







目录
1:被volatile修饰,加入内存屏障,禁止特定情况下指令重排
介绍:之前时不时就会看看线程 cpu,之类。但是总是没有感觉,你没感觉错是没有感觉看的很死板。 经过很长时间积累,发现他们的有点关联,在此记录分享下。
一般写东西,都说 这个并发问题,并发安全问题。以前迷糊,现在说下下自己的理解(只是自己的理解)。
如果你想把它串下来,主要是cpu.
一:cpu
cpu:是计算机的核心,一般我们都说几核多少内存。 最开始计算机肯定是单核的
- 每个cpu的核同一时间只能运行一个线程。为了提高处理速度,就变成多核
- 当一个多核cpu运行时,就变成现在的多线程处理。
强调:多线程就是一个cpu的多个核同时执行 。
二:cpu的3级缓存
cpu的3级缓存:cpu运算数据时,先从内存中把数据读取到cpu的处理中心,但是对于cpu来说太消耗性能。所以为了提高性能,在cpu内部配有3级缓存。1级,2级缓存是单核独享,3级缓存是多核共享。先把内存中的数据读到缓存中,cpu运行缓存中的数据(如果仅仅如此我是没有感觉提高性能,无非是,先从内存中读取数据到缓存,cpu运行缓存数据,对吧,接下来继续)
- cpu操作内存和缓存:
- cpu操作内存时间远远大于操作缓存,假设操作内存用的时间是100,缓存就是1
- cpu的两大特性(空间局部性和时间局部性)
- 空间局部性:当cpu读取数据时,会把该数据在内存中连续的数据全部读取到缓存中。比如一个数组int [] a={1,2,3,4,5,6}.如果cpu想读取4这个数据,cpu就会把1,2,3,4,5,6全部读取到缓存中。如果接下来操作5,直接操作缓存。(在此你看,你就会发现把数据从内存读取到缓存中 时间大大提高)
- 时间局部性:当cpu读取数据时,把数据先读取到缓存,如果cpu判断接下来的程序(指令)还会用到该数据,那么不会立马清除该数据。(如果清除数据,那么用到时 ,还会从内存读取数据,你看这个也提高了性能(不仅仅如此,它还和指令重排优化有关,接下看))
cpu目前理解的这里接下来是。JMM内存模型
三:JMM内存模型
JMM:是一个规则,是多线程操作共享变量。围绕着原子性,有序性,可见性(这好理解也不好理解,哈哈)
- JMM的工作内存:是每个线程独有的。
- MM的主内存:是所有线程都能读取到的数据
(不管是主内存(共享内存)还是,工作内存都是定义。只是定义)
解释下:
- 原子性:程序一旦操作不可中断。多线程操作一个程序,一个线程在没有结束完其它线程不可操 作。(多线程中,一个线程还没操作完,另一个线程就也开始操作了。会发生问题)
- 有序性:写的代码按照顺序执行(但是cpu优化性能,会发生指令重排--多线程可能会出现问题)
- 可见性: 多线程之间,操作同一个变量, 当线程一修改变量后,及时通知其他线程此变量已修 改。(多线程中,多个线程同时操作一段代码,一个线程修改变量后,没有通知其它线程变量修改。导致数据最后结果出现问题)
拿图说话:
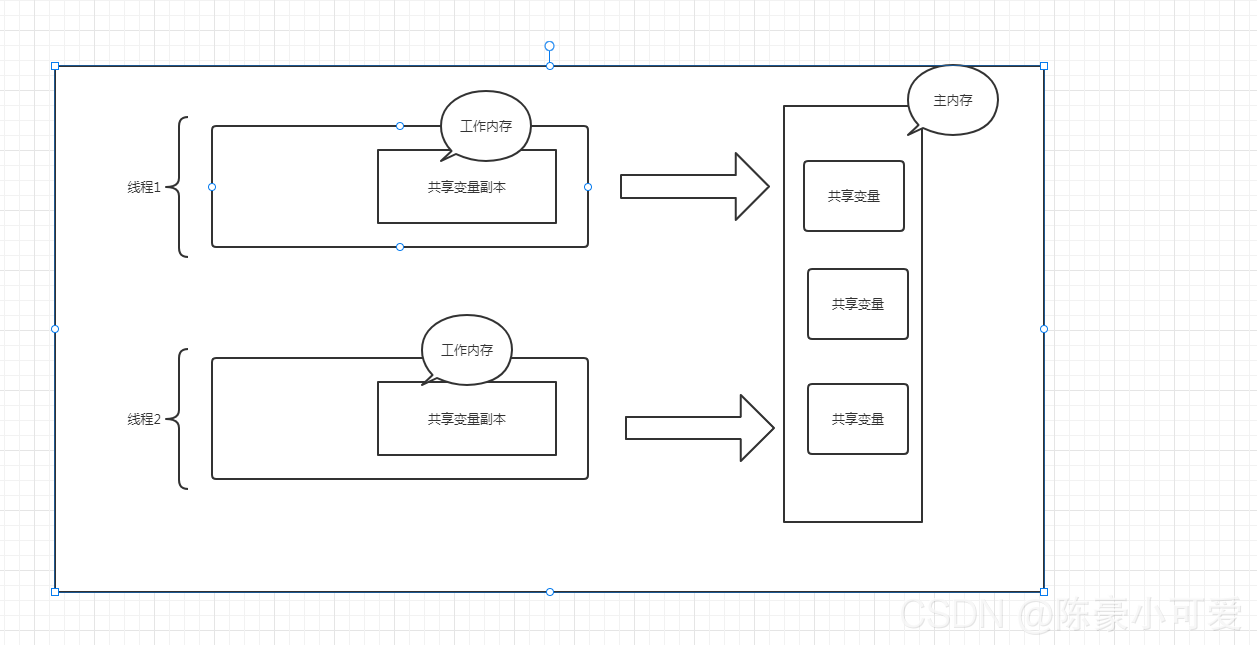
举个例子: int a=1, int b=a++
