







 本文介绍了一种爬取摄影网站图片的方法,通过使用Python的BeautifulSoup和Selenium库,实现自动下载图片及其相关信息。该方法能够遍历不同标签页并持续抓取图片直至最后一页。
本文介绍了一种爬取摄影网站图片的方法,通过使用Python的BeautifulSoup和Selenium库,实现自动下载图片及其相关信息。该方法能够遍历不同标签页并持续抓取图片直至最后一页。
今天我们来爬取另外个网站https://photo.fengniao.com 没错就是这个地址,不用翻其他的标签栏,,这个网站最大的特点就是一直往下翻都会有一个加载的操作,不断加载新的图片上去。可以试着滑动鼠标不断往下翻,不断往下翻,不断往下翻。。。。

总之啊,天荒地老海枯石烂啊,今天我们试着两种不同的方式来搞定它。下一博文写另外一种方法来搞定。
在“图库”有多的子标签,按照子标签进一步划分。
每到一个子标签,点击第一张图片进去。
会发现这里又查看原图,下一页等信息,都是可以做直接抓取的。
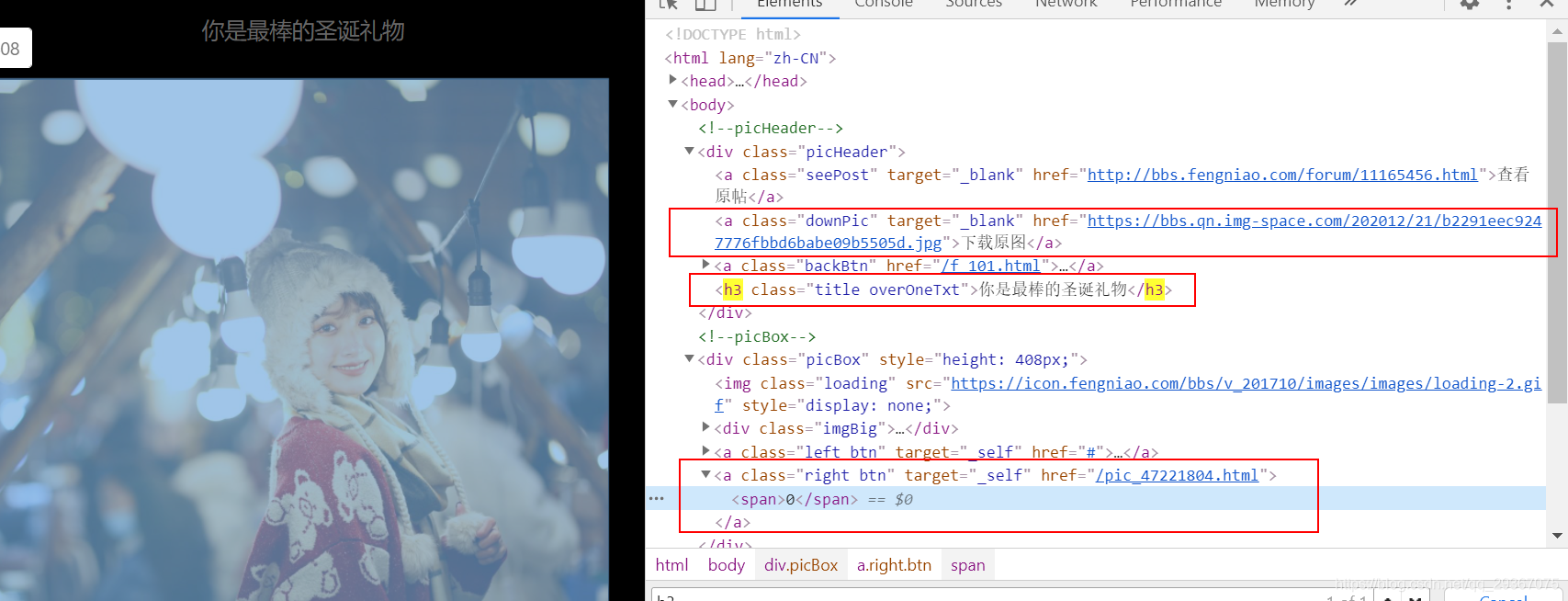
而且按照这个下一页的三角箭头,可以一直一直翻看后面的照片,很爽啊。于是一个大大的while循环就会出现了。
完整代码如下:
# coding: utf-8
from concurrent.futures import ThreadPoolExecutor
import time
import os
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
rootrurl = 'https://photo.fengniao.com'
save_dir = 'D:/estimages/'
