




在上一篇博客最后,我们说到了θ和θ^k是不能差太多的,不然结果会不好,那么怎么避免它们差太多呢?
这就是这一篇要介绍的PPO所在做的事情。
1:PPO1算法:



2:TRPO算法

3:PPO2算法


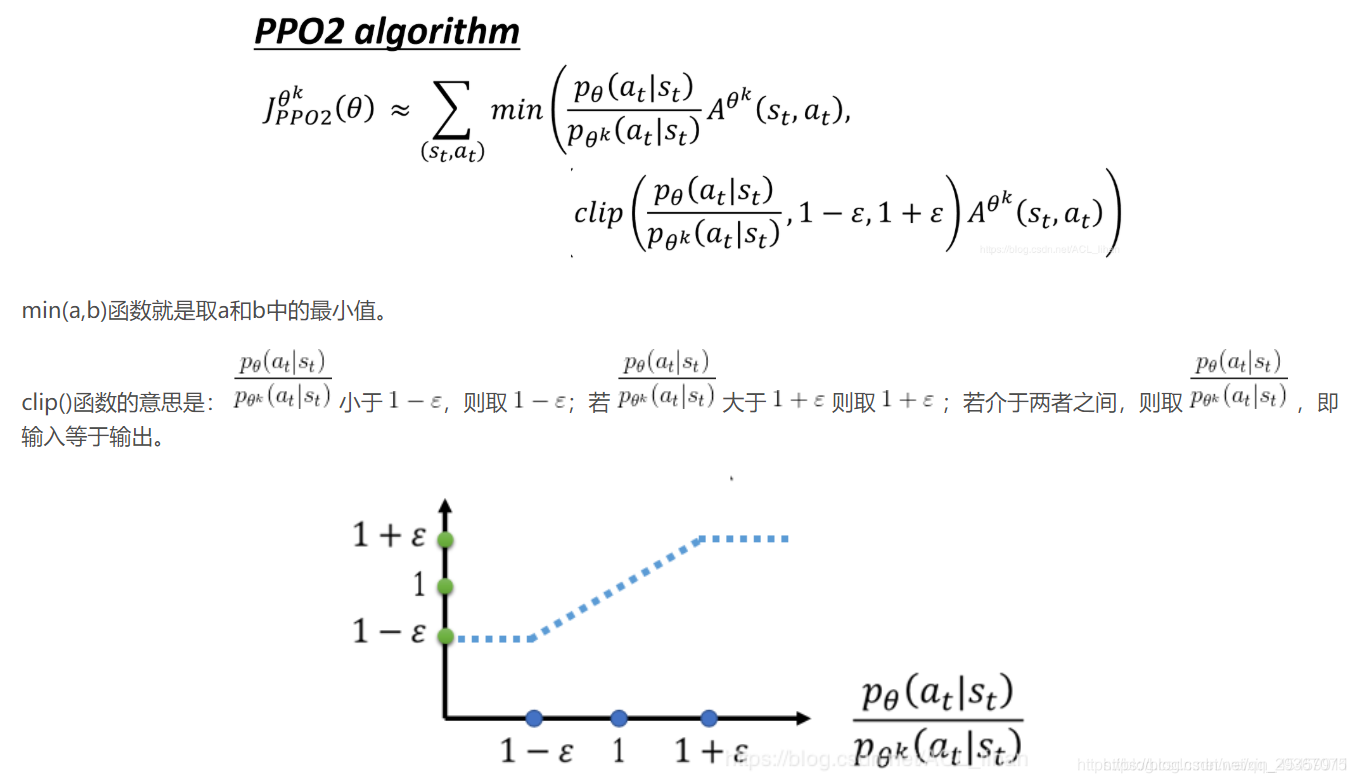

 本文将详细介绍如何通过PPO算法来确保θ和θ^k之间的差异不会过大,从而提高结果的质量。文章将依次介绍PPO1、TRPO及PPO2算法。
本文将详细介绍如何通过PPO算法来确保θ和θ^k之间的差异不会过大,从而提高结果的质量。文章将依次介绍PPO1、TRPO及PPO2算法。
在上一篇博客最后,我们说到了θ和θ^k是不能差太多的,不然结果会不好,那么怎么避免它们差太多呢?
这就是这一篇要介绍的PPO所在做的事情。
1:PPO1算法:
2:TRPO算法
3:PPO2算法
 225
577
225
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























