






本文一作是来自密歇根大学的Sun Jiachen。本文提出将自监督学习(SSL)加入对抗训练的过程,可以有效提高模型的鲁棒性。本文的分析还发现DGCNN和Jigsaw Proxy任务可以提高神经网络的鲁棒性, 因为学习到了局部特征,从而限制了点级的扰动到模型最终输出的传播。
1. 介绍
目前提高点云识别鲁棒性的障碍主要有两个,
(1)多种多样的模型架构。作者将其分为基于MLP的PointNet,基于卷积神经网络的,以及基于注意力机制的。目前缺少关于这些模型的鲁棒性的in-depth的研究。
(2)对自适应攻击很脆弱。现在一些防御方法只是混淆攻击者,让其接触不到真实的梯度(梯度混淆?)。如果攻击者能够完全知道防御措施,并且估计梯度,就能绕过这种防御。这种攻击被称为自适应攻击。对抗训练能够防御自适应攻击,进一步提高对抗训练的防御效果是本文要解决的问题。
自监督学习之前已经被用于2D图像模型的对抗训练【1】。优点是不需要额外的数据和标签就可以提高模型的鲁棒性。作者提出了两种integrate自监督学习和对抗训练的方式。(1) 将自监督学习用于预训练,(2) 对抗联合训练,联合训练SSL任务和识别任务。
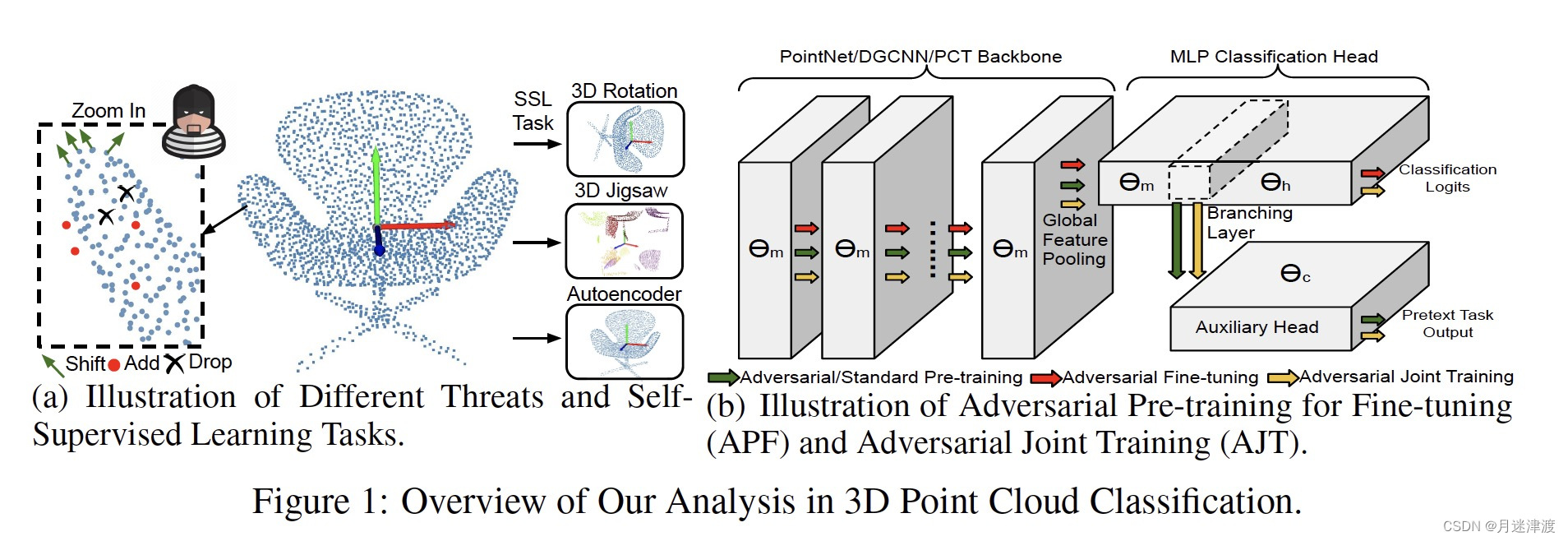
本文的贡献主要有:
(1) 本文发现在自监督任务上预训练能够提高对抗鲁棒性。不同于2D场景,文章发现只有预训练的方式能够提高鲁棒性,联合训练的方式不能提高鲁棒性。因为SSL和识别任务的数据分布存在gap,会distract each other.
