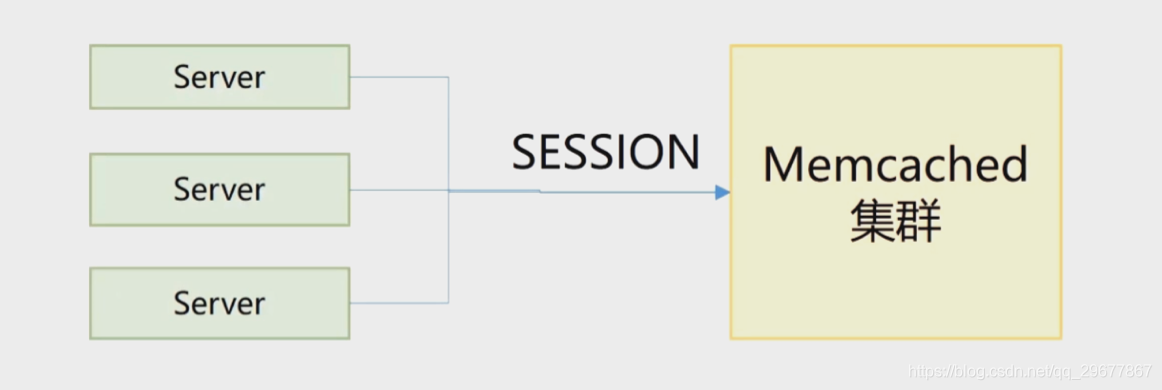
Session存放在共用的Memcached中,实现多服务器共享
缺点:集群错误会导致用户无法登陆、回收机制可能导致用户掉线
修改php.ini
[Session]
;session.save_handler = files
session.save_handler = "memcached"
;session.save_path = "/var/lib/php/sessions"
session.save_path = "tcp://192.168.1.1:11211"
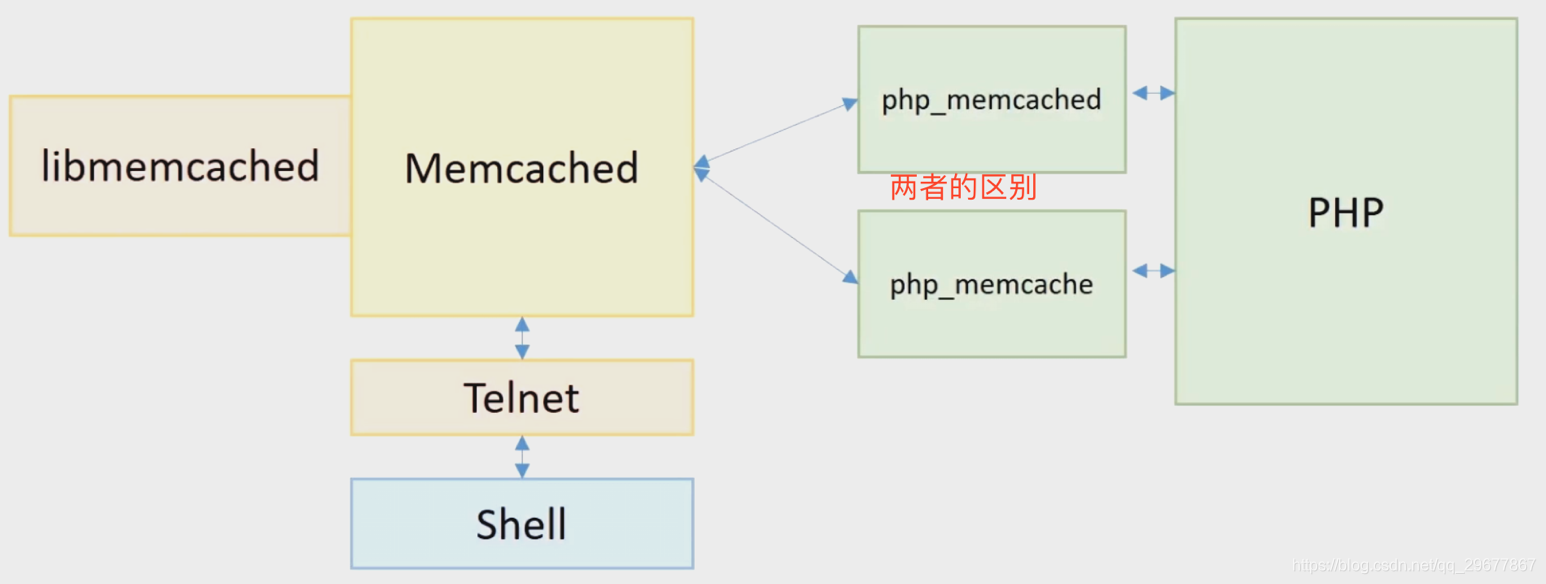
4.8 memcache与memcached的区别

第五章 内存数据库之Redis
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
5.1 Redis的特点
- 简单的key-value存储,性能极高。
- Redis拥有更多的数据结果和并支持更丰富的数据操作。
- Redis支持数据持久化和数据恢复。
- Redis的所有操作都是原子性的,支持事务(将操作存入队列,执行事务的过程中会拒绝掉其他的所有请求)。
- 服务器支持AUTH密码验证(可以允许放在外网中)
5.2 Redis和PHP组件的安装和配置
redis-cli -h host -p port -a password
5.3 Redis客户端命令
| 命令 | 说明 | cli命令示例 |
|---|---|---|
| del | 删除key | del key |
| exists | 检查给定key是否存在 | exists key |
| keys | 查找所有匹配模式 pattern的key | keys pattern |
| type | 返回key所存储的值的类型 | type key |
| expire | 设置key的过期时间 | expire key time_in_seconds |
| ttl | 返回key的剩余过期时间 | ttl key |
| save | RDB持久化 | save |
| info | redis服务器的各种信息和统计数值 | info [section] |
| shutdown | 保存并停止所有客户端 | shutdown [nosave] [save] |
5.4 Redis 字段类型
字段类型包括:String 字符串、Hash 散列/哈希、List 列表、Set 无序集合、Zset 有序集合
