










主题
基于Deepseek视觉语言模型识别与训练九宫格验证码
验证码示例
适用验证码: 某验、某歌等厂商验证码
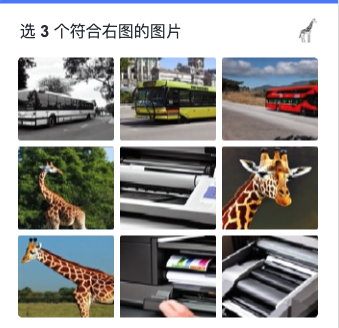

训练思路
- 爬虫采集验证码图片集
- 基于视觉模型识别九宫格中9张小图
- 切割九宫格的九张小图
- 基于视觉模型识别结果对每张小图进行分类标注,标注完成之后则得到了分类训练的数据集
- 基于数据集训练分类模型
- 训练完成之后,测试模型效果
技术栈
| 工具 | – |
|---|---|
| 语言 | Python |
| 视觉模型 | deepseek-ai/deepseek-vl2 |
| 模型API平台 | siliconflow (硅基流动) |
| 分类模型 | YOLOv8 |
训练步骤
爬虫采集图片集
- 使用模拟浏览器访问验证码页面,截图保存九宫格验证码
- 或者访问接口采集验证码图片
顶部附件提供了部分数据集供测试使用(仅20张九宫格图片)
基于Deepseek视觉模型识别图片内容
此处使用siliconflow api, TOKEN 为你的api秘钥,点击此处获取
TOKEN = '你的硅基流动api密钥'
ALL_CLASS = [
"积木",
"船",
"方向盘",
"骆驼",
"剪刀",
"兔子",
"猪",
"行李箱",
"火箭",
"打印机",
"碗",
"地球仪",
"秋千",
"冰箱",
"贝壳",
"拉链",
"铲子",
"长颈鹿",
"望远镜",
"烟斗",
"鼠标",
"订书机",
"眼镜",
"公鸡",
"气球",
"计算器",
"水壶",
"桌子",
"鸟",
"叉子",
"听诊器",
"摩托车",
"伞",
"牛",
"领带",
"电钻",
"乌龟",
"纽扣",
"熊猫",
"捕蚊拍",
"手电筒",
"螺丝刀",
"铁轨",
"轮胎",
"口红",
"插座",
"笔",
"钥匙",
"井盖",
"狗",
"牙刷",
"狮子",
"瓢虫",
"台灯",
"老虎",
"鳄鱼",
"蝴蝶",
"头盔",
"羽毛球",
"羊",
"企鹅",
"足球",
"梳子",
"老虎",
"帽子",
"交通信号灯",
"注射器",
"喷泉",
"鱼",
"手套",
"桥",
"袜子",
"鹿",
"键盘",
"钱包",
"袋鼠",
"书",
"椅子",
"公交车",
"猫",
"猴子",
"手表",
"台球",
"相机",
"救护车",
"轮椅",
"锅",
"过山车",
"音响",
"齿轮",
]
def chat_with_vl(image_path):
with open(image_path, "rb") as f:
image_data = f.read()
# 我们使用标准库 base64.b64encode 函数将图片编码成 base64 格式的 image_url
image_url = f"data:image/{os.path.splitext(image_path)[1]};base64,{base64.b64encode(image_data).decode('utf-8')}"
payload = {
"model": "deepseek-ai/deepseek-vl2",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
{
"type": "text",
"text": """九宫格九张小图编号1-9,识别九宫格图片内容,如果图片包含这些物体(%s),
则返回响应的物体名,以json格式返回结果, 示例 {'1': '积木', '3': '行李箱'}""" % (','.join(ALL_CLASS)),
},
],
},
],
"stream": False,
"max_tokens": 512,
"enable_thinking": False,
"thinking_budget": 4096,
"min_p": 0.05,
"stop": None,
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0,
"response_format": {"type": "text"},
}
headers = {
"Authorization": f"Bearer {TOKEN}",
"Content-Type": "application/json"
}
url = "https://api.siliconflow.cn/v1/chat/completions"
response = requests.request("POST", url, json=payload, headers=headers)
content = pydash.get(response.json(), 'choices.0.message.content')
return content
切割九宫格图片
def split_sudoku(image_path, gap=5):
# 打开原始图片
original_img = Image.open(image_path)
width, height = original_img.size
# 计算每个小图的尺寸
tile_width = (width - 1 * gap) // 3
tile_height = (height - 1 * gap) // 3
# 分割并保存9张图片
for row in range(3):
for col in range(3):
# 计算每个小图的左上和右下坐标
left = col * (tile_width + gap)
upper = row * (tile_height + gap)
right = left + tile_width
lower = upper + tile_height
# 裁剪图片
tile = original_img.crop((left, upper, right, lower))
yield tile
九宫格小图标注
if __name__ == '__main__':
image_dir = 'images_origin'
for index, image_name in enumerate(os.listdir(image_dir)):
image_path = os.path.join(image_dir, image_name)
# 视觉模型识别
content = chat_with_vl(image_path)
content = content.strip('```').strip('json')
