






我们知道文档 document 是 ES 的最小数据单元,ES 也提供了丰富的操作索引文档的 API,这里使用 Kibana 搜索,查看和与存储在 ES 索引中的数据进行交互,关于如何安装和配置 Kibana ,打算后面再专门梳理。
1、创建测试索引
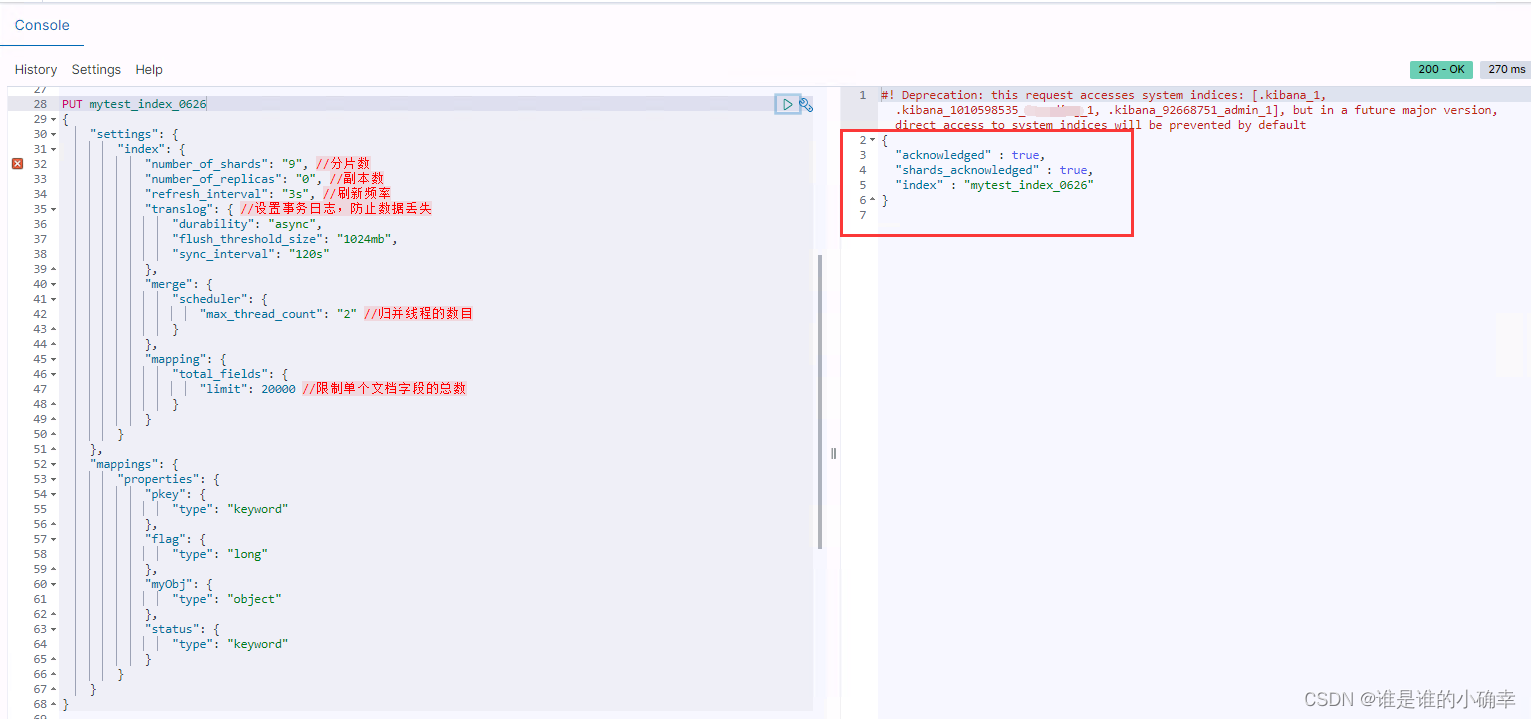
下面说明 ES 索引文档的 CRUD 操作。开始之前,先创建一个测试索引,并对索引 index 进行一些必要的性能优化设置,同时定义和设置文档字段的属性:
PUT mytest_index_0626
{
"settings": {
"index": {
"number_of_shards": "9", //分片数
"number_of_replicas": "0", //副本数
"refresh_interval": "3s", //刷新频率
"translog": { //设置事务日志,防止数据丢失
"durability": "async",
"flush_threshold_size": "1024mb",
"sync_interval": "120s"
},
"merge": {
"scheduler": {
"max_thread_count": "2" //归并线程的数目
}
},
"mapping": {
"total_fields": {
"limit": 20000 //限制单个文档字段的总数
}
}
}
},
"mappings": {
"properties": {
"pkey": {
"type": "keyword"
},
"flag": {
"type": "long"
},
"myObj": {
"type": "object"
},
"status": {
"type": "keyword"
}
}
}
}在设置 settings.index.xxxx 考虑了 ES 的性能调优,感兴趣可以参考:
