




 本文介绍了一种跨语言情感分析的embedding方法,通过将不同语言映射至同一向量空间,仅需源语言情感标注即可进行目标语言情感分类。模型采用线性投影矩阵实现双语词典对齐,并通过joint learning优化分类预测。
本文介绍了一种跨语言情感分析的embedding方法,通过将不同语言映射至同一向量空间,仅需源语言情感标注即可进行目标语言情感分类。模型采用线性投影矩阵实现双语词典对齐,并通过joint learning优化分类预测。
Bilingual Sentiment Embeddings论文笔记
前言
这篇文章主要是为了做跨语言的情感分析,提出了一种embedding的方法。
核心思想就是将两种不同的语言映射到同一个向量空间上。这样只需要一个标注好情感label的source language,一个双语词典L,每种语言的embedding,就可以对target language做情感分类。
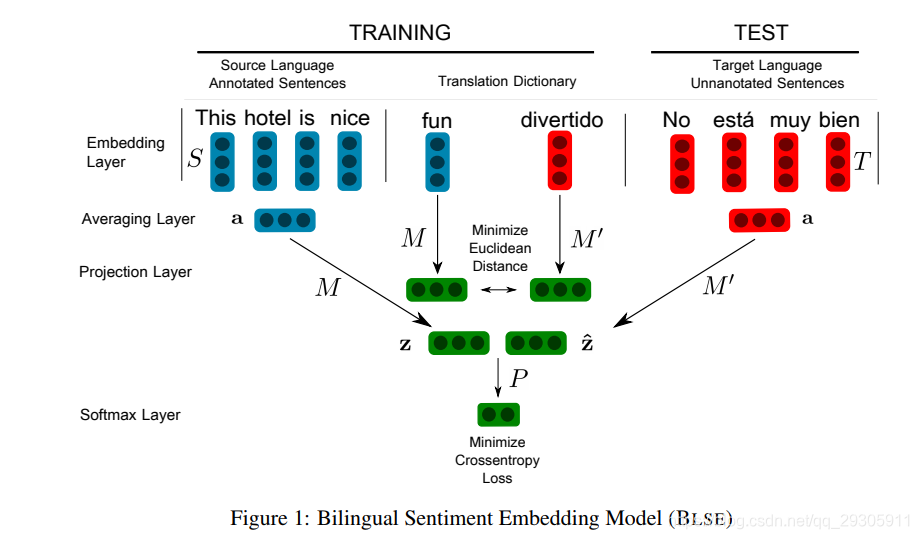
模型
Cross-lingual Projection
对于source language和target language,分别有一个向量空间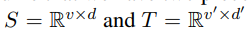
v表示词汇表的长度,d表示embedding的维度。
为了将S和T映射到双语空间
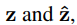
需要有线性投影矩阵M和M’
在训练过程中,对于词典L中的每一对翻译对,首先查找它们的相关向量,通过它们的相关投影矩阵投影它们,最后最小化两个投影向量的均方误差
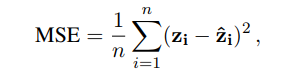
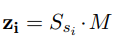
Zi是Si的embedding和矩阵M的点积。target language那边的计算也是一样。
Sentiment Classification
第二个训练目标是通过优化projected source vectors来预测source短语的情感标签,这就不可避免地改变了矩阵M,从而也改变了M’,于是就可以在没有用target language训练的情况下预测target language的情感标签。
需要source language标注好的语料:
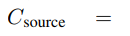
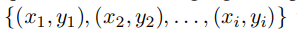
xi是sentence,yi是label
对于分类,使用two-layer feedforward averaging network,对于句子Xi,取S中的word embedding,取平均得到ai,然后将ai与M点积得到zi
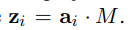
zi再通过一个softmax层得到预测标签
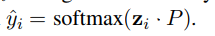
最小化交叉熵:
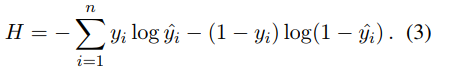
Joint Learning
将投影与分类联合起来:
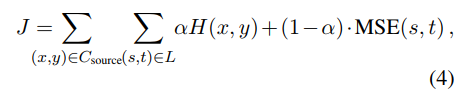
Target-language Classification
预测的时候,对于target句子,取到它们的word embedding,然后平均得到ai,再点积M’,映射到 bilingual space,通过一层softmax得到预测标签。
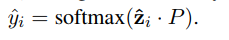

















 1144
1144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