5.4.1 String类型
- 最常见的数据类型
- 可以为任何类型的字符串,比如二进制、json对象
- 最大容量512M
| 命令 | 说明 | cli示例 | php示例 |
|---|---|---|---|
| set | 赋值 | set key value | set(key, value); |
| setex | 赋值并添加过期时间 | setex key expire value | setex(key, expire, value); |
| get | 取值 | get key | get(key); |
| incr | 递增数字 | incr key | incr(key); |
| incrby | 递增指定的数字 | incrby key number | incrby(key, number); |
| decr | 递减数字 | decr key | decr(key); |
| decrby | 递减指定的数字 | decrby key number | decrby(key, number); |
| incrbyfloat | 增加指定浮点数 | incrbyfloat key number | incrByFloat(key,float) |
| append | 向尾部追加值 | append key value | append(key, value); |
| strlen | 获取字符串长度 | strlen key | strlen(key); |
| mset | 同时设置多key值 | mset key value [key1 v1 …] | mSet([k=>v, k1=>v1]); |
| mget | 同时获取多key值 | mget key [k1 …] | mGet([k,k1,k2]); |
5.4.2 Hash类型
- 与PHP的Array相似
- 可以保存多个key=>value对,每个k-v都是字符串类型
- 最多2^31-1个字段
| 命令 | 说明 | cli命令示例 | PHP写法 |
|---|---|---|---|
| hset | 赋值 | hset key field value | hset(key, fileld, value); |
| hmset | 赋值多个字段 | hmset key field value [f1 v1 …] | hMset(key,[f1=>v1, f2=>v2]); |