如果一个线程要执行 上段代码,先从主内存把a读取到 该内存的工作中,然后进行操作。 最 后再把工作内存的数据同步到主内存。(在多线程中问题来了)
多线程问题: 看代码
四:多线程下的,原子性,可见性,有序性问题
第一个例子:多线程可见性问题
int b = 0;
for (int i = 0; i < 100; i++) {
b++;
System.out.println(b);
}重点: 如果是单线程b是100,如果是多线程不一定是100(为什么呢)
如果两个线程同时操作,当两个线程拿到的数据假设都是9,但是第一个线程加完之后已经把数据同步到主内存中去 b变成10,但是第二个数据刚拿到9但是主内存已经变成10了。(不知道能感觉到这个点嘛)
违反了可见性:一个线程把变量修改后,没有通知其它变量。
第二个例子:多线程原子性问题
int j=0;
@Test
public void test() {
//线程2执行的代码
int i = 0;
i = 10;
//线程1执行的代码
j = i;
}两个线程同时操作,当线程1先执行代码,执行到j=i 正常j=10, 但是当i还没有赋值给j的时候,线程2先执行i-=0. 那么线程1给j赋值的值是0
违反了原子性:程序一旦运行不可中断,(一个线程没操作完,另一个线程也操作代码,导致数据错误。 这个点get到吧)
第三个例子:多线程有序性问题
public void test() {
//线程1执行的代码
int i = 0; //第一行
int b=20; //第二行
i = 10; //第三行
}解释:这个我个人感觉和cpu的缓存和时间局部性有关。之前说了 cpu操作内存时间远远大于缓存
咱们看来:第一步:首先cpu先从内存读取i=0,第二步在从内存读取b=20,第三步再内存i=10,这样操作了3次内存。
cpu的时间局部性是这样说的,当cpu读取这个变量时,如果这个变量接下来还继续操作,将会在缓存中保留,不删除。
咱们这个代码。第二行和第三行变换位置执行是不影响最后结果的。所以cpu让它指令重排,代码就变成
public void test() {
//线程1执行的代码
int i = 0; //第一行
i = 10; //第三行
int b=20; //第二行
}这样在执行:第一步先从内存中读取i=0,发现接下操作还是操作i,那么根据cpu的时间局部性,i=0在缓存中不删除,第二步,在缓存中读取i=0然后处理变成i=10,第三步,cpu从内存读取b=20
这样程序就还有两次读取内存。
这就是指令重排。
但是多线程指令重排会出现问题
1: 指令重排发生问题
private static int x = 0, y = 0;
private static int a = 0, b = 0;
Thread t1=new Thread(()->{
x=b; //指令重排序
a=1;
});
Thread t2=new Thread(()->{
y=a; //指令重排序
b=1;
});
如果同时执行两个线程t1和t2
如果线程t1先执行结束,那么x=0.