- translog:Elasticsearch 之 Translog - 简书
- merge:es的索引合并_ITduan621的博客-优快云博客_es合并索引
- mapping.total_fields.limit:es“limit of total fields” 和“field expansion mathes too many fields”问题解决_jff_shihaoren的博客-优快云博客
在 Kibana 执行创建索引命令,效果如下:
2、添加文档
>> POST 索引名/_doc

请注意,如果没有指定文档id,ES 会自动生成文档id。也可以指定文档id,如下:
POST mytest_index_0626/_doc/1
{
"pkey": "15556905954_10011",
"flag": "1",
"myObj": {
"user_id":"15556905954",
"create_time":"20220626110020",
"sign_no":"10011",
"remarks":"testing creat a document."
},
"status": "N"
}
如果添加文档时,使用了已存在的文档id,则会把之前的文档更新覆盖掉:(_version 用于记录当前最新的版本,_seq_no=2说明该文档已经被更新过2次了!)

3、删除文档
方式一:使用 DELETE 方式删除

文档id为1的已被标记删除,ES内部也刷新了被删除文档的_version和_seq_no,查询语句是不会查询到这条文档数据了!
方式二:使用 POST 方式 + _delete_by_query
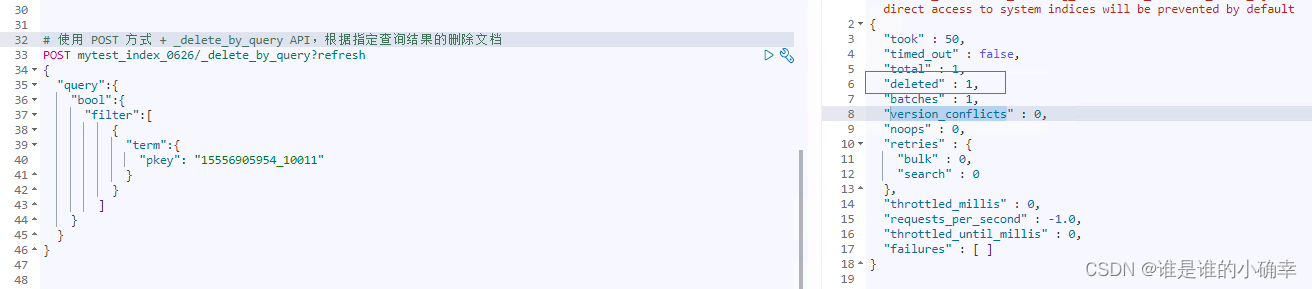
先根据查询 API 匹配到对应的文档,然后调用 _delete_by_query 进行删除,这种方式是最常用的,只需要匹配到要删除的目标文档,就可以删除或批量删除。