| hget | 取值 | hget key field | hGet(key, field); |
| hmget | 取多个字段的值 | hmget key field1 f2… | hmGet(key, [f1, f2]); |
| hgetall | 取所有字段的值 | hgetall key | hGetAll(key); |
| hlen | 获取字段的数量 | hlen key | hLen(key); |
| hexists | 判断字段是否存在 | hexists key field | hExists(key, field); |
| hsetnx | 当字段不存在时赋值 | hsetnx key field value | hSetNx(key, field, value) |
| hincrby | 增加数字 | hincrby key field num | hIncrBy(key, field, num); |
| hdel | 删除字段 | hdel key field | hDel(key, field); |
| hkeys | 获取所有字段名 | hkeys key | hKeys(key); |
| hvals | 获取所有字段值 | kvals key | hVals(key) |
5.4.3 List类型(双向链表)
- 实现方式为双向链表
- 用于存储一个有序的字符串列表
- 从队列的两端添加和弹出元素
- 特别适合做消息队列
| 命令 | 说明 | cli命令示例 | PHP写法 |
|---|---|---|---|
| lpush | 向列表左端添加元素 | lpush k v | lPush(k, v) |
| rpush | 向列表右端添加元素 | rpush k v | rPush(k, v) |
| lpop | 从列表左端弹出元素 | lpop k | lPop(k); |
| rpop | 从列表右端弹出元素 | rpop k | rPop(k); |
| llen | 获取列表中元素个数 | llen key | lSize(k); |
| lrange | 获取列表中某段元素 | lrange key start end | lRange(k, s, e); |
| lrem | 删除列表中指定的值 | lrem k count v | lRem(k, v, count); |
| lindex | 获取指定索引的元素值 | lindex key index | lGet(key,index); |