chromeExeLoc = 'D:/software/chrome/chromedriver_win32/chromedriver.exe'
headers = {
"Referer": rootrurl,
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
} ###设置请求的头部,伪装成浏览器
def saveOneImg(dir, img_url):
new_headers = {
"Referer": img_url,
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
} ###设置请求的头部,伪装成浏览器,实时换成新的 header 是为了防止403 http code问题,防止反盗链,
try:
img = requests.get(img_url, headers=new_headers) # 请求图片的实际URL
if (str(img).find('200') > 1):
with open(
'{}/{}.jpg'.format(dir, img_url.split('/')[-1]), 'wb') as jpg: # 请求图片并写进去到本地文件
jpg.write(img.content)
print(img_url)
jpg.close()
return True
else:
return False
except Exception as e:
print('exception occurs: ' + img_url)
print(e)
return False
def saveOnePageFunc(dir, url):
tmpUrl = url
idx = 1
while 1:
html = BeautifulSoup(requests.get(tmpUrl, headers=headers).text, features="html.parser")
imgUrl = html.find('a', {'class' : 'downPic'}).get('href')
imgText = html.find('h3').string
saveOneImg(dir, imgUrl)
tmpUrl = html.find('a', {'class' : 'right btn'}).get('href')
if tmpUrl.find('html') < 0:
break
tmpUrl = rootrurl + tmpUrl
idx = idx + 1
print('this tag is over.')
# 单个spider thread
def tagSpider(tag, url):
# 按照tag和图片组的内容来创建目录
new_dir = '{}/{}'.format(save_dir, tag)
if not os.path.exists(new_dir):
os.makedirs(new_dir)
html = BeautifulSoup(requests.get(url, headers=headers).text, features="html.parser")
firstImgUrl = html.find('div', {'class' : 'picList'}).find('li').find('a').get('href')
saveOnePageFunc(new_dir, rootrurl + firstImgUrl)
def getAllTags():