请注意,如果要删除的文档数据量很大,Kibana 可能会返回并提示"504 GetWay Time-out":
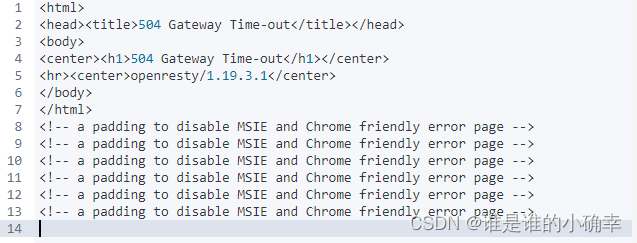
不要慌,我们可以通过下面的 API 进行追踪:
GET _tasks?detailed=true&actions=*/delete/byquery
// 或者这个也可以查询
GET _tasks?detailed=true&actions=*byquery它会把集群中所有节点在进行删除动作的任务给罗列出来,我们找到刚刚删除的任务即可,如下:
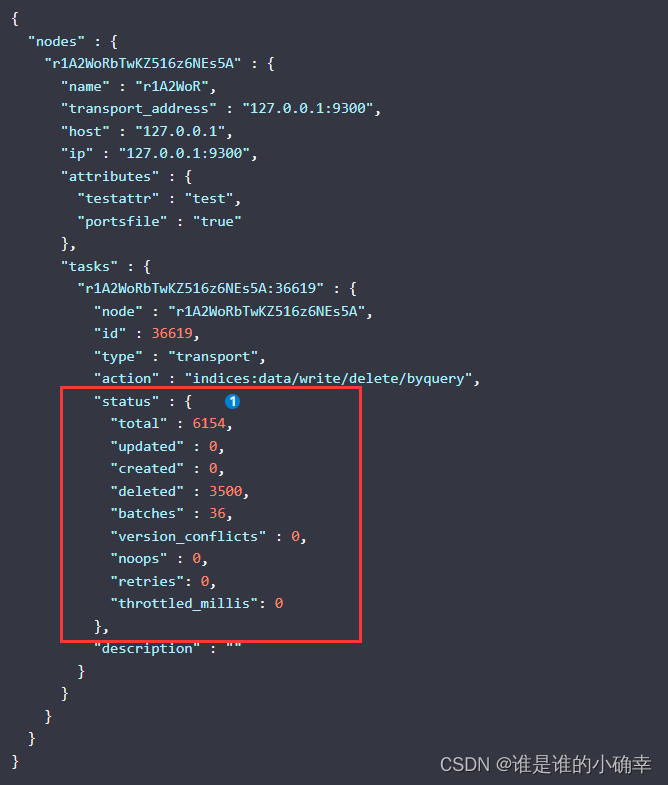
如果我想中途取消删除任务的执行,找到这个删除任务ID,使用以下命令即可:
POST _tasks/r1A2WoRbTwKZ516z6NEs5A:36619/_cancel4、更新文档
方式一:使用 _update
假如我们要更新文档的部分字段,如果直接使用 PUT 索引名/文档id 更新,则会导致文档的全量更新,这是极其危险和不可取的操作!可以使用如下方式进行文档的增量更新:
POST mytest_index_0626/_doc/1/_update
{
"doc":{
"status" :"A"
}
}通过查找官网文档中的 _update API,目前看流行的写法是采用 script 脚本方式,比如,在某个文档里新增一个字段:
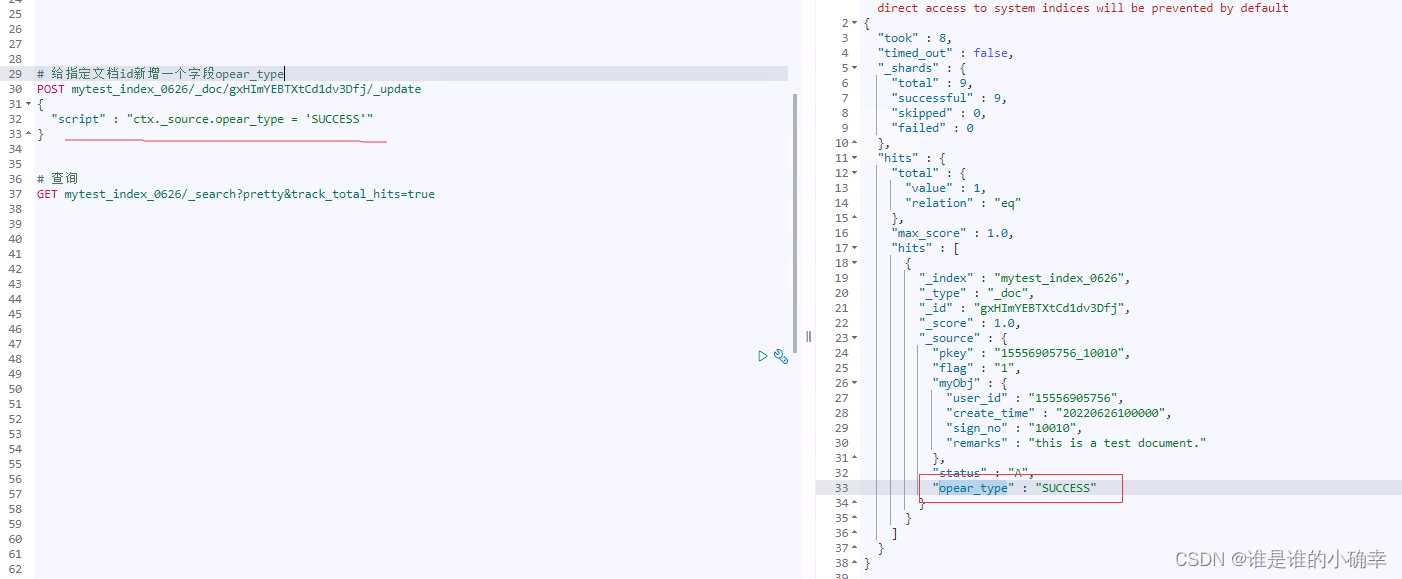
又比如,在某个文档里删除一个字段:
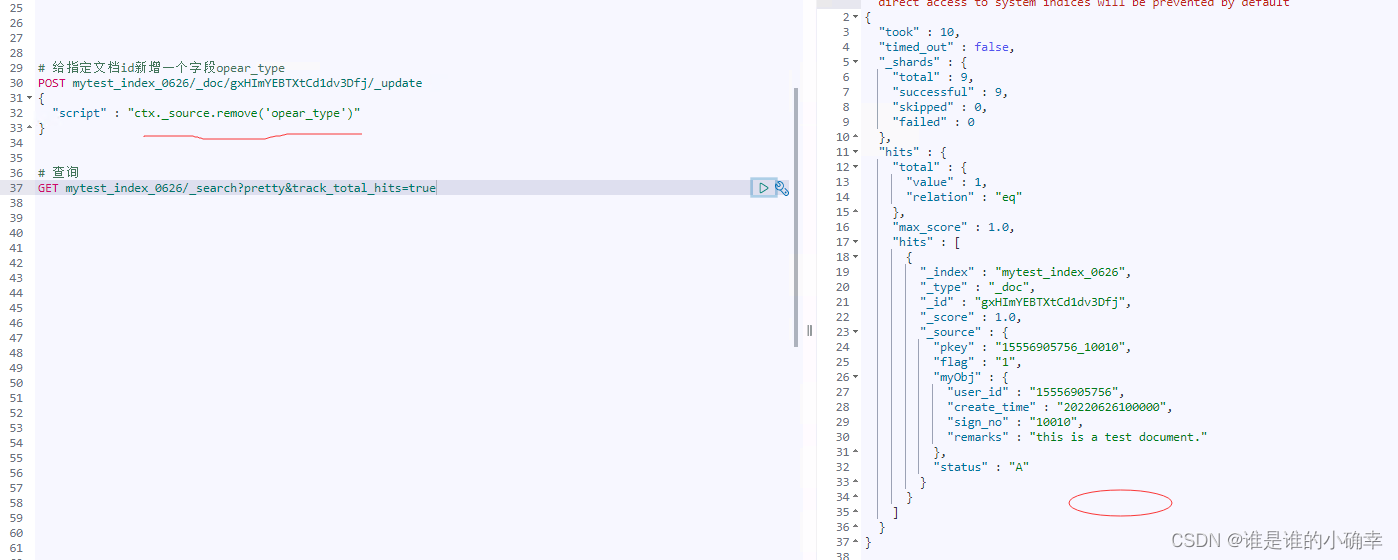
当然,还有使用 painless 语言的 script 用法,这里不再尝试了,有需要可以参考官网文档的API示例和说明。
方式二:使用 _update_by_query
其实,平时最常用的更新文档方式则是"按查询更新",它支持批量更新操作,而官网文档也有对 _update_by_query 的用法说明。