| lset | 设置指定索引的元素值 | lset key index value | lSet(key, index, value); |
| ltrim | 只保留列表指定片段 | ltrim key start end | lTrim(key, start, end); |
| linsert | 向列表中插入元素 | linsert key before/after index value | lInsert(key, Redis::BEFORE, index, value) |
**注:队列里的数据处理失败之后,应当继续把数据给rpush到队列中,防止消息丢失 **
5.4.4 set类型特点及命令(可用作去重,交/并/差集)
- 集合中每个元素都是不同的
- 元素最多为2^32-1
- 元素没有顺序
| 命令 | 说明 | cli命令示例 | PHP写法 |
|---|---|---|---|
| sadd | 添加元素 | sadd k v[ v2 v3 …] | sAdd(key,v); |
| srem | 删除元素 | Srem k v[v2 v3 …] | sRem(k, v); |
| smembers | 获得集合中所有元素 | smembers k | sMembers(k) |
| sismember | 判断元素是否存在集合中 | smember k v | sisMember(k,v); |
| sdiff | 对集合做差集运算 | sdiff k k1[k2] | sDiff(k,k1,k2); |
| sinter | 对集合做交集运算 | sinter k k1[k2] | sInter(k, k1, k2) |
| sunion | 对集合做并集运算 | sunion k k1 [k2] | sUnion(k, k1, k2) |
| scard | 获得集合中元素的个数 | scard k | sCard(k); |
| sdiffstore | 对结果做差集并存储结果 | sdiffstore k k1 [k2] | sDiffStore(k, k1, k2); |
| sinterstore | 对结果做交集并存储结果 | sinterstore k k1 [k2] | sInterStore(k, k1, k2); |
| sunionstore | 对结果做并集并存储结果 | sunionstore k k1 [k2] | sUnionStore(k, k1, k2); |