(2) DGCNN 更robust。3D jigsaw SSL task 也能提高鲁棒性。他们都强化了学习局部语义
(3)提出两种简单但有效的ensemble方法通过一个substantial margin提高对抗鲁棒性。
2 分析方法
2.1 3D 点云的识别模型和威胁模型
Pointnet: 从每一个点聚合学习到的特征。形成一个全局的embeding。在global pooling之前,点级的特征是独立于其他点的。效率高。
DGCNN:基于kNN构建图。使用基于edge的连续卷积学习局部特征。局部特征和全局特征的结合使得DGCNN达到更高的准确率。
PCT使用了transformer的架构,核心是全注意力机制,构建了一个更灵活的框架。
目前的威胁主要分为三种:point shifting,point dropping and point adding。根据PGD攻击,三种威胁可以描述为:
point shifting:
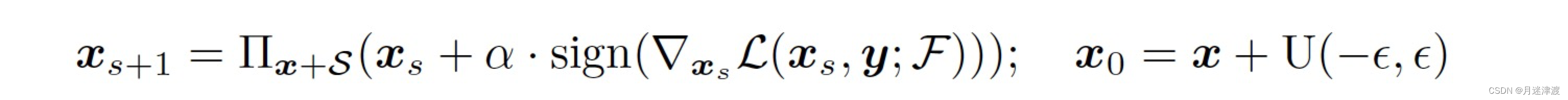
Point droping:
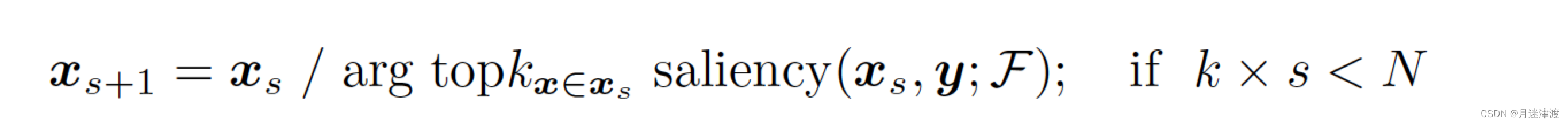
Point adding
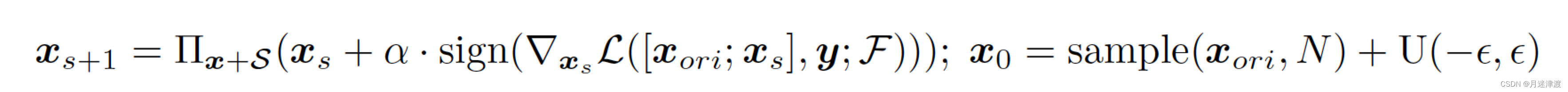
2.2 使用自监督的对抗训练
作者使用了三种不同的自监督学习方法,3D Rotation,3D Jigsaw和Autoencoder。
其中3DJigsaw是把点云均匀分割成K^3个cubes。然后打乱他们的位置,让模型能准确预测出cubes原来所在的位置。
对抗预训练:
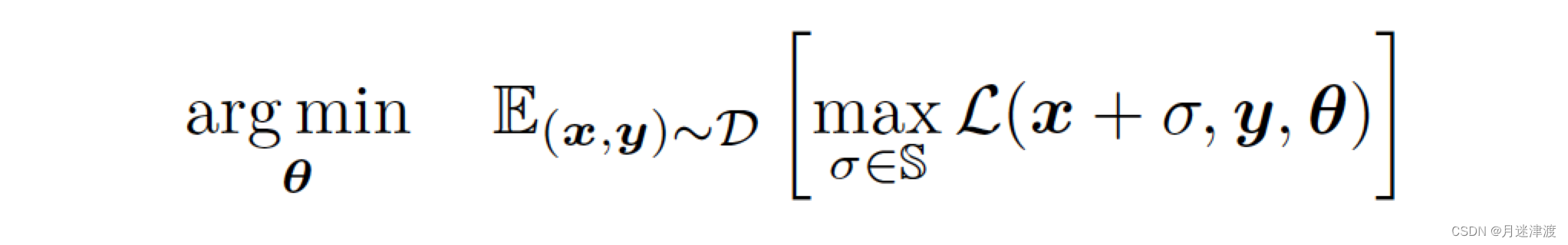