--------------------------------------------------------------------------------------------------------------------------------
如果线程二先执行并且发生指令重排就变成如下。如果t1线程x=b还没执行,t2线程指令重排,并且执行了b=1. 那么t1线程x值就是1
private static int x = 0, y = 0;
private static int a = 0, b = 0;
Thread t1=new Thread(()->{
x=b; //指令重排序
a=1;
});
Thread t2=new Thread(()->{
b=1;
y=a; //指令重排序
});至此:多线程下就可能会发生,原子性,有序性,可见性。
如何保证多线程下不不发生问题呢,来了
五:如何保证原子性,有序性,可见性
volatile: 保证可见性,和有序性
1:被volatile修饰的变量,会通知其它线程,该变量已修改。(可能会强制线程从内存中读取,并刷新缓存。这个就是常用MESI协议)
2:被volatile修饰的变量,在特定情况下禁止指令重排(如果做到禁止指令重排呢,这就是内存屏障。)
synchronized:保证原子性
1:加锁 (再续添加,没写完)
六:内存屏障
1:被volatile修饰,加入内存屏障,禁止特定情况下指令重排
内存屏障:被volatile,修饰的变量在特定情况下,禁止指令重排(这个想想咋解释哈)
第一:cpu会判定在那些情况禁止指令重(如何判定呢)
第二:在代码(指令) 加入内存屏障
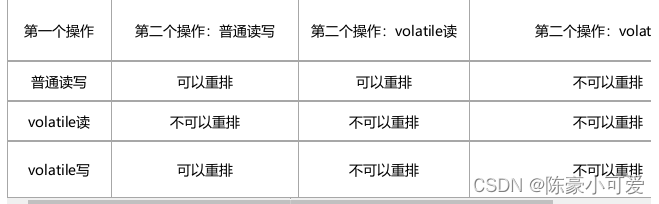
内存屏障提供了四种:LoadLoad(读读屏障),StoreStore(写写屏障),StoreLoad(写读屏障),LoadStore(读写屏障)
看图:这个是cpu在所有情况,是否要加入内存屏障
class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
int i = v1; // 第一个volatile读
int j = v2; // 第二个volatile读
a = i + j; // 普通写
v1 = i + 1; // 第一个volatile写
v2 = j * 2; // 第二个 volatile写
}
}指令加入内存屏障后就变成
解释:
1:操作一volatile读和操作二volatile读,需要加入LoadLoad(读读屏障)不可以重排
2:操作一volatile读和普通写,需要加入LoadStore(读写屏障)不可以重排
3:操作一普通写和volatile写,需要加入 StoreStore(写写屏障)不可以重排
4:操作一volatile写和volatile写,需要加入 StoreStore(写写屏障)不可以重排
class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
LoadLoad(读读屏障)
int i = v1; // 第一个volatile读
LoadLoad(读读屏障)
int j = v2; // 第二个volatile读
LoadStore(读写屏障)
a = i + j; // 普通写
StoreStore(写写屏障)
v1 = i + 1; // 第一个volatile写
StoreStore(写写屏障)
v2 = j * 2; // 第二个 volatile写
StoreLoad(写读屏障) //最后一个指令都要加这个屏障
}
}
这样volatile实现禁止指令重排。
第七 :MESI协议
这个没有了解很深入,我只说下我的理解
mesi协议是保证 cpu缓存一致性(也解决了多并发的可见性问题)。
他是如何保证缓存一致性呢?