| srandmember | 随机获取集合中的元素 | srandmember k [count] | sRandMember(k, 2); |
| spop | 随机弹出一个元素 | spop key | sPop(k, 1); |
5.4.5 zset类型(有序集合用的是反列表和跳跃表,所以比list更费内存)
- 集合是有序的
- 支持插入,删除,判断元素是否存在
- 可以获取分数最高/最低的前N个元素
| 命令 | 说明 | cli命令示例 | PHP写法 |
|---|---|---|---|
| zadd | 添加元素 | zadd key k v[ k1 v1…] | zAdd(k, 1 v) |
| zscore | 获取元素是分数 | zscore key value | zScore(k, v); |
| zrange | 获取正序排名在某范围的元素 | zrange key start end | zRange(k, 0, -1) |
| zrevrange | 获取倒序排名在某范围的元素 | zrevrange key start end | zrevrange(k,0, -1) |
| zincrby | 增加某个元素的分数 | zincrby key increment v | zIncrBy(k, increment, v); |
| zcard | 获取集合中元素的格式 | zcard key | zSize(k); |
| zcount | 获取指定范围内的元素个数 | zcount key min max | zCount(k, start, end); |
| zrem | 删除一个或多个元素 | zrem k v[v2] | zDelete(k,v); |
| zremrangebyrank | 按照排名范围删除元素 | zremrangebyrank key start end | zRemrangebyrank(k, 0, 1); |
| zremrangebyscore | 按照分数范围删除元素 | zremrangebyscore key min max | zRemrangebyscore(k, 0, 3) |
| zrank | 获取正序排序的元素排名 | zrank key value | rRank(k, v); |
| zrevrank | 获取逆序排序的元素排名 | zrevrank key value | zRevRank(k, v); |
5.5 Redis的持久化
5.5.1 方式
- RDB 指定的时间间隔内保存数据快照
- AOF 先把命令追加到操作日志的尾部,保存所有历史操作