对抗训练可以理解成求解一个最小-最大问题。内层循环是寻找一个对抗样本使得模型的loss最大,外层循环是将对抗样本加入训练,更新模型参数,使模型能够准确的分类对抗样本。
对抗联合训练:
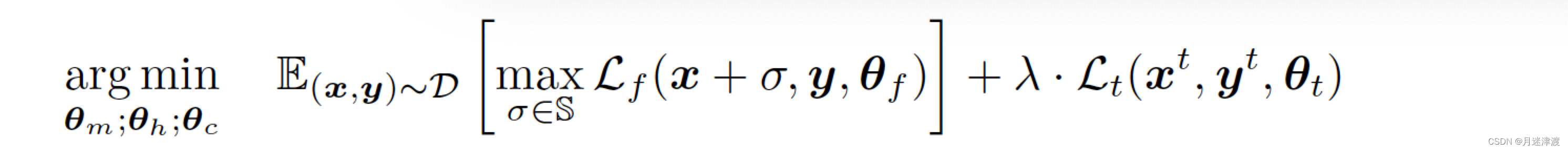
模型存在两个输出,一个是自监督任务,后面一个是分类任务,用来平衡两者。
3. 实验结果
3.1 实验设置
作者评估了4个数据集,包括ModelNet40, ModelNet10,ScanObjectNN 和shapeNetPart。
分别使用7-step 和200-step的PGD攻击在对抗训练和测试阶段。

随机采样了1000个点并归一化道到边长为[-1, 1]的立方体中,
3.2 分类任务
作者首先介绍了点云分类任务的分析,然后介绍了关于APF和AJT的详细研究,进一步评估了模型对unseen attack的鲁棒性。作者发现预训练模型 通过不同的SSL任务会保留不同的脆弱性。因此采用简单的集成方法,boost鲁棒性。最后,评估了方法对不同的威胁,表明了其generality。
3.2.1 自监督训练帮助对抗微调
作者发现AP F整体上提高了模型的鲁棒性,DGCNN和jiasaw方法鲁棒性更高,有更高的clean accuracy。
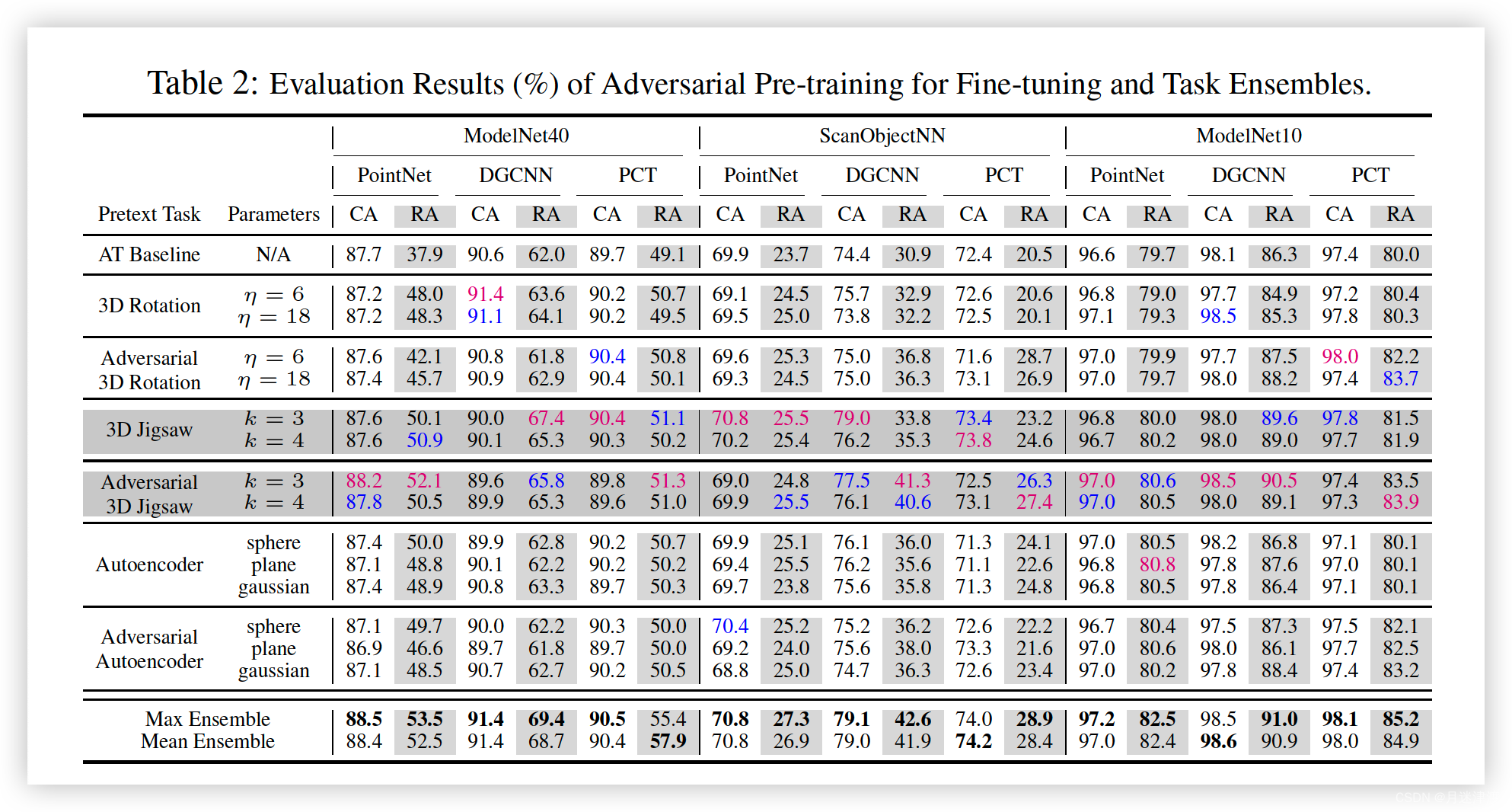
在2D 图像领域,一般认为局部特征和全局特征分别对应了纹理和形状信息。最近的研究表明了合适的全局特征能够提高图像分类的鲁棒性。然而,我们发现在点云识别任务,Pointnet使用了全局特征将会很容易被污染点影响。因为点云的系数,局部特征实际上表明了物理表面的平滑程度。因为,学习鲁棒的局部特征是非常重要的,因为限制了对抗点到输出的传播。