答案就是加锁,在cpu的缓存行上加锁。
举个列子:
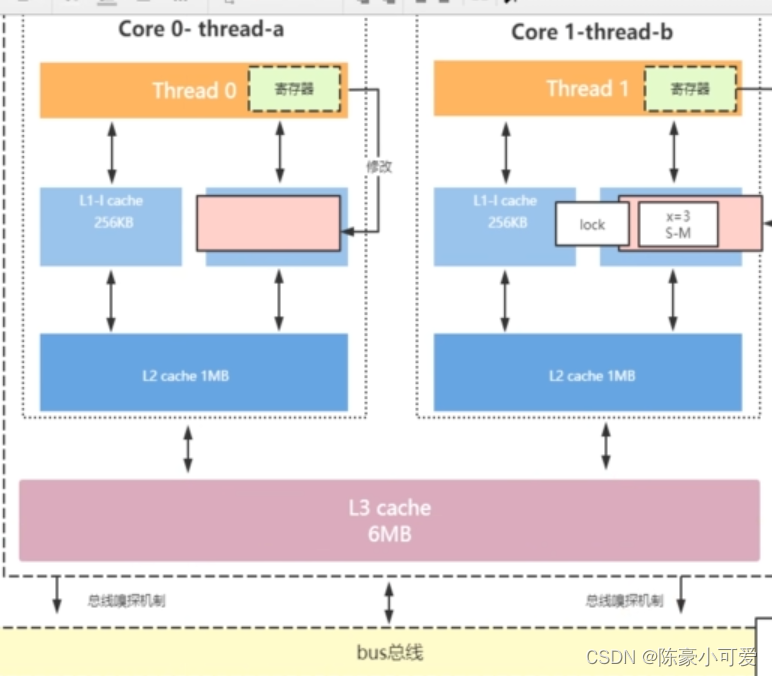
1:如果两个线程同时读取一个变量,第一个线程读取到变量,会存在缓存中(cpu的缓存,存储单元就是缓存行(64个字节)--这里我个人觉得有优化的地方稍后再说),同时给这个缓存行加锁,并通知其它线程去内存中读取。
2: 当两个线程同时读取到数据,此时缓存行并没有加锁?,这又该处理呢。升级解释下,当一个线程读取变量到缓存行时,此时还没加锁,把该数据处理完后,会把最终数据传送给3级缓存并在这里留一个标注。这个标注会告诉其他线程,这个变量是不是被加锁了。当其它线程把最终值复制给3级缓存时,判断这个缓存行是否被加锁。 如果加锁将移除自己的工作空间的变量,重新去主内存中取数据。(理解的大概这意思、每个缓存行都有4种状态。这个不解释。没深究。是以上说法是让自己更容易了解的流程)
3:这里有个问题,上面说了一个缓存行64字节,如果读取的变量超过一个缓存行。比如80个字节。按照之前解释,就可能需要在两个缓存行加锁。两个缓存行加锁不能保证原子性。 当出现这种情况,不会在缓存行加锁,是直接在消息总线加锁。(这里就有优化)
此解释是为了自己更好理解: 当以前没出现缓存时,怎么解决一致性。 是在消息总线加锁,就是当一个线程从内存读取到数据时,会在消息总线加锁,告诉其它线程不能读取。这样一来很消耗性能。
之前说过,cpu从内存读取数据消耗远远大于从缓存读取数据,为了优化出现3级缓存,以及 MESI协议。在缓存行加锁,提高性能。
根据MESI协议,当变量大于一个缓存行时,会在多个缓存行存入,为了保证缓存一致性,加锁升级,直接在消息总线加锁。 这样性能会损失
优化:在编写程序时,尽量让数据小于64字节,尽可能小。
第八:synchronized
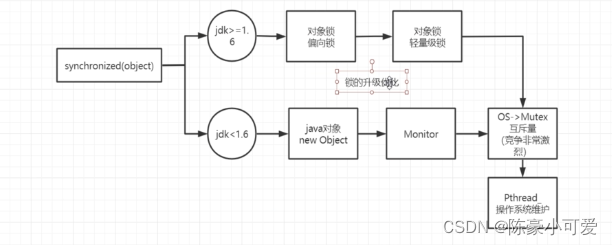
解释下字节了解的发展史,更容易理解
jdk1.6之前,synchronized只有一个重量级锁。它是赖操作系统的MutexLock(互斥锁)来实现的。所以每次操作,需要系统从用户空间切换到内核空间。很消耗性能(后来一个大佬研究出另外一个锁ReentrantLock(一个并发框架AQS),性能很高)
后来synchronized升级,就有了偏向锁,轻量级锁和重量级锁。
- 偏向锁: 偏向锁是单例的,就是这段代码只被一个线程访问时,加入偏向锁。
- 轻量级锁:被多个线程访问,但是其它线程等待时间很短(其它线程会在锁外自旋,等待一会重新尝试获取)。如果其它线程等待时间很长,会升级重量级锁
- 重量级锁:需要让系统从用户态切换到内核态
synchronized三种加锁方式
- 在方法上。
- 在静态方法上
- 在代码块上
public class SynchronizedTest implements Runnable {
static int i = 0;
/**
* synchronized 方式一 :在方法上加锁 , 锁加载当前this对象, 那个对象 new SynchronizedTest(), 锁加载那个对象上
*/
public synchronized void increase() {
System.out.println("测试:" + Thread.currentThread().getName() + ",i=" + i++);
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
increase(); //方式一
}
}
public static void main(String[] args) throws InterruptedException {
SynchronizedTest sy=new SynchronizedTest();
Thread t1= new Thread(sy);
Thread t2= new Thread(sy);
t1.setName("线程1");
t1.start();
t2.setName("线程2");
t2.start();
System.out.println(i);
}
}public class SynchronizedTest2 implements Runnable {
static int i = 0;
/**
* synchronized 方式二 :在静态方法上加锁。 锁加载当前SynchronizedTest 对象上面
*/
public static synchronized void increase() {
System.out.println("测试:" + Thread.currentThread().getName() + ",i=" + i++);
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
increase();
}
}
public static void main(String[] args) throws InterruptedException {
SynchronizedTest2 sy=new SynchronizedTest2();
Thread t1= new Thread(sy);
