




 本文对比了自编码器(AE)和变分自编码器(VAE)的工作原理,AE聚焦于数据压缩和去噪,而VAE则强调数据生成能力,通过正态分布映射创造新样本。VAE的潜在空间类似于高斯混合模型,适用于多样数据生成。
本文对比了自编码器(AE)和变分自编码器(VAE)的工作原理,AE聚焦于数据压缩和去噪,而VAE则强调数据生成能力,通过正态分布映射创造新样本。VAE的潜在空间类似于高斯混合模型,适用于多样数据生成。
最近学习了VAEGAN,突然对VAE和AE的概念和理解上变得模糊了,于是赶紧搜索资料,重新理解一番。
一:AE
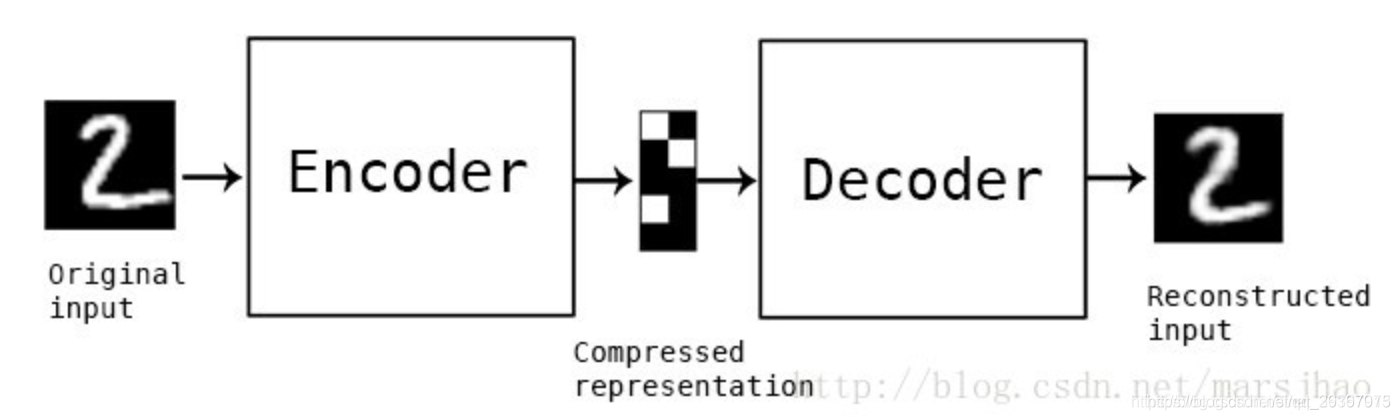
输入的图片数据X经过encoder后会得到一个比较确切的latent code Z,这个Z通过decoder重建出图像X’,我们的损失函数就是X和X’的重建损失值。
AE特点就是:
自动编码器是数据相关的(data-specific 或 data-dependent),这意味着自动编码器只能压缩那些与训练数据类似的数据,反过也是一类数据对应一种编码器,无法拓展一种编码器去应用于另一类数据。
自动编码器是有损的,意思是解压缩的输出与原来的输入相比是退化的,MP3,JPEG等压缩算法也是如此。这与无损压缩算法不同。
