




 本文介绍了单应性变换在图像处理中的作用,通过BFMatcher获取匹配关键点并利用单应性变换矩阵进行图像转换。然而,匹配点可能存在异常,为此引入RANSAC算法进行随机抽样一致性的拟合,有效排除异常点影响,提高图像拼接的准确性。通过SIFT检测关键点和BFMatcher匹配,最终实现图像的精确拼接。
本文介绍了单应性变换在图像处理中的作用,通过BFMatcher获取匹配关键点并利用单应性变换矩阵进行图像转换。然而,匹配点可能存在异常,为此引入RANSAC算法进行随机抽样一致性的拟合,有效排除异常点影响,提高图像拼接的准确性。通过SIFT检测关键点和BFMatcher匹配,最终实现图像的精确拼接。
一:单应性变换
我们得到两张图像的图像后,可以通过BFMatcher得到匹配的点,其实就是一个暴力搜索来比较最相近的特征点(128维度的向量,求向量的近似度)。
通过匹配的多个关键点的配对信息,我们能将图像A转换到图像B的角度和size。这就可以用到单应性变换。
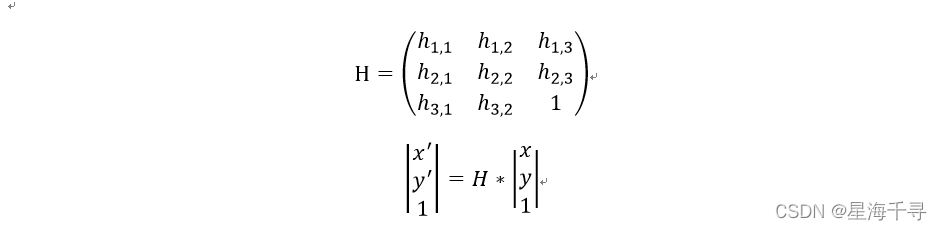
通过这个矩阵可以将原始图像A中的关键点变换到图像B,可以看到H矩阵很关键,H矩阵一共有8个未知参数,但是我们已经有大量的匹配的配对的关键点,因此我们可以通过8个式子的方程组求解H,因此至少需要4组配对值即可求解。
但是问题存在于,我们得到的匹配的关键点真的是最好的么?从上次学习的KNNMatcher可以得到,有的匹配点虽然很相近,但其实不是图像整体的透视变换下应该匹配到的,不符合整体变换规律,这些我们逻辑上认为错误的匹配对儿就是异常点了。
如果将图像A的关键点看做X,那么B图像的关键点就是Y,我们的H矩阵就是变换参数,我们现在得知了X和Y,求H,其实就是拟合的操作,上述可知,只要4对儿X和Y即可求得H,但是我们并不知道这4对儿中是否包含了异常点。因此传统的拟合方式可能并不是很适合。
那么这个异常点干扰拟合的方式怎么解决呢?
二:RANSAC(Random Sample consensus)介绍
也称之为随机抽样一致性算法,或者说是一种新的拟合思想。
它是解决什么问题呢?如下,我们需要拟合一堆离散点,使用传统的最小二乘法去拟合的话,就会尽量的去拟合所有的点,照顾到所有的点(包括异常点),这样难免结果会有偏差。
RANSAC算法的思路就是,我随机找到一些部分点来提前拟合出拟合函数的参数,如果是拟合直线,那么最少需要俩个点,如果是需要抛物线,则最少需要是三个点。
1:随机找能求出参数的最少的点,拟合出参数H,设置一个误差阈值,得到了一个拟合函数,统计在误差范围内的点的个数。
2:循环步骤一
3:比较所有的H,找到允许误差范围内能包含最多的点个数的H。这个H就是我们期望的H。
效果差异如下图所示:绿色线是RANSAC算法的拟合结果,红色线是普通的最小二乘拟合。
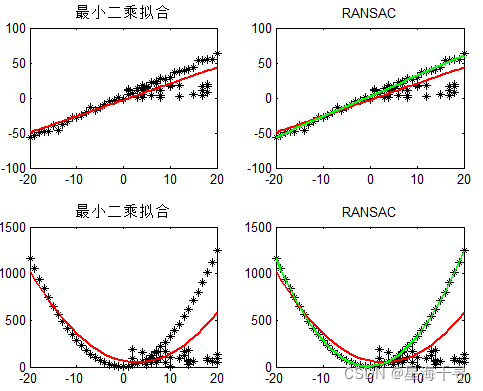
但是RANSAC算法的效果受到多种因素影响
1:每一次选取的点的个数,直线需要2个点,二次曲线需要3个点,三次曲线需要4个点。一般来说,Nums少一些易得出较优结果
2:迭代次数,迭代次数太多导致计算量大,太少了容易得不到好的结果。
3:允许的误差范围阈值。
RANSAC的作用有点类似:将数据一切两段,一部分是自己人(在范围阈值内),一部分是敌人(范围阈值内),自己人留下商量事情但是得统计多少是自己人,敌人赶出去。RANSAC开的是家庭会议,不像最小二乘总是开全体会议,得照顾全部人的诉求。
该算法的作用就是可以用于图像的拼接。
下面我將举个实际的图像拼接的例子
import cv2
import numpy as np
def cv_show_image(name, img):
print(img.shape)
cv2.imshow(name, img)
cv2.waitKey(0) # 等待时间,单位是毫秒,0代表任意键终止
cv2.destroyAllWindows()
def matchKeyPoints(bf, kptA, dpA, kptB, dpB 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+




 到【灌水乐园】发言
到【灌水乐园】发言