Thread t2= new Thread(sy);
t1.setName("线程1");
t1.start();
// t1.join();
t2.setName("线程2");
t2.start();
// t2.join();
System.out.println(i);
}
}public class SynchronizedTest3 implements Runnable {
static int i = 0;
static SynchronizedTest instance=new SynchronizedTest();
/**
* 修饰实例方法
*/
public void increase() {
System.out.println("测试:" + Thread.currentThread().getName() + ",i=" + i++);
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
/**
* synchronized 方式三 :在方法内部的同步块上加锁 。作用在 当前方法上快
*/
synchronized(instance){
increase();
}
}
}
public static void main(String[] args) throws InterruptedException {
SynchronizedTest3 sy=new SynchronizedTest3();
Thread t1= new Thread(sy);
Thread t2= new Thread(sy);
t1.setName("线程1");
t1.start();
// t1.join();
t2.setName("线程2");
t2.start();
// t2.join();
System.out.println(i);
}
}第 九:ReentrantLock
第 十:JVM逃逸分析
什么是逃逸分析呢,我个人理解,方法体内创建的对象,只被其内部所引用,不被其它方法引用。 当这个方法执行结束,垃圾回收器,会对其进行回收。 如果该方法内部的对象被其他方法引用,垃圾回收器是不回收这个方法。这被称为逃逸
开启逃逸分析可以对程序进行优化:
1: 锁消除:
线程同步锁是消耗性能的,当编译器确定当前对象只对当前线程起作用,那么就会移除该对象的同步锁。
列:Stringbuffer和Vector都是被Synchronized修饰的线程安全的,但是大部分在当前当前线程中使用,那么编译器就会移除这些锁 操作
锁消除的 JVM 参数如下:
- 开启锁消除:-XX:+EliminateLocks
- 关闭锁消除:-XX:-EliminateLocks
锁消除在 JDK8 中都是默认开启的,并且锁消除都要建立在逃逸分析的基础上。
列代码:Stringbuffer是线程安全 append被加锁,Stringbuffer作用于在局部变量,没用被引用,发生逃逸。那么编辑器,会把锁消除。
public void test3(){
StringBuffer sb= new StringBuffer();
sb.append("df");
} @Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}2:标量替换:
先明白什么是标量和聚合量,聚合量就是对象,标量就是对象里面的基础类型。
聚合量可以分解成标量,将一个对象的成员变量分解成分散的变量成为标量替换(什么叫做分散的变量,就是他可以在栈和寄存器创建)
列入:如果一个对象没有发生逃逸,这个对象不会被创建,会在线程栈或者寄存器中创建使用的标量,节省内存空间,提升程序性能
标量替换的 JVM 参数如下:
- 开启标量替换:-XX:+EliminateAllocations
- 关闭标量替换:-XX:-EliminateAllocations
- 显示标量替换详情:-XX:+PrintEliminateAllocations
标量替换同样在 JDK8 中都是默认开启的,并且都要建立在逃逸分析的基础上。
3:锁的粗化:
简单理解把锁合并,编写并发一般情况会把锁加在代码块中,锁的范围也只是这个方法,如果在一个方法中锁多次代码块,并且这些代码块没有相互影响共享数据,那么会进行锁的粗化,把相互不影响的代码块用一个锁进行加锁。 代码如下
public int a = 1;
public int b = 1;
public void test1() {
synchronized (T) {
for (int i = 0; i < 100; i++) {
a++;
}
}
synchronized (T) {
for (int j = 0; j < 100; j++) {
b++;
}
}
}---发生锁的粗化
public void test2() {
synchronized (T) {
for (int i = 0; i < 100; i++) {
a++;
}
for (int j = 0; j < 100; j++) {
b++;
}
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









