







简介
项目技术选型时,我当时推荐ES存储设备数据,上面并没有采纳我的意见,最终选用InfluxDB时序数据库。网上找了一大堆资料,关于InfluxDB相关的博客没有很多,大多数都是对InfluDB1的一些介绍,InfluxDB2相关的资料少之又少。所以把自己这些天粗略了解的点以及遇到的一些坑给大家介绍,如有不对之处,欢迎批评指教,互相学习探讨。(官方文档链接)
名词介绍
InfluxDB一行记录(point)由时间戳(time)、标签(tag)、单个字段(field)组成。标签类似MySQL的索引字段,需要查询或者统计的字段把该字段指定为标签。为什么叫point,因为它一条数据只返回一个普通字段的值。当你需要一条完整的数据时,需要自己手动写个通用工具类把它组装成一条数据,个人感觉使用起来有点麻烦。O__O"…
| MySQL | InfluxDB | |
|---|---|---|
| 数据库 | database | bucket |
| 表名 | table | measurement |
| 记录 | rows | point |
| 字段 | columns | time+tag+field |
Flux
InfluxDB2查询语句使用Flux语言,官方文档有介绍。
遇到的坑:
-
InfluxDBClient写API导致的线程数过多内存溢出问题。
建议项目启动的时候初始化WriteApi,后期直接用这个API调用写数据,而不是每次使用influxDBClient.getWriteApi()获取WriteApi。 -
日期统计:
一开始没在官方文档看到说明,按月统计不知道是啥。然后自己把26个英文单词都试了一遍,还是不行,最后抱着一丝希望试了一下mo,然后成功了,哈哈。不过后面也在官方文档看到说月的单位为mo。按周统计统计的是是上周四到这周三的数据,我们习惯统计的是周一到周日的数据,待解决。类型 单位 年 y 月 mo 周 w 日 d 时 h 分 m -
统计
若不增加group函数,所有统计默认会按tag分组。例如我需要统计每日的设备在线量,tag的值有几个就会返回几条数据,所以记得Flux表达式中一定记得加group函数。 -
自带函数:
非必要情况下能不使用Influxdb提供的时间转换函数或者其他函数尽量就不要使用。一旦查询或者返回数据过多,容易发生读取连接超时,可手动写一个时间工具类对时间做偏移处理。 -
时区问题:
我们这里时间是东八区,所以我们查询数据的时候和返回数据的时候需要对时间偏移8小时。但是在统计按 天/周/月等统计时,必须使用timeShift函数,小时/分钟可调用时间工具类方法做偏移即可。个人推荐一开始就把数据时间处理好存入数据库,省得后期查询转换来转换去的不方便效率也降低。举个例子:查询时间范围:2020-01-19T00:00:00+8:00~2020-01-21T00:00:00+8:00
实际查询时间范围:2020-01-18T16:00:00Z~2020-01-20T16:00:00Z我们期望得到的是19号和20号的统计值,由于时间偏移导致我们得到了三条数据。
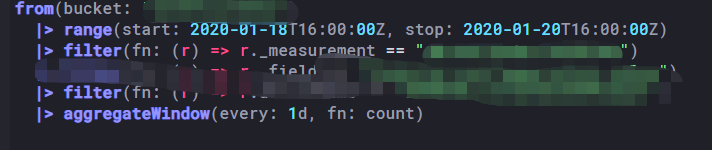
_value _time 时间统计范围 479 2020-01-19T00:00:00Z 2020-01-18T16:00:00Z~2020-01-19T00:00:00Z 1437 2020-01-20T00:00:00Z 2020-01-19T00:00:00Z~2020-01-20T00:00:00Z 396 2020-01-20T16:00:00Z 2020-01-20T00:00:00Z~2020-01-20T16:00:00Z 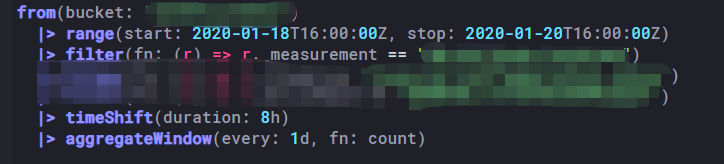
_value _time 1437 2020-01-20T00:00:00Z 875 2020-01-21T00:00:00Z
/**
* @Description:
* @author: wanzh
* @date: 2019年12月19日
*/
public class InfluxDBFluxExpression {
/**
* 通用表达式
* @param buffer
* @param bucketName 名称
* @param tableName 表名
* @param start 开始时间
* @param stop 结束时间
*
*/
protected void appendCommonFlux(StringBuffer buffer, String bucketName, String tableName,
String start, String stop) {
appendBucketFlux(buffer, bucketName);
appendTimeRangeFlux(buffer, start, stop);
appendTableFlux(buffer, tableName);
// if(timestampFlag) {
// appendTimestampFlux(buffer);
// }
// if(dropDefaultFlag) {
// appendDropFlux(buffer);
// }
}
/**
* 数据源(桶)表达式
* @param buffer
* @param bucketName 名称
*/
protected void appendBucketFlux(StringBuffer buffer, String bucketName) {
buffer.append("from(bucket: \""+bucketName+"\") ");
}
/**
* 表名表达式
* @param buffer
* @param tableName 名称
*/
protected void appendTableFlux(StringBuffer buffer, String tableName) {
buffer.append("|> filter(fn: (r) => r._measurement == \""+tableName+"\") ");
}
/**
* 时间范围表达式
* @param buffer
* @param start 开始时间
* @param stop 结束时间
*/
protected void appendTimeRangeFlux(StringBuffer buffer, String start, String stop) {
if(StringUtils.isBlank(start)) {
start = "1970-01-01T00:00:00.000Z";
}
if(StringUtils.isBlank(stop)) {
buffer.append("|> range(start:" + start + ") ");
}else {