list = {}
html = BeautifulSoup(requests.get(rootrurl, headers=headers).text, features="html.parser")
a_s = html.find('div', {'class' : 'menuPic'}).find_all('a')
for a in a_s:
list[a.get_text()[:-1]] = a.get('href')
return list
if __name__ == '__main__':
# # 获得所有标签
taglist = getAllTags()
print(taglist)
#
# 给每个标签配备一个线程
with ThreadPoolExecutor(max_workers=15) as t: # 创建一个最大容纳数量为20的线程池
for tag, url in taglist.items():
t.submit(tagSpider, tag, url)
# 单个连接测试下下
# tagSpider('其他', 'http://photo.fengniao.com/f_999.html')
# 等待所有线程都完成。
while 1:
print('-------------------')
time.sleep(1)
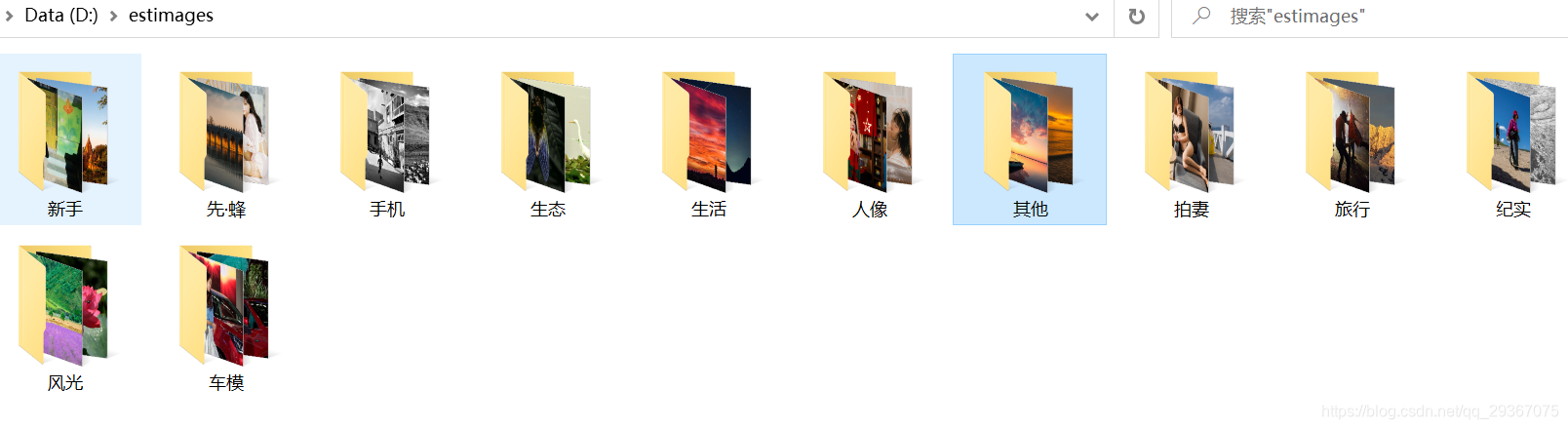
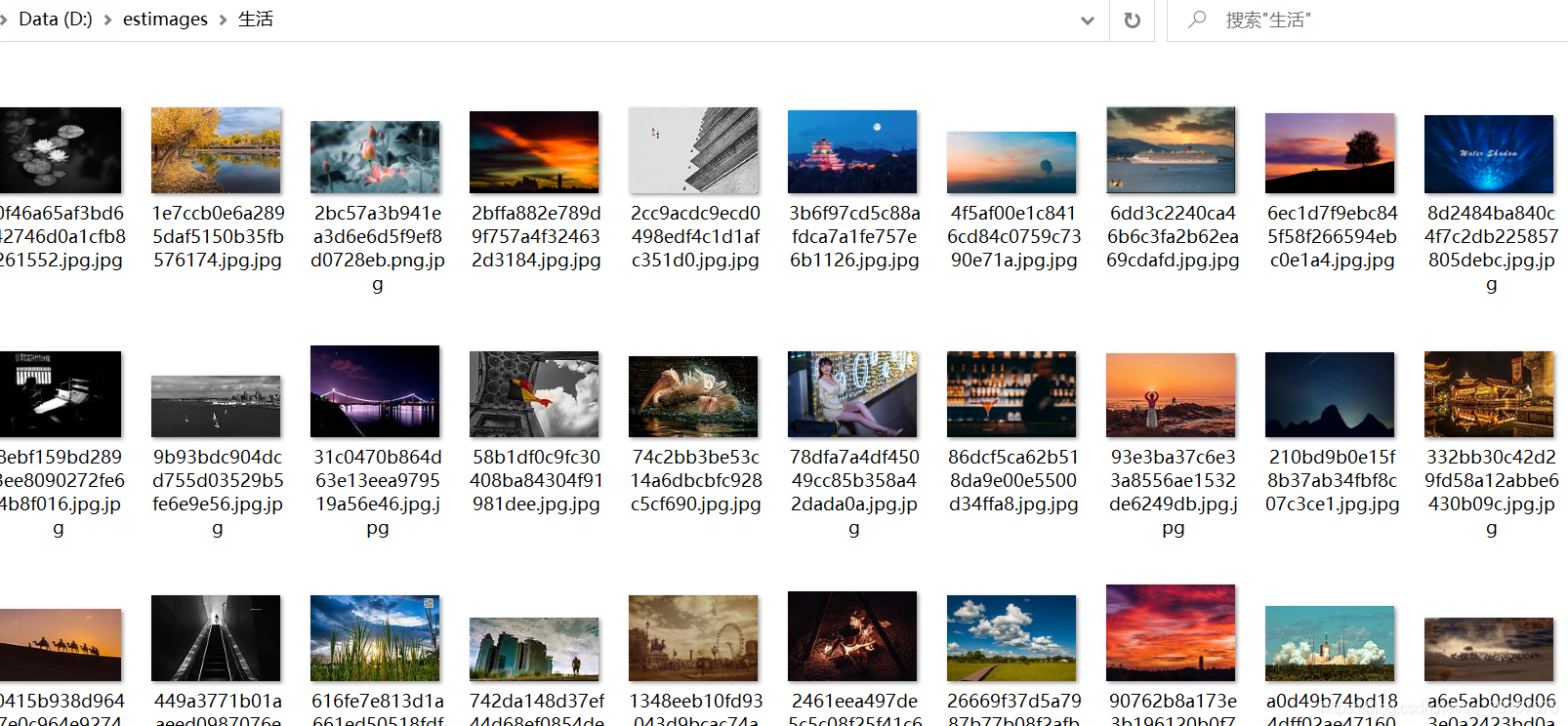
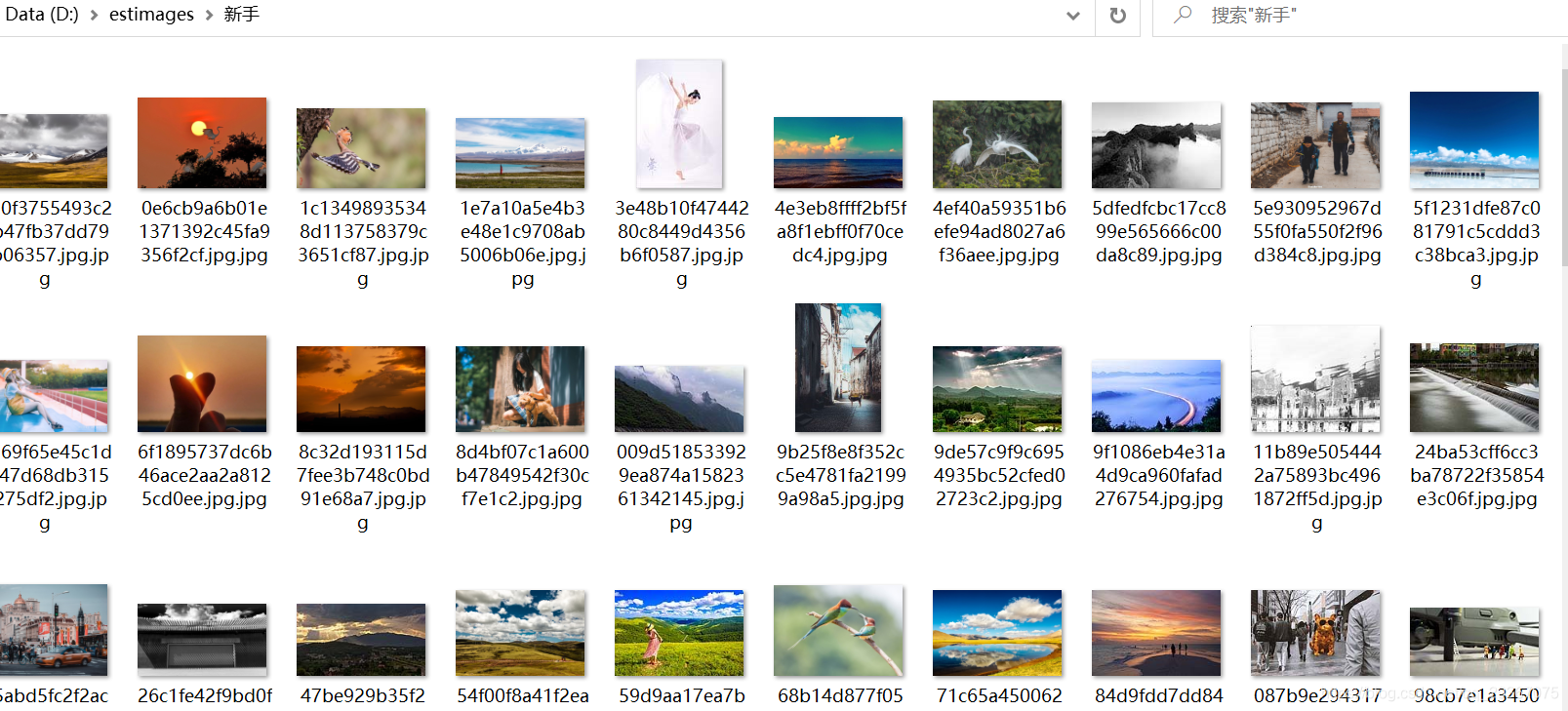
效果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