正是由于这些特点,目前自编码器的应用主要有两个方面,第一是数据去噪,第二是为进行可视化而降维。配合适当的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。
二:VAE
相比于自编码器,VAE更倾向于数据生成。只要训练好了decoder,我们就可以从某一个标准正态分布(一个区间)生成数据作为解码器decoder的输入,来生成类似的、但是但不完全相同于训练数据的新数据,也许是我们从来没见过的数据,作用类似GAN。
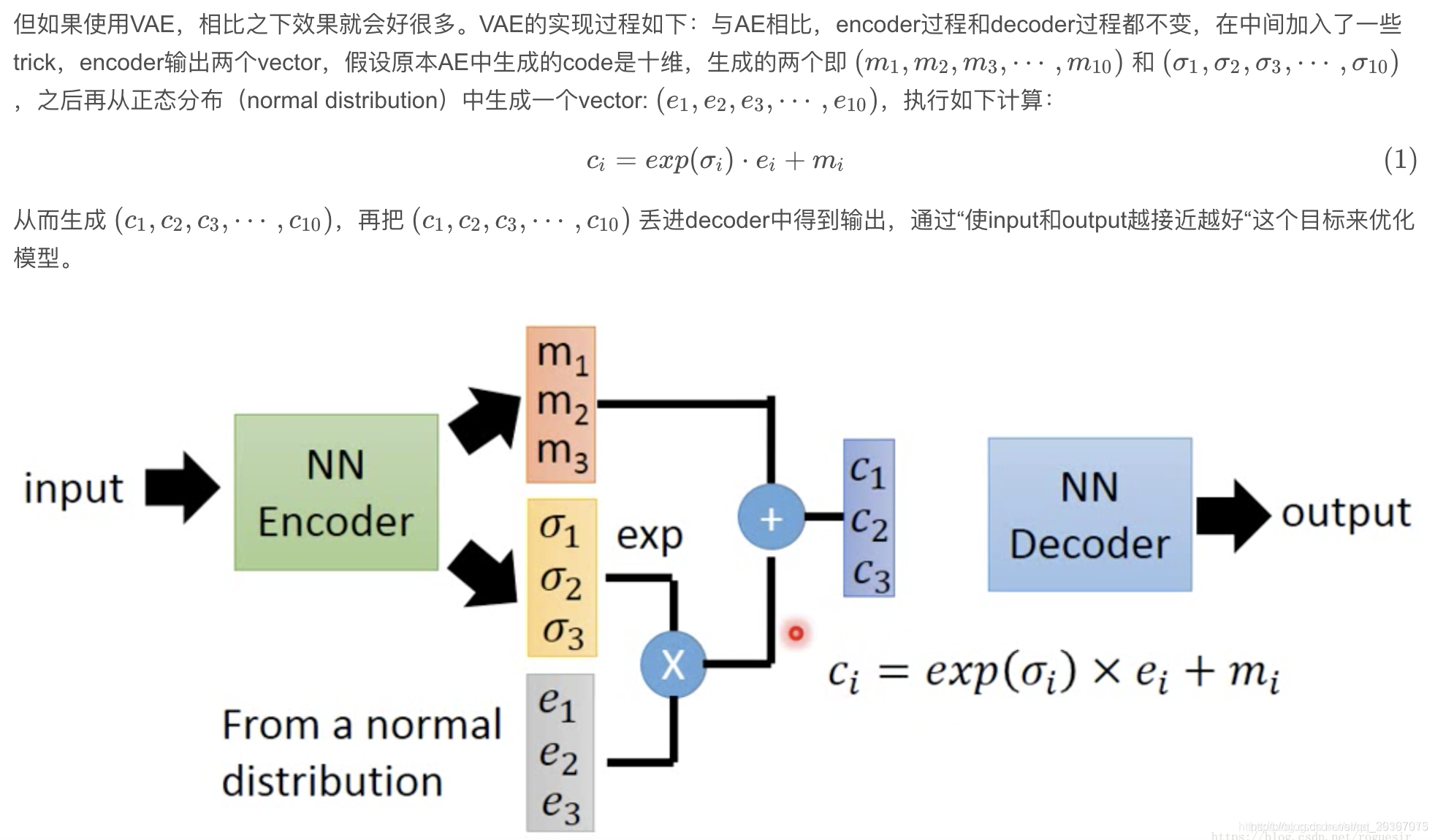
图中的向量e服从于正态分布N(μ_noise,σ_noise),它的作用就是在正态分布N(m,σ)中进行随机采样。
m,σ都是从数据X中产生的,也就是数据X会产生一个正太分布,这个正太分布的所有采样值,在理论上都是可以重建出X’,根据采样值的不同,重建出的X’是类似但不完全相同的。因此可以产生出一些新的数据,所以VAE更具有创造性,更偏向于数据生成。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1697
1697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









