









 本文介绍了一个使用Python实现的BOSS直聘职位信息爬虫,通过解析搜索页面和详细页面,抓取并分析了732条职位信息,包括公司名称、职位标题、薪资、经验要求等,并将数据存储到MySQL数据库中。
本文介绍了一个使用Python实现的BOSS直聘职位信息爬虫,通过解析搜索页面和详细页面,抓取并分析了732条职位信息,包括公司名称、职位标题、薪资、经验要求等,并将数据存储到MySQL数据库中。
BOSS直聘职位信息爬取分析
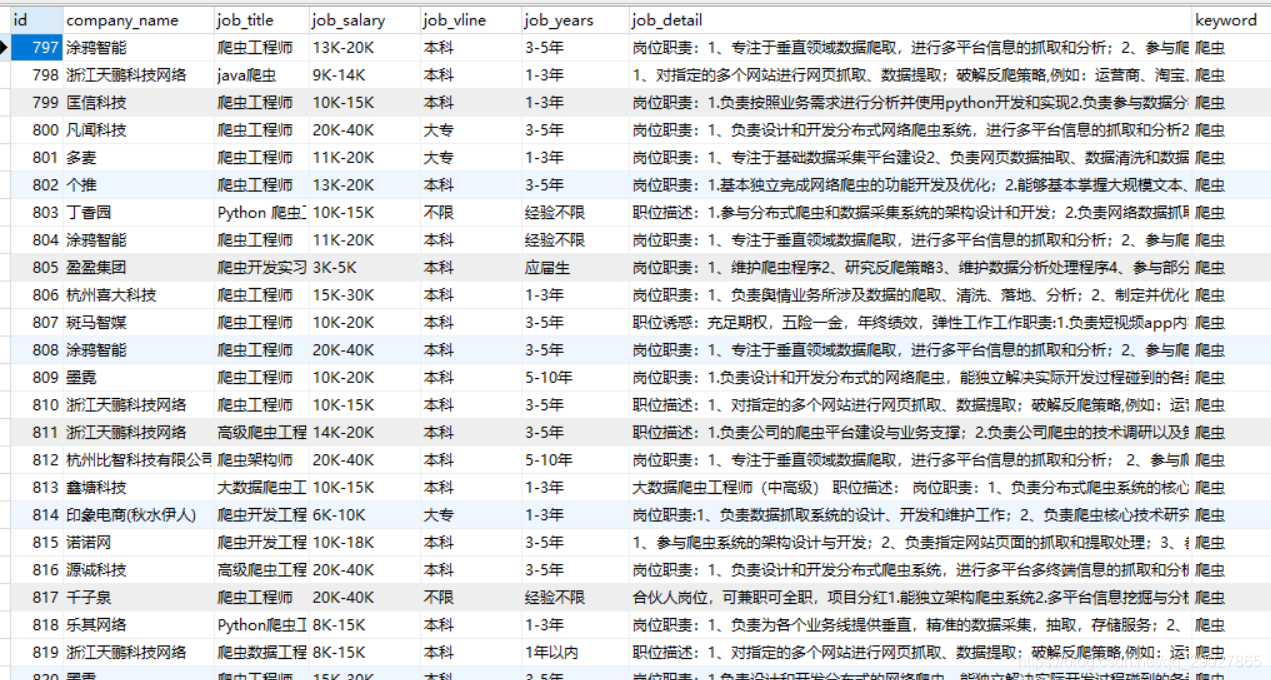
先上结果,本次抓取了732条职位的信息入库:

代码实现:
import requests
import json
from lxml import etree
from requests.exceptions import RequestException
from pymysql import *
class BossSpider():
def get_html(self,url):
try:
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Mobile Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# 更改编码方式,否则会出现乱码的情况
response.encoding = "utf-8"
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_search_html(self,resp):
base_url = 'https://www.zhipin.com'
resp = json.loads(resp)
resp_html = resp['html']
if resp_html:
resp_html = etree.HTML(resp_html)
detail_url_href = resp_html.xpath('//li[@class="item"]/a/@href')
detail_url_ka = resp_html.xpath('//li[@class="item"]/a/@ka')
detail_url_datalid = resp_html.xpath(r'//li[@class="item"]/a/@data-lid')
detail_url_href = [base_url+i for i in detail_url_href]
detail_url_params = []
for ka,lid in zip(detail_url_ka,detail_url_datalid):
url_param = {}
url_param['ka'] = ka
url_param['lid'] = lid
detail_url_params.append(url_param)
detail_url = [self.get_full_url(href,params) for href,params in zip(detail_url_href,detail_url_params)]
return detail_url
else:
return None
def parse_detail_html(self, resp,job_json):
resp_html = etree.HTML(resp)
job_detail = resp_html.xpath('//div[@class="job-detail"]/div[@class="detail-content"]/div[1]/div//text()')
job_detail = [i.replace('\n','').replace(' ','') for i in job_detail]
job_detail = ''.join(job_detail)
# import ipdb
# ipdb.set_trace()
company_name = resp_html.xpath('//div[@class="info-primary"]/div[@class="flex-box"]/div[@class="name"]/text()')[0]
job_title = resp_html.xpath('//div[@id="main"]/div[@class="job-banner"]/h1[@class="name"]/text()')[0]
job_salary = resp_html.xpath('//div[@id="main"]/div[@class="job-banner"]//span[@class="salary"]//text()')[0]
job_vline = resp_html.xpath('//div[@id="main"]/div[@class="job-banner"]/p/text()')[2]
job_years = resp_html.xpath('//div[@id="main"]/div[@class="job-banner"]/p/text()')[1]
job_json['job_detail'] = job_detail
job_json['company_name'] = company_name
job_json['job_title'] = job_title
job_json['job_salary'] = job_salary
job_json['job_vline'] = job_vline
job_json['job_years'] = job_years
self.connect_mysql(job_json)
def get_full_url(self,url, uri: dict) -> str:
return url + '?' + '&'.join([str(key) + '=' + str(value) for key, value in uri.items()])
def connect_mysql(self,job_json):
try:
job_list = [job_json['company_name'],job_json['job_title'],
job_json['job_salary'],job_json['job_vline'],
job_json['job_years'],job_json['job_detail'],job_json['keyword']]
conn = connect(host = 'localhost',port = 3306,
user = 'root',passwd = '1996101',
db = 'spider',charset='utf8')
cursor = conn.cursor()
sql = 'insert into boss_job(company_name,job_title,job_salary,job_vline,job_years,job_detail,keyword) values(%s,%s,%s,%s,%s,%s,%s)'
cursor.execute(sql,job_list)
conn.commit()
cursor.close()
conn.close()
print('一条信息录入....')
except Exception as e:
print(e)
def spider(self,url,job_json):
resp_search = self.get_html(url)
detail_urls = self.parse_search_html(resp_search)
if detail_urls:
for detail_url in detail_urls:
resp_detail = self.get_html(detail_url)
if type(resp_detail) is str:
self.parse_detail_html(resp_detail,job_json)
if __name__ == '__main__':
keywords = ['数据']
MAX_PAGE = 20
for keyword in keywords:
for page_num in range(MAX_PAGE):
url = f'https://www.zhipin.com/mobile/jobs.json?page={page_num+1}&city=101210100&query={keyword}'
job_json = {'keyword':keyword}
boss_spider = BossSpider()
boss_spider.spider(url,job_json)


















 2583
2583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











