







注意以下字母皆代表矩阵
过拟合:不重要信息或错误的拟合,深度神经网络含有大量非线性隐含层,使得模型表达能力非常强。在有限的训练数据下,导致学习了很多样本噪声的复杂关系,而测试样本中可能并不存在这些复杂关系。这就导致了过拟合.
而Dropout和正则项,(https://blog.youkuaiyun.com/qq_29381089/article/details/80406428)对过拟合都有很好的解决
1.Dropout
前行传播
rlj∼Bernouli(p) r j l ∼ B e r n o u l i ( p )
ŷ l=rl⨀al−1,al−1为第l−1层输出 y ^ l = r l ⨀ a l − 1 , a l − 1 为 第 l − 1 层 输 出
al=wlŷ l+bl a l = w l y ^ l + b l
⋅⋅⋅
⋅
⋅
⋅
al+n=wl+nŷ l+n+bl+n
a
l
+
n
=
w
l
+
n
y
^
l
+
n
+
b
l
+
n
最后预测:
output=al+n⨀p
o
u
t
p
u
t
=
a
l
+
n
⨀
p
这里最后输出结果乘以p的原因,网上给出的解释:
在测试阶段将激活函数以q为比例系数进行缩放,以便将训练阶段产生的预期输出作为测试阶段使用的单个输出,没get到具体什么意思.好在实际使用的时候用的下面这种反向dropout,效果更加
反向Dropout
rlj∼Bernouli(p)(1) (1) r j l ∼ B e r n o u l i ( p )
ẑ l=rl⨀al−1⨀11−p,al−1为第l−1层输出(2) (2) z ^ l = r l ⨀ a l − 1 ⨀ 1 1 − p , a l − 1 为 第 l − 1 层 输 出
zl=wlŷ +bl(3) (3) z l = w l y ^ + b l
al=σ(zl)(4) (4) a l = σ ( z l )
如此做的原因:
相对于使用过Dropout的
zl=wlŷ +bl
z
l
=
w
l
y
^
+
b
l
如果当前层没使用dropout,那么
z′l=wlal−1+bl
z
′
l
=
w
l
a
l
−
1
+
b
l
取其中
wlkal−1k
w
k
l
a
k
l
−
1
作为分析(下面的i表示一个batch中第i个数据):
设加了Dropout的,为
m(i)
m
(
i
)
=
wlkyl−1k
w
k
l
y
k
l
−
1
未加的,为
m′(i)=w′lka′l−1k
m
′
(
i
)
=
w
k
′
l
a
k
′
l
−
1
因为训练采用的批训练,这意味着最终前向输出时,
∑bathci=1m′(i)=btachsize⋅μ⋅(1−p)
∑
i
=
1
b
a
t
h
c
m
′
(
i
)
=
b
t
a
c
h
s
i
z
e
⋅
μ
⋅
(
1
−
p
)
差不多是
(∑batchi=1m(i))11−p=batchsize⋅μ
(
∑
i
=
1
b
a
t
c
h
m
(
i
)
)
1
1
−
p
=
b
a
t
c
h
s
i
z
e
⋅
μ
,导致
zl和z′l
z
l
和
z
′
l
差别比较大,
所以,在公式(2),后面乘了
11−p
1
1
−
p
,个人感觉是减少含Dropout的层对其前后层的影响
从这里理解Dropout可以减轻过拟合的原因:
个人理解和网上不太一样,因为神经网络是高VC纬的,而训练本质还是求出网络损失函数最小值时,网络里面一堆参数的值.而Dropout可以理解为从不同”面”(正如三维空间里面的,正面,侧面,底面等),当然”面”也是高纬的.假设最后的损失函数为
C=(w0x0+w1x1+b)2
C
=
(
w
0
x
0
+
w
1
x
1
+
b
)
2
,而当
x0
x
0