5.5.2 RDB持久化-指定时间间隔内保存数据快照(适合灾难恢复)
#redis.cnf
#持久化策略
save 900 1 #每15分钟变更一次记录
save 300 10 #每5分钟变更10次
save 60 10000 #每1分钟变更10000次记录
#保存路径
dir /var/lib/redis
dbfilename dump.rdb
优点
- 适合用户备份
- fork 出子进程进行备份,主进程没有任何IO操作
- 恢复大数据集时的速度快
缺点:
- 特定条件下进行一次持久化,易丢失数据
- 庞大数据时,保存时会出现性能问题
5.5.3 AOF 持久化-先把命令追加到操作日志的尾部,保存历史操作
#redis.cnf
dir /var/lib/redis
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec(异步)/always(同步)/no(不同步)
优点:
- 数据非常完整,故障恢复丢失数据少
- 可对历史操作进行处理
缺点:
- 文件的体积大
- 速度低于RDB且故障恢复速度慢
5.6 合理地使用Redis
- 防止内存占满
- 设置超时时间
- 不存放过大文件
- 不存放不常用数据
- 提高使用效率
- 合理使用不同的数据结构类型
- 慎用正则处理或批量操作Hash、Set等
5.7 Redis Cluster集群
5.7.1 集群部署
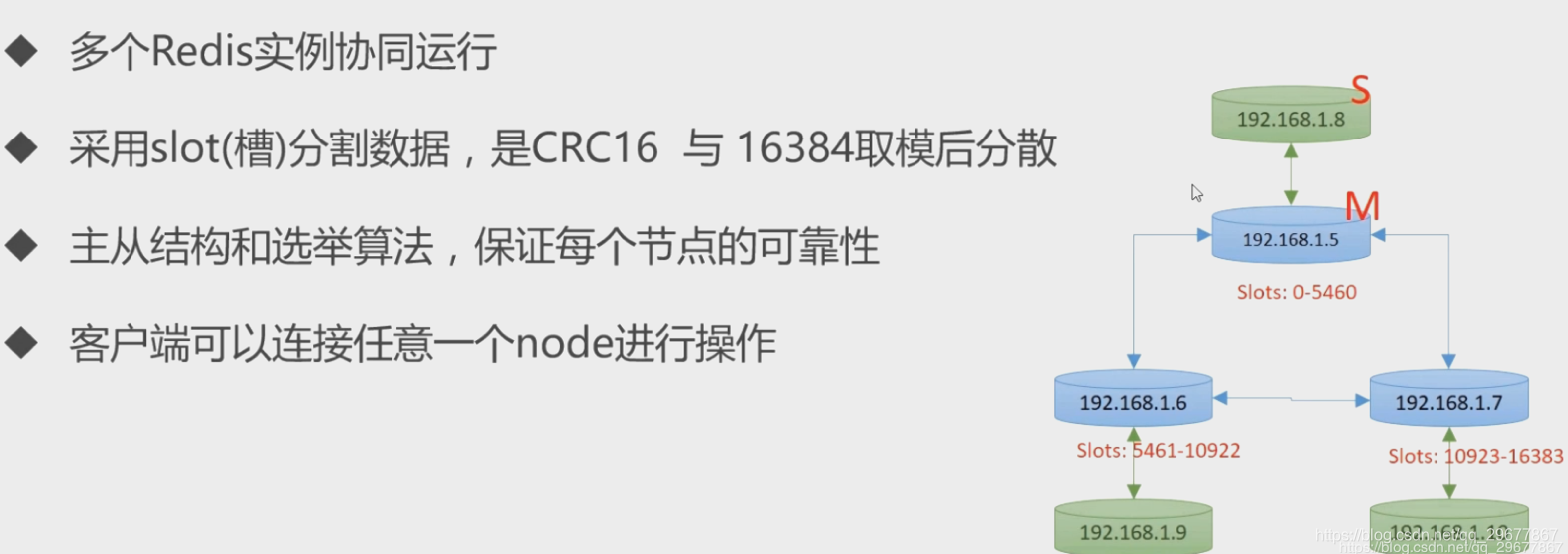
5.7.2 Redis Cluster结构

5.7.3 注意事项

第六章 浏览器缓存机制
1. 浏览器处理网页的方式
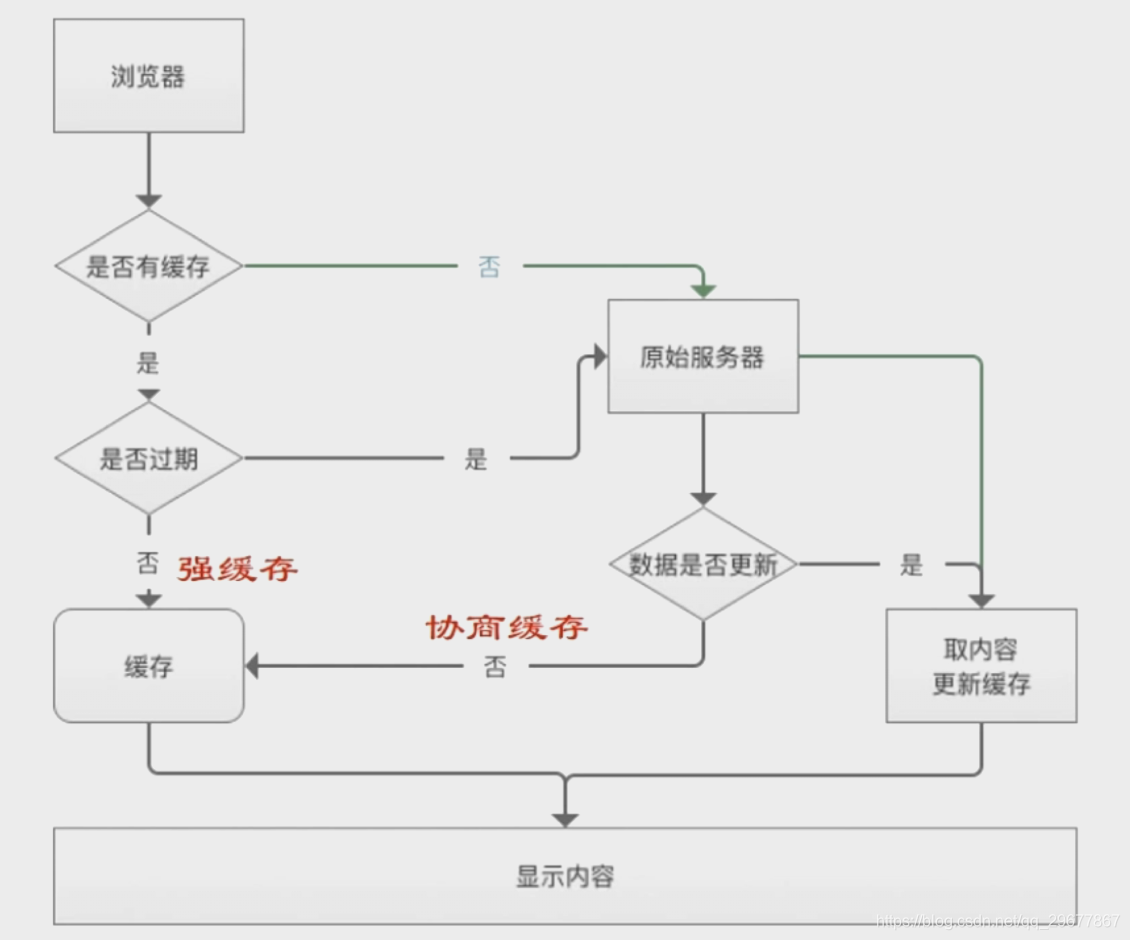
2. 浏览器缓存方式
Header 字段输出方式
#常见的缓存方式包括 html/php/apache/nginx
#html输出方式
<meta http-equiv="Cache-Control" content="max-age=7200"
#php输出方式
header("Cache-Control: max-age=7200");
6.2.1 强缓存阶段的Header字段
缓存配置的优先级(Cache-control的参数通常会组合使用)

6.2.2 协商缓存阶段的Header字段

3. 合理使用浏览器缓存
- 页面链接的请求无需做长时间缓存
- 敏感数据像订单等不宜做缓存
- 静态资源部分,通常会设定一个较长的缓存时间