作者认为DGCNN的鲁棒性源于分等级的EdgeConv可以有效的聚合局部特征,能够矫正对抗的赢影响。对于Transformer,每一个点都有可能影响其他点的特征,因此增加了模型的脆弱性。同理,Jigsaw也是提高了局部特征的学习,因为提高了鲁棒性。
作者还发现对抗联合训练并不总是提高鲁棒性。甚至降低了transformer模型的鲁邦性。作者认为这是因为点云数据的自然特性。尽管自监督学习可以帮助模型学习更强的先验知识和上下文信息,他们仍然是分开的学习任务。旋转和重新组合图片能够保留局部特征,因为图片的RGB值没有变化。但是点云输入的是xyz坐标,旋转和重新组合能够显著影响他们的坐标数值。
作者还评估了unseen attack的影响,以及transfer attack的影响,还评估了point adding 和point droping攻击,以及point cloud segmentation的鲁棒性。实验做的很全面。
总结:虽然作者方法很简单,提高的程度也有限,大概也就10个点,贵在实验支撑比较充分,仅在正文就有六个表格五张图,这还是在10页的范围内,值得我们学习。
【1】 Tianlong Chen, Sijia Liu, Shiyu Chang, Yu Cheng, Lisa Amini, and Zhangyang Wang. Adversarial Robustness: From self-supervised pre-training to fine-tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 699–708, 2020.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