buffer.append("|> range(start:" + start + ", stop:"+ stop +") ");
}
}
/**
* 删除字段表达式
* @param buffer
* @param args 需要删除的字段【 参数为空的话删除host字段】
*/
protected void appendDropFlux(StringBuffer buffer, String... args) {
if(args.length == 0) {
buffer.append("|> drop(columns: [\"host\"]) ");
return ;
}
buffer.append("|> drop(columns: [");
for(int i = 0; i < args.length; i++) {
if(i != 0) {
buffer.append(",");
}
buffer.append("\""+args[i]+"\"");
}
buffer.append("]) ");
}
/**
* 复制属性列表达式
* @param buffer
* @param oldField 原来的字段名称
* @param newField 新的字段名称
*/
protected void appendDuplicateFlux(StringBuffer buffer, String oldField, String newField) {
buffer.append("|> duplicate(column: \""+oldField+"\", as: \""+newField+"\") ");
}
/**
* 重命名属性列表达式
* @param buffer
* @param oldField 原来的字段名称
* @param newField 新的字段名称
*/
protected void appendRenameFlux(StringBuffer buffer, String oldField, String newField) {
buffer.append(" |> rename(columns: {"+oldField+": \""+newField+"\"}) ");
}
/**
* 最新一条数据表达式
* @param buffer
*/
protected void appendLastFlux(StringBuffer buffer) {
buffer.append("|> last() ");
}
/**
* 分页查询
* @param buffer
* @param n
* @param offset
*/
protected void appendLimitFlux(StringBuffer buffer, int n, int offset) {
buffer.append("|> limit(n:"+n+", offset: "+offset+") ");
}
/**
* 分组表达式
* @param buffer
*/
protected void appendGroupFlux(StringBuffer buffer, String ...columns) {
if(columns.length == 0) {
buffer.append("|> group() ");
}else {
buffer.append("|> group(columns:[ ");
for(int i = 0; i < columns.length; i++) {
if(i != 0) {
buffer.append(",");
}
buffer.append("\""+columns[i]+"\"");
}
buffer.append("]) ");
}
}
/**
* 去重表达式
* @param buffer
*/
protected void appendDistinctFlux(StringBuffer buffer, String ...columns) {
if(columns.length == 0) {
buffer.append("|> distinct() ");
}else {
buffer.append("|> distinct(column:\""+columns[0]+"\") ");
}
}
/**
* 总数表达式
* @param buffer
*/
protected void appendCountFlux(StringBuffer buffer) {
buffer.append("|> count() ");
}
/**
* 前几条数据
* @param buffer
* @param n
*/
protected void appendTopFlux(StringBuffer buffer, int n) {
buffer.append("|> top(n:"+n+") ");
}
protected void appendBottomFlux(StringBuffer buffer, int n) {
buffer.append("|> bottom(n:"+n+") ");
}
/**
* 排序
* @param buffer
* @param descFlag true 降序 ;false 升序
* @param columns
*/
protected void appendSortFlux(StringBuffer buffer, boolean descFlag, String ... columns) {
if(columns.length == 0) {
buffer.append("|> sort(columns: [\"_value\"], desc: "+descFlag+")");
}else {
buffer.append("|> sort(columns:[ ");
for(int i = 0; i < columns.length; i++) {
if(i != 0) {
buffer.append(",");
}
buffer.append("\""+columns[i]+"\"");
}
buffer.append("], desc: "+descFlag+") ");
}
}
// /**
// * 转换时间戳 表达式
// * @param buffer
// */
// protected void appendTimestampFlux(StringBuffer buffer) {
// buffer.append("|> map(fn:(r) => ({r with _time:(int(v:uint(v:r._time))/1000000 )})) ");
// }
//
// /**
// * 转换时间格式表达式
// * @param buffer
// */
// protected void appendTimeformatFlux(StringBuffer buffer) {