输入出现了噪声,则这个噪声会对
w1
w
1
的更新也会造成影响,但如果换个面,设直接将
w0x0
w
0
x
0
置0,相当于从
w0=0
w
0
=
0
这个面去看损失函数,这样梯度更新便不会被噪声
x0
x
0
影响了,而在高VC纬中,从多个高纬度的”面”,随机避开部分数据的输入,用最终平均的结果降低噪声的影响
在文章Appendix中,作者给了A Practical Guide for Training Dropout Networks:
Network Size:
采用dropout后,隐`含层节点数n要按照n/p增加;
Learning Rate and Momentum:
因为dropout在梯度下降中引入了大量的噪声导致梯度相互抑制,因此学习速率要增加10-100倍。另外一个减少噪声的方法是用momentum,momentum对于标准网络一般采用0.9,对于dropout网络一般是0.95-0.99。两个方法可以同时采用。
Max-norm Regularization:
防止学习过快导致网络增长太大,一般给隐含层权重的norm一个上限c,c一般取值3-4。
Dropout Rate:
一般取值0.5-0.8之间。drop比例p越小,要求隐含层n越大,训练也会越慢且可能欠拟合。
2.正则项
正则项实际是根据概率路两大学派的思想,退出来,所以先贴一波网上对这两大学派的介绍:
频率学派
认为需要推断的参数 θ 视作未知的定值,而样本X是随机的,其着眼点在样本空间,有关的概率计算都是针对 X 的分布。频率学派认为参数虽然我们不知道,但是它是固定的,我们要通过随机产生的样本去估计这个参数,所以才有了最大似然估计这些方法。
贝叶斯学派
把参数 θ 也视作满足某一个分布的随机变量,而样本X是固定的,其着眼点在参数空间,重视参数 θ 的分布,固定的操作模式是通过参数的先验分布结合样本信息得到参数的后验分布。
A.不加正则项–频率学派
而一般用的不加正则项用的是频率学派的最大似然估计:
设数据集合大小为n,w参数个数为m,即:
X=x(0),x(1),⋅⋅⋅,x(n)
X
=
x
(
0
)
,
x
(
1
)
,
⋅
⋅
⋅
,
x
(
n
)
标签
y=y(0),y(1)⋅⋅⋅y(n)
y
=
y
(
0
)
,
y
(
1
)
⋅
⋅
⋅
y
(
n
)
w=w0,w1,⋅⋅⋅wm
w
=
w
0
,
w
1
,
⋅
⋅
⋅
w
m
这里
xi
x
i
为多元输入的矩阵形式
频率学派把
w
w
看成参数,而不是随机分布
利用最大似然性求
那么根据正态分布的叠加性有
y(i)|x(i);w∼N(wTx(i),δ2) y ( i ) | x ( i ) ; w ∼ N ( w T x ( i ) , δ 2 ) ,
所以:
最终得到一般的方差损失函数: (y(i)−wTx(i))2 ( y ( i ) − w T x ( i ) ) 2
B.加正则项–贝叶斯学派
而对于贝叶斯派,则把w看成分布,同样假设
p(y|X,w)
p
(
y
|
X
,
w
)
为正态分布,那么最大化:
1)如果
p(w)∼N(0,α2)
p
(
w
)
∼
N
(
0
,
α
2
)
,则:
L2(w)=log[p(y|X,w)⋅p(w)]=log(p(y|X,w))+log(p(w))=L+log(p(w)) L 2 ( w ) = l o g [ p ( y | X , w ) ⋅ p ( w ) ] = l o g ( p ( y | X , w ) ) + l o g ( p ( w ) ) = L + l o g ( p ( w ) )
而
所以最终结果,在L上加了L2正则项
∑mj=1(wj)22α2
∑
j
=
1
m
(
w
j
)
2
2
α
2
:
一般忽略常数项 m⋅log(1α2π√) m ⋅ l o g ( 1 α 2 π ) ,便得到:
2)若假设
wj
w
j
服从均值为0、参数为 a 的拉普拉斯分布,即:
所以:
所以L1正则项为 −∑mi=1|wj|a − ∑ i = 1 m | w j | a
忽略常数项得:
虽然知道由来了,但是从这里似乎看不出正则项会带来什么效果……
好吧,先看梯度,再解释
梯度求解
设未加正则化的损失函数为
L
L
则L2正则化:
梯度:
则梯度下降:
贴上网上对此的理解
我们通过一个例子形象理解一下L2正则化的作用,考虑一个只有两个参数w1和w2的模型,其损失函数曲面如下图所示。从a可以看出,最小值所在是一条线,整个曲面看起来就像是一个山脊。那么这样的山脊曲面就会对应无数个参数组合,单纯使用梯度下降法难以得到确定解。但是这样的目标函数若加上一项
0.1×(w21+w22)
0.1
×
(
w
1
2
+
w
2
2
)
,则曲面就会变成b图的曲面,最小值所在的位置就会从一条山岭变成一个山谷了,此时我们搜索该目标函数的最小值就比先前容易了,所以L2正则化在机器学习中也叫做“岭回归”(ridge regression)。

L1正则项:
梯度:
其中 sgn(w) s g n ( w ) 为符号函数,
梯度下降:
L1 正则化除了和L2正则化一样可以约束数量级外,L1正则化还能起到使参数更加稀疏的作用:
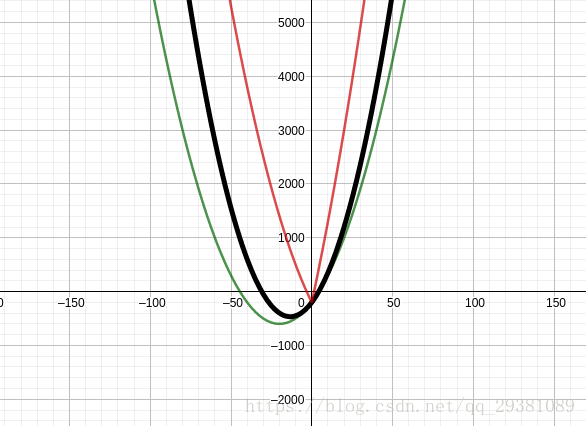
假设这里绿线为未加正则化的损失,黑线加了L2正则项 0.5x2 0.5 x 2 ,红线加了L1正则项 100|x| 100 | x | ,
可以看出,加了L1正则项后,红线最低点在0点处.主要利用了绝对值函数对负数的取反效果
等值图解释
另外在PRML里面有另一种直观的解释:
本质上我们要
min(L+λ∑mi=1|wi|q)
m
i
n
(
L
+
λ
∑
i
=
1
m
|
w
i
|
q
)
,
如果这里m=2,那么
∑mi=1|wi|q)
∑
i
=
1
m
|
w
i
|
q
)
,在q=0.5,1,2,3的等高线图如下:
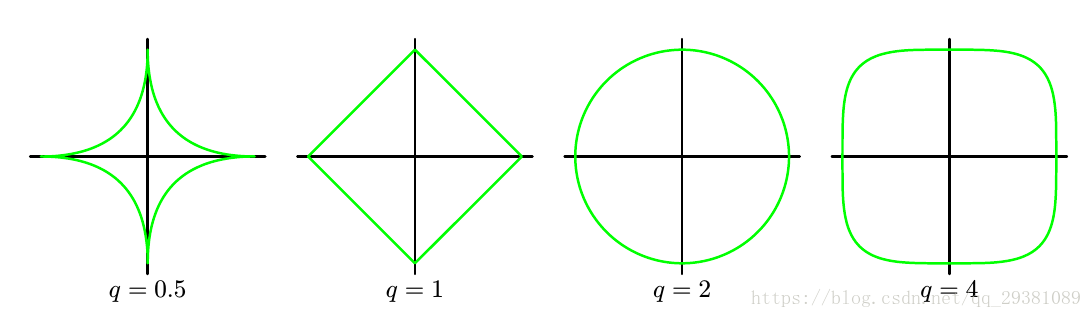
而存在一个
η
η
,使得
min(L+λ∑mi=1|wi|q)
m
i
n
(
L
+
λ
∑
i
=
1
m
|
w
i
|
q
)
等效于:
在
∑mi=1|wi|q)≤η
∑
i
=
1
m
|
w
i
|
q
)
≤
η
条件下,求
min(L)
m
i
n
(
L
)
那么同样以m=2为例,在q=1,2即L1,L2正则下的等值线图:
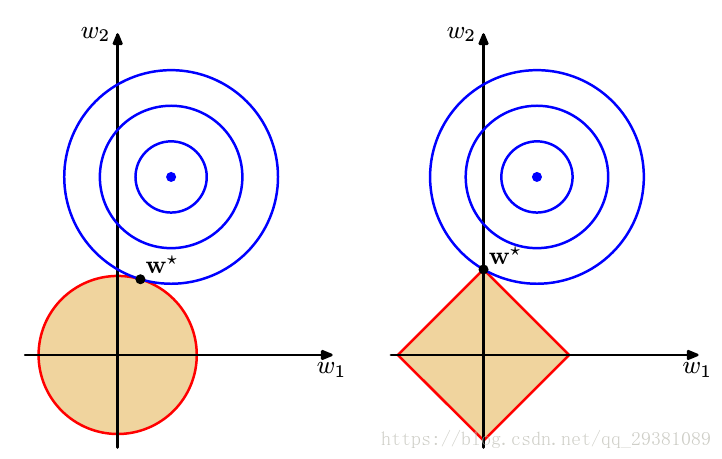
可以看出右图的L1正则和L相交点(即 argminw(L1) a r g m i n w ( L 1 ) ), 有w=0 有 w = 0 的点比L2更多
那么为什么正则项目可以减轻过拟合?
知乎有个解释很容易理解:
过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
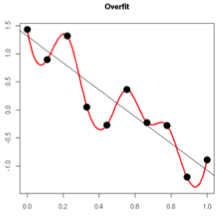
而正则化是通过约束参数的范数使其不要太大(毕竟有
∑mi=1|wi|q)≤η
∑
i
=
1
m
|
w
i
|
q
)
≤
η
限制),所以可以在一定程度上减少过拟合情况。
主要参考:
https://www.zhihu.com/question/37096933
https://ask.julyedu.com/question/150
prml pdf

















 2678
2678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