现在为当前索引再添加2条文档,该索引一共有3条数据了。下面开始演示不同更新需求的示例
>> 更新所有文档的 flag 字段为0
POST mytest_index_0626/_update_by_query?conflicts=proceed
{
"script": {
"source": "ctx._source['flag']=0",
"lang": "painless"
},
"query": {
"match_all": {}
}
}
// 返回:
{
"took" : 46,
"timed_out" : false,
"total" : 3,
"updated" : 3,
"deleted" : 0,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
查询结果显示:
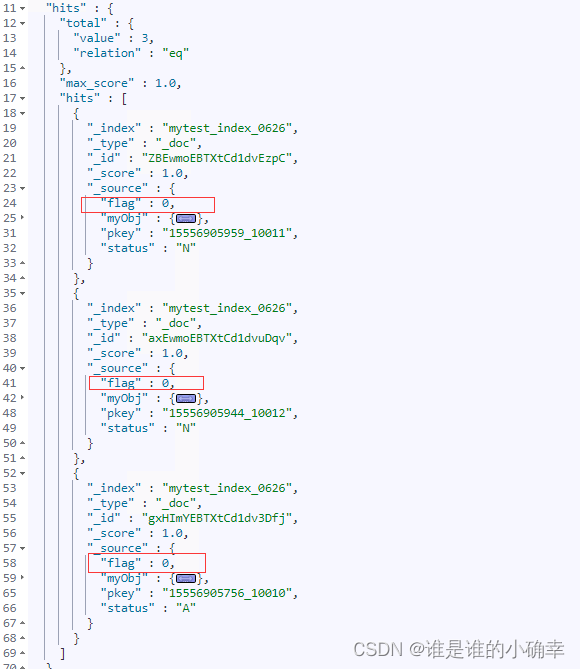
>> 更新所有文档的 flag 字段为1,且 status 字段为 U
POST mytest_index_0626/_update_by_query?conflicts=proceed
{
"script": {
"source": """
ctx._source['flag']=1;
ctx._source['status']='U';
""",
"lang": "painless"
},
"query": {
"match_all": {}
}
}
查询结果显示:

>> 更新所有文档的 flag 字段为0,且更新myObj里的remarks为空字符串,且为myObj里新增一个update_time字段并赋值为当前时间
POST mytest_index_0626/_update_by_query?conflicts=proceed
{
"script": {
"source": """
ctx._source['flag']=0;