// buffer.append("|> map(fn:(r) => ({r with _time:strings.substring(v: strings.replaceAll(v: string(v: r._time), t: \"T\", u: \" \"), start: 0, end: 19)})) ");
// }
//
/**
* 时移八小时
* @param buffer
*/
protected void appendTimeShiftFlux(StringBuffer buffer) {
buffer.append("|> timeShift(duration: 8h) ");
}
/**
* 字段名 表达式
* @param buffer
*/
protected void appendFiledFlux(StringBuffer buffer, String... args) {
boolean flag = true;
for(String arg : args) {
if(flag) {
buffer.append("|> filter(fn: (r) =>");
flag = false;
}else {
buffer.append(InfluxDBConst.JOIN_OR);
}
buffer.append(" r."+InfluxDBConst.FIELD_VAL+" "+InfluxDBConst.JOIN_EQUAL+" \""+arg+"\" ");
}
if(!flag) {
buffer.append(") ");
}
}
/**
* 过滤单个字符表达式
* @param buffer
* @param list
* @param operator 【== != 】
* @param join 【and or】
* @param fieldName
*/
protected void appendFilterFlux(StringBuffer buffer, List<String> list, String operator, String join, String fieldName) {
if(list == null || list.size() == 0) {
return ;
}
for(int i = 0, size = list.size(); i< size; i++) {
if(i == 0) {
buffer.append("|> filter(fn: (r) =>");
}else {
buffer.append(join);
}
buffer.append(" r."+fieldName+" "+operator+" \""+list.get(i)+"\" ");
}
buffer.append(") ");
}
/**
* 过滤表达式
* @param buffer
* @param map
* @param operator 【== != 】
* @param join 【and or】
*/
protected void appendFilterFlux(StringBuffer buffer, Map<String,Object> map, String operator, String join) {
Set<Entry<String,Object>> entrySet = map.entrySet();
Iterator<Entry<String, Object>> iterator = entrySet.iterator();
boolean flag = true;
while(iterator.hasNext()) {
Entry<String, Object> next = iterator.next();
String key = next.getKey();
Object value = next.getValue();
if(flag) {
buffer.append("|> filter(fn: (r) =>");
flag = false;
}else {
buffer.append(join);
}
buffer.append(" r."+key+" "+operator+" \""+value+"\" ");
}
if(!flag) {
buffer.append(") ");
}
}
/**
* 过滤多个字段表达式
* @param buffer
* @param list
* @param innerJoin 【and or】
* @param operator 【== != 】
* @param outerJoin 【and or】
*/
protected void appendMulFilterFlux(StringBuffer buffer, List<Map<String,Object>> list, String innerJoin, String operator, String outerJoin) {
if(list == null || list.size() == 0) {
return ;
}
buffer.append("|> filter(fn: (r) => ");
boolean outerFlag = true;
for(int i = 0; i < list.size(); i++) {
Map<String, Object> map = list.get(i);
Set<Entry<String,Object>> entrySet = map.entrySet();
Iterator<Entry<String, Object>> iterator = entrySet.iterator();
boolean innerFlag = true;
while(iterator.hasNext()) {
Entry<String, Object> next = iterator.next();
String key = next.getKey();
Object value = next.getValue();
if(innerFlag) {
if(outerFlag) {
outerFlag = false;
}else {
buffer.append(outerJoin);
}
buffer.append(" ( ");
innerFlag = false;
}else {
buffer.append(innerJoin);
}
buffer.append(" r."+key+" "+operator+" \""+value+"\" ");
}
if(!innerFlag) {
buffer.append(" ) ");
}
}
buffer.append(" ) ");
}
/**
* 时间窗口统计
* @param buffer
* @param step 步长值【10m,1h,1d...】
* @param aggType 统计类型【sum,count,min,max...)