- 冷热数据分离,减少请求量
- 不要随意修改文件,建议使用?version=** 调用多版本
- 不建议使用ETag,尤其是分布式
第七章 服务器程序的缓存
7.1 apache缓存
7.1.1 apache的缓存机制
mod_expires.so #过期模块
mod_cache 缓存模块
7.1.2 apache过期模块
通过配置文件控制HTTP的"Expires:" 和"Cache-Control:" 头内容
#启用expires_ module模块
LoadModule expires_module modules/mod_expires.so
#启用有效期控制
ExpiresActive On
#GIF有效期为1个月
ExpiresByType image/gif A2592000
#HTML文档的有效期是最后修改时刻后的一星期
ExpiresByType text/html M604800
#以下的含义类似
ExpiresByType text/css "now plus 2 months "
ExpiresByType image/jpeg "access plus 2 months'
其中
ExpiresByType text/html “now plus 2 months”
#“ExpiresByType” =>有mime决定过期配置
#text/html =>html文件
#now => Access Now a(过期时间从访问时开始计算) | Modification M A(被访问文件的最后修改时间开始计算)
#months => years|months|weeks|days|hours|minutes|seconds
7.1.3 Apache缓存模块
- mod cache :基于URI键的内容动态缓冲模块,缓存响应头和正文,以便在下一个请求时快速响应它
- mod_ disk_ cache (Apache2.2) / mod_ cache_ disk (Apache2.4) 基于磁盘的缓冲模块
- mod mem cache.so (Apache2.2)基于内存的缓冲模块,2 4版本已经移除
- mod_ file_ cache 提供文件描述符缓存支持,加快与缓慢的文件系统服务器的文件访问,只能应用于静态文件
7.2 PHP缓存
7.2.1 PHP的APC和Opcache
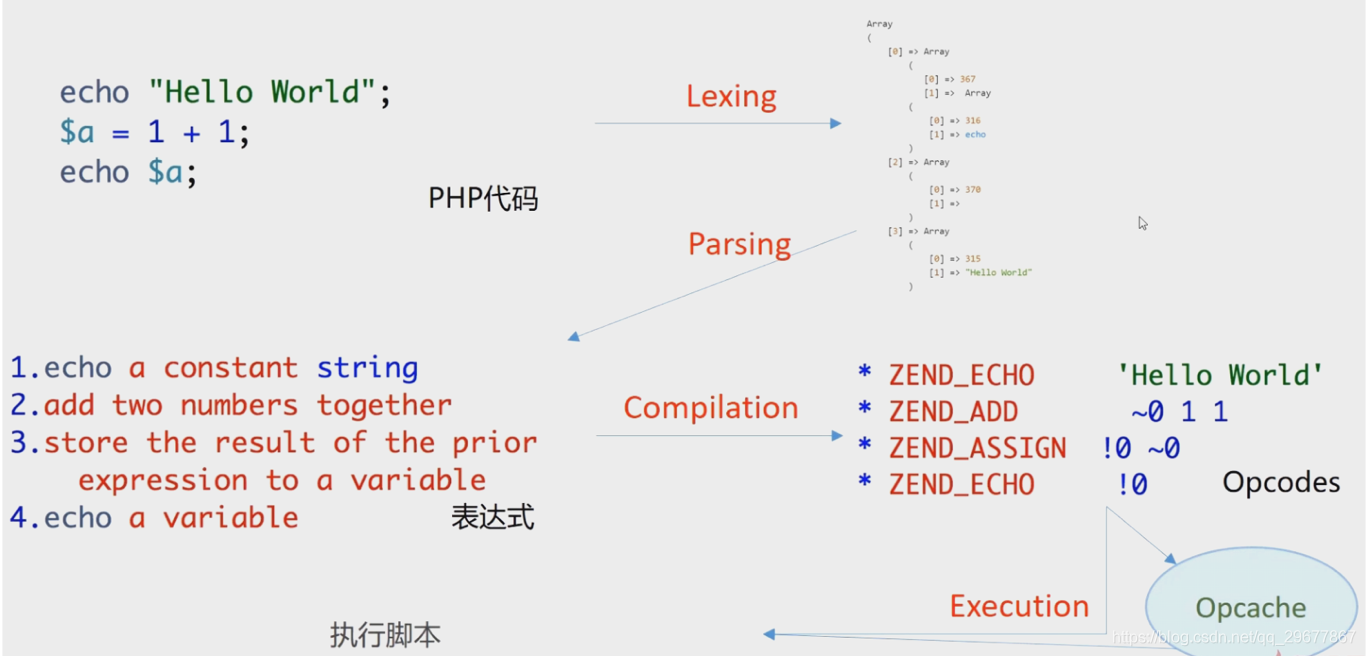
- Opcache是一种通过将解析的PHP脚本预编译的字节码存放在共享内存中来避免每次加载和解析PHP脚本的开销。