ctx._source['myObj'].remarks='';
ctx._source['myObj'].update_time='20220626113059';
""",
"lang": "painless"
},
"query": {
"match_all": {}
}
}查询结果显示:

最后,总结下 _update_by_query:
- 如果文档存在该字段,则会使用新值覆盖旧值,不存在该字段的话,则会添加该字段为当前索引的类型字段;
- 如果被更新的文档数据量较大时,也会出现 "504 GetWay Time-out" 问题,可以使用以下命令跟踪更新进度:GET _tasks?detailed=true&actions=*byquery
- 请求命令的后缀参数 conflicts=proceed 的含义是,当更新遇到冲突时跳过,一般可以在返回结果的"version_conflicts"看到发生版本冲突的数量;
- 有时候,"version_conflicts"可能不为0,也就是说更新操作过程中遇到了版本冲突,这是由于当前索引的文档版本号被其他正在运行的命令或程序改变了,与执行 _update_by_query 命令时读取的索引快照不一致。我遇到这种情况时,会在整体更新完毕后,再执行一次该命令,保证版本匹配,从而能更新文档并增加版本号;
- _update_by_query 是按查询批量更新的,因此改变查询条件会得到不一样的更新结果,还有要注意_update_by_query 不支持分页操作("from": 0,"size": 1000),如果需要用到分页更新操作,可以在后缀参数使用 scroll_size=1000;
5、查询文档
我们知道 ES 是一个强大的搜索和分析引擎,自然在文档检索上会提供丰富多样的 API。比如,根据文档id查询:
// 根据文档id查询
GET mytest_index_0626/_doc/ZBEwmoEBTXtCd1dvEzpC?pretty