*/
protected void appendAggregateWindowFlux(StringBuffer buffer, String step, String aggType) {
buffer.append("|> aggregateWindow(every: "+step+", fn: "+aggType+") ");
}
protected void appendWindowFlux(StringBuffer buffer, String step) {
buffer.append("|> window(every: "+step+") ");
}
/**
* 不带时间窗口统计
* @param buffer
* @param aggType 统计类型【sum,count,min,max...)
*/
protected void appendAggregateFlux(StringBuffer buffer, String aggType) {
buffer.append("|> "+aggType+"() ");
}
/**
* 多个查询结果需要指定每个输出结果名称
* @param buffer
* @param name
*/
protected void appendYieldFlux(StringBuffer buffer, String name) {
buffer.append("|> yield(name: \""+name+"\") ");
}
/**
* 将时间指定为某单位
* @param buffer
* @param step
*/
protected void appendTruncateTimeColumn(StringBuffer buffer, String step) {
buffer.append("|> truncateTimeColumn(unit: "+step+") ");
}
/**
* 导入包名
* @param buffer
* @param name 包名
*/
protected void appendImportFlux(StringBuffer buffer, String name) {
buffer.append("import \""+name+"\" ");
}
/**
* 过滤空值
* @param buffer
*/
protected void appendExistsFlux(StringBuffer buffer) {
buffer.append("|> filter(fn: (r) => exists r._value ) ");
}
/**
* 过滤0值
* @param buffer
*/
protected void appendZeroFlux(StringBuffer buffer) {
buffer.append("|> filter(fn: (r) => r._value > 0) ");
}
}
Telegraf
telegraf是个插件,类似ELK的logstash插件,数据管道,可以将一个数据源的数据通过telegraf插件转存到另一个数据源中。
- input
数据输入流,我们目前使用的是RabbitMQ。
[[inputs.amqp_consumer]]
#消息队列基本配置
brokers = ["amqp://127.0.0.1:5672"]
username = "test"
password = "test"
exchange = "IotMsgGateway"
exchange_type = "topic"
exchange_durability = "transient"
queue = "telegraf_iot_device_data_realtime"
queue_durability = "transient"
binding_key = ".#.thing.event.realtime.post"
#数据格式
data_format = "json" #数据格式json
tag_keys = ["productKey","deviceName"] #指定某些字段为标签
name_override = "device_data_realtime" #指定数据存入的表名
json_time_key = "time" #指定某个字段为时间
json_time_format = "unix_ms" #时间属性的格式
#json_timezone = "Local" #时区
json_string_fields = ["deviceType","iotId"] #需要保留的属性字段
- output
[[outputs.influxdb_v2]]
#influxdb数据库配置信息
urls = ["http://127.0.0.1:9999"]
token = "aaaaaaaaa=="
organization = "testOrg"
bucket = "testBucket"
- parse
上面输入流数据用的就是json数据解析。其他数据解析推荐观看github上的说明。(相关链接:Telegraf插件)
Task
可以写一个定时任务,把原始数据统计汇总到新的表中,我也是简单试了一下,不做过多介绍,详情看官方文档。


















 118
118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