print('image_path', image_path, 'content', content)
try:
no_to_name = json.loads(content)
except Exception as e:
print('图片识别失败', content)
continue
for i, tile in enumerate(split_sudoku(image_path)):
no = i + 1
tile_class = no_to_name.get(str(no))
if tile_class is None:
continue
class_dir = os.path.join('datasets', tile_class)
if not os.path.exists(class_dir):
os.makedirs(class_dir)
# tile图片保存到class_dir文件夹,图片名格式为{image_name}_{no}.png
tile.save(os.path.join(class_dir, image_name.split('.')[0] + '_' + str(no) + '.png'))
拆分数据集为 test(测试数据集)和 train(训练数据集)
import os
import shutil
def split_dataset(origin_dir, target_dir, train_ratio=0.8):
# 确保目标目录存在
if not os.path.exists(target_dir):
os.makedirs(target_dir)
# 创建train和test目录
train_dir = os.path.join(target_dir, 'train')
test_dir = os.path.join(target_dir, 'test')
os.makedirs(train_dir, exist_ok=True)
os.makedirs(test_dir, exist_ok=True)
# 遍历origin_dir下的所有子文件夹
for class_name in os.listdir(origin_dir):
class_path = os.path.join(origin_dir, class_name)
if os.path.isdir(class_path):
# 创建train和test子文件夹
train_class_dir = os.path.join(train_dir, class_name)
test_class_dir = os.path.join(test_dir, class_name)
os.makedirs(train_class_dir, exist_ok=True)
os.makedirs(test_class_dir, exist_ok=True)
# 获取所有图片文件
images = [f for f in os.listdir(class_path) if f.endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif'))]
# 计算分割点
split_index = int(len(images) * train_ratio)
# 分割图片到train和test文件夹
for i, image in enumerate(images):
src_image_path = os.path.join(class_path, image)
if i < split_index:
dst_image_path = os.path.join(train_class_dir, image)
else:
dst_image_path = os.path.join(test_class_dir, image)
shutil.copy(src_image_path, dst_image_path)
# 使用示例
origin_dir = 'datasets'
target_dir = 'datasets-split'
split_dataset(origin_dir, target_dir)
拆分好的数据集文件夹为 datasets-split
训练模型
from ultralytics import YOLO
model = YOLO("models/yolov8n-cls.pt")
model.train(
data="datasets-split",
epochs=500,
imgsz=128,
batch=16,
device='cpu',
name="suduku",
patience=50,
)
print('done')
测试模型效果
import os
from ultralytics import YOLO
# 测试模型效果
onnx_model = YOLO("runs/classify/suduku/weights/best.pt",
task='classify'
)
dirpath = '<test image>'
for file in os.listdir(dirpath):
file_path = os.path.join(dirpath, file)
results = onnx_model.predict(source=file_path,
imgsz=128,
)
# Process results list
for result in results:
print(result.probs.top1)
print(result.probs.top1conf)
print(result.probs.top5)
print(result.probs.top5conf)
资源消耗
使用Deepseek视觉语言模型,标注了1518张九宫格验证码图片,资源消耗如下,标注成本0.85元
| 资源 | Tokens消耗量 | 单价 | 总价 |
|---|---|---|---|
| tokens | 86万 tokens | 0.99/ M Tokens | 0.85元 |
小结
- 针对九宫格验证码,使用视觉语言模型标注替代人工标注,可以极大的减少标注数据的时间
- 使用视觉语言模型标注成本极低
- 视觉语言模型对九宫格验证码识别效果极好
- 最终训练出的分类模型识别成功率98%
- 视觉语言模型对滑块验证码以及有干扰的数字字母验证码和倾斜的汉字验证码的识别效果一般[/md]


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