// 根据文档id批量查询
GET mytest_index_0626/_doc/_mget?pretty
{
"ids":["ZBEwmoEBTXtCd1dvEzpC","axEwmoEBTXtCd1dvuDqv","gxHImYEBTXtCd1dv3Dfj"]
}
比如,查询所有,或按文档的字段进行查询(GET 或 POST 方式都可以):
# 查询所有
GET mytest_index_0626/_search?pretty&track_total_hits=true
POST mytest_index_0626/_search?pretty&track_total_hits=true
# 按字段查询
GET mytest_index_0626/_search?pretty&q=pkey:15556905959_10011
POST mytest_index_0626/_search?pretty&q=status:U以上这些都只是最最最最基础的查询,如果从 ES 文档检索的整体角度来看,大致可以分为两种查询类型:结构化检索和全文检索。那么,结构化检索和全文检索各有什么特点呢?
结构化检索:
- 针对的字段类型有:数字,日期,时间,及精确的文本等;
- 结构化检索不去关心文件的相关度或评分,而是会对文档进行包含或排除的处理,也就是说要么存在要么不存在!
全文检索:
- 针对的字段类型有:全文本字段,比如:email地址,产品名称等;
- 全文检索会使用每个字段的分析器进行字符串查询。
为了看清楚更详细的分类,我画了一张脑图:
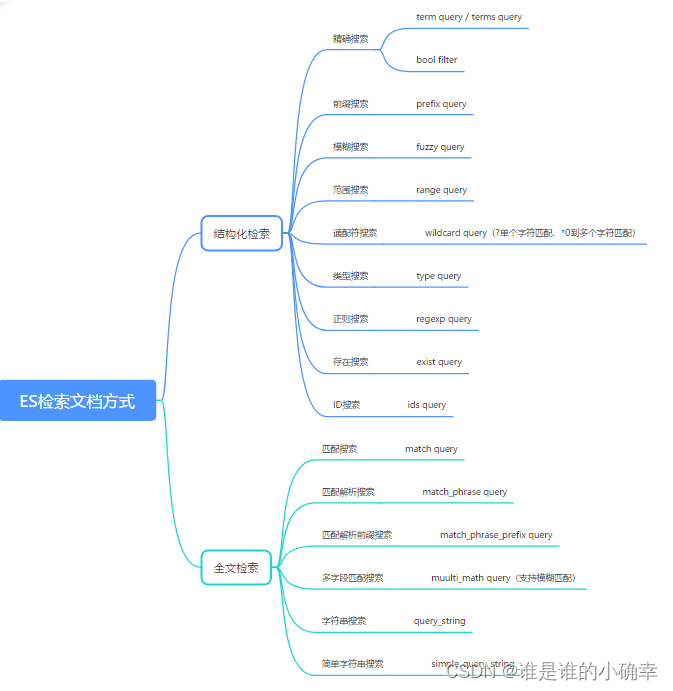
限于篇幅,这些查询方式将在下篇进行详细介绍和使用演示。

















 2300
2300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









