




这一期的RL学习全是学习自李宏毅老师的教程,在自己多次学习后,自以为比较能理解后,才写下来了的。因此很多截图呢直接来自李宏毅老师的截图,很多地方我就不亲自写式子了。
本文讲解Value-Based的方法。
一:基本介绍
我们之前在policy-based中学习的是一个Actor,也就是输入一个S,输出一个Action(各个Action的概率,取最大概率的Action)。
现在我们是 value-based 的方法,那么就是要去学习一个critic,它不直接采取行动,它是对现由的Actor做出好坏的评价。


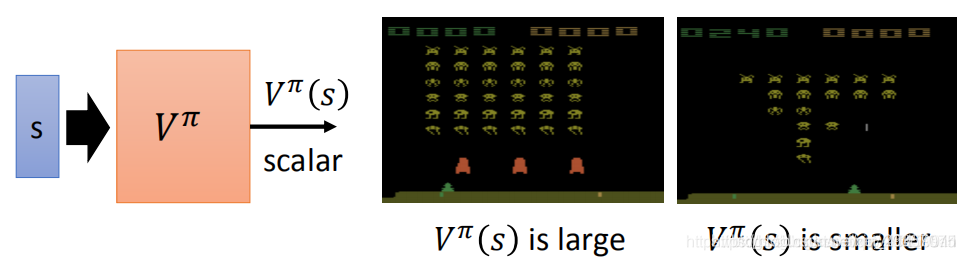


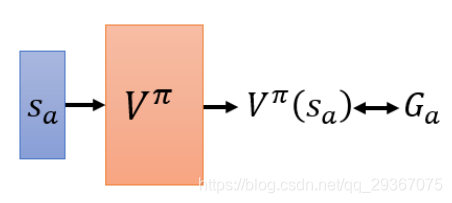

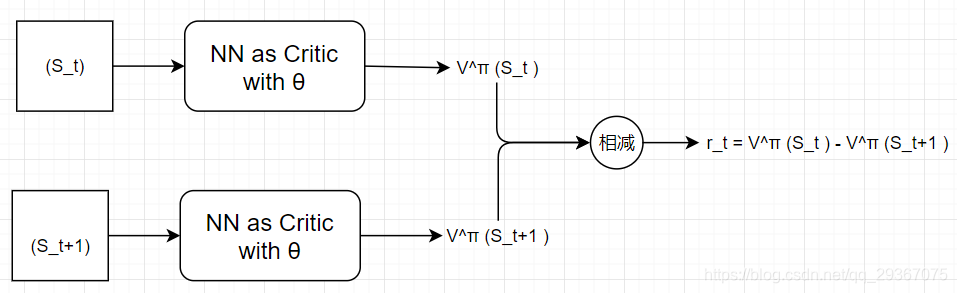

二者之间还是由差距的。
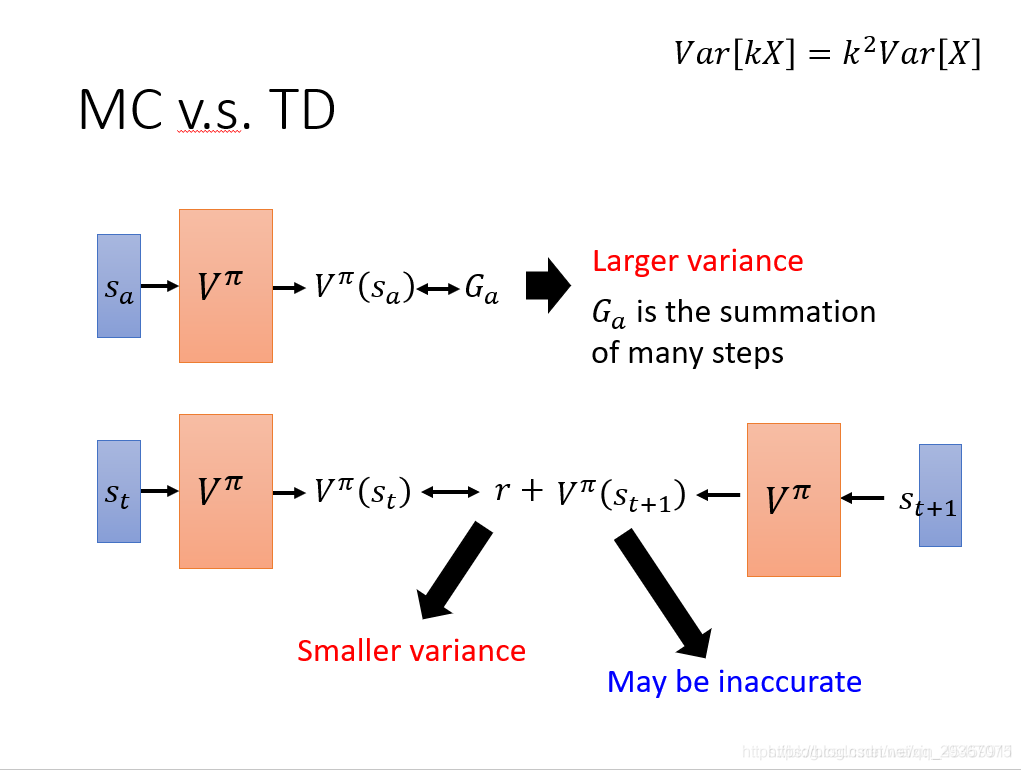
MC方法得要花时间等episode结束才能计算,我们知道每一步骤存在随机性,步骤太多的话,不确定性太多,不稳定性极高,方差太大。
TD方法每次只需要一部或者几步即可,效率上要高一些,它引入的不确定性少很多,方差就小一些,但是很可能会不准确。


















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