- 解析器可以直接从共享内存读取已经缓存的字节码,从而大大提高PHP的执行效率。
- APC是缓存、优化PHP中间代码的架构,可以缓存 Opcodes。
- PHP5.5以后, Zend Opcache整合到PHP中,并可代替APC使用。此功能默认关闭。
7.2.2 php的执行过程
7.3 mysql缓存
7.3.1 mysql的缓存相关参数和优化点
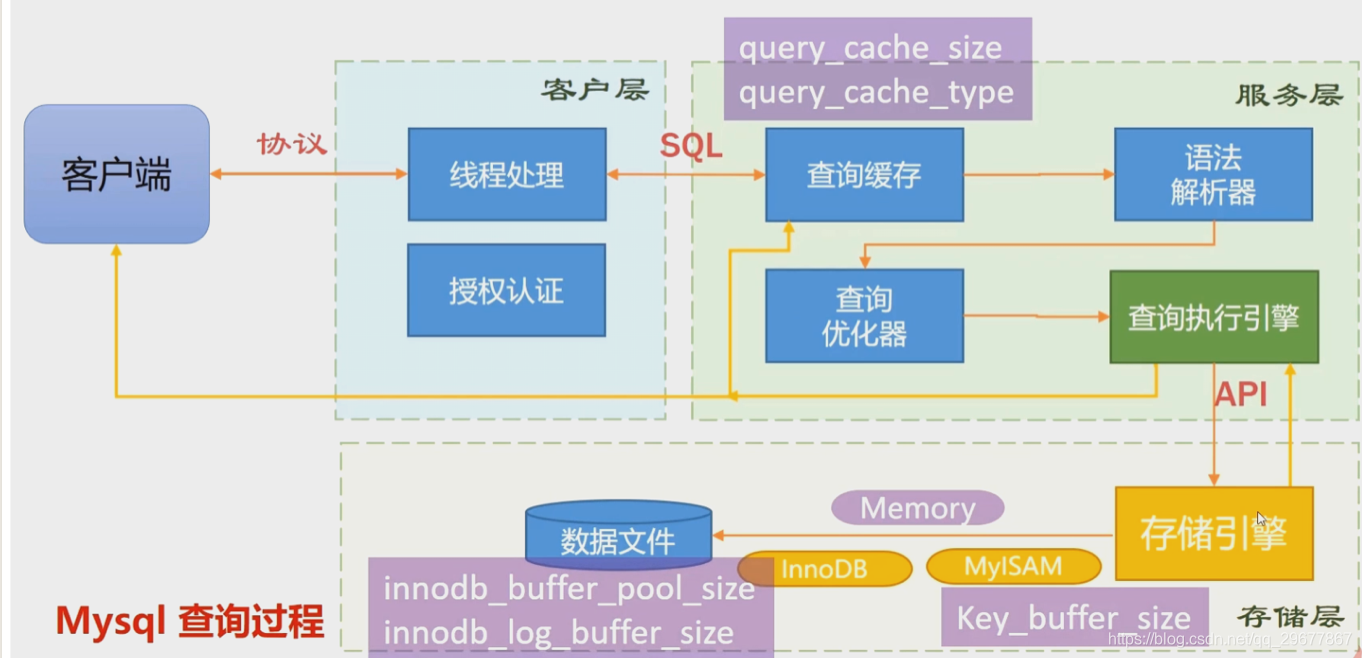
#my.cnf
query_cache_size = 16M
query_cache_limit = 1M
query_cache_type = 1 #开启缓存
show variables like "%query_cache%" #查询缓存是否开启
show status like "%Qcache%" #显示查询缓存空间的状态
7.3.2 mysql的memory存储
-
原理:创建表结构使用ENGINE=MEMORY生成内存表,表结构存在磁盘上的.frm文件中,服务器启动后,用此结构在内存中创建空白表,并默认使用hash索引。
-
优点:
- 速度比其他存储引擎更快,适合做热点表的前置缓存
- SQL操作与存储引擎一致
-
使用要点:
- VARCHAR这样的可变长度类型将转换为固定长度
- MYSQL4.1.0之前不支持auto_increment列
- 不能包含BLOB或TEXT列
- 重启数据丢失,如果有备份,会导致数据与备份不一致
- 内存表数据大于max_heap_table_size设定值,超出数据会存储在磁盘上
- 高负载时扩展性和混合写操作的并发处理性能不佳
第八章 总结
8.1 缓存知识体系
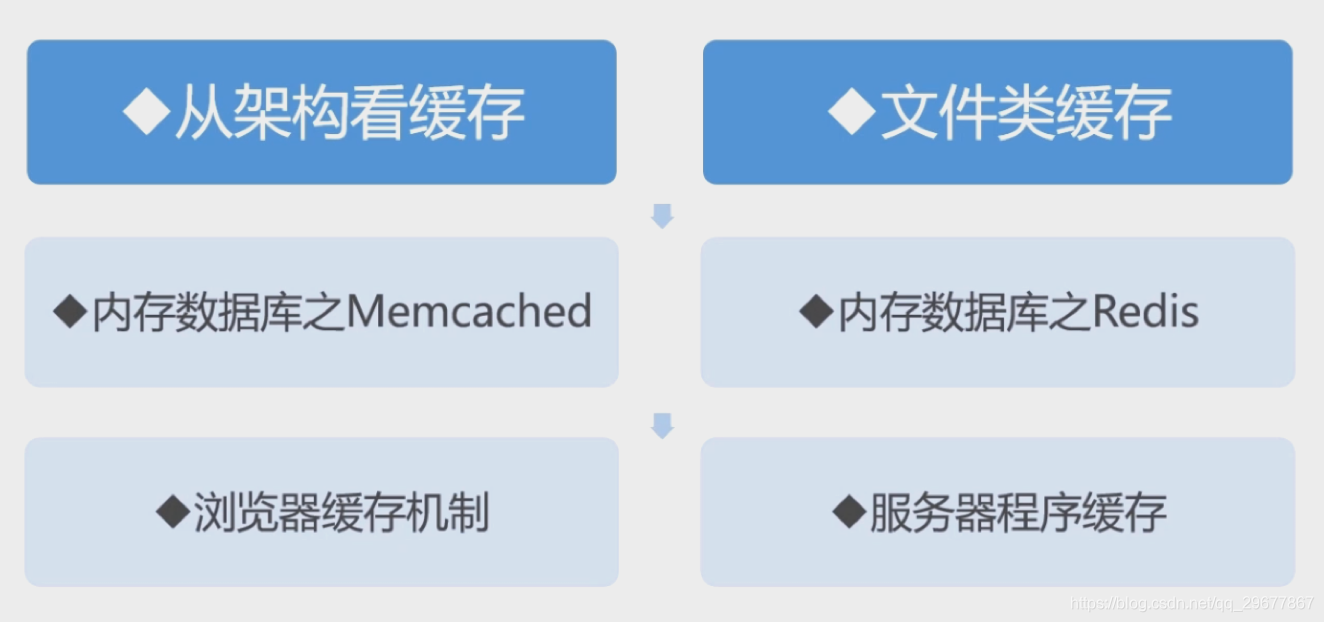
8.2 缓存需要注意事项
8.2.1 时效性和过期机制:
- FIFO(first in first out)先进先出策略
- LFU(less frequently used)最少使用策略
- LRU(least recently used)最少使用策略
- 过期时间
8.2.2 可靠性:
- 介质类型
- 允许的最大空间
- 命中率(多指内存数据库)
- 安全性能
8.2.3 一致性和压力处理:
- 一致性
- 缓存失效
- 缓存穿透
- 雪崩

















 2625
2625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









