







 本文详细介绍了进程内存管理的五个关键区域:代码段、数据段、BSS段、堆和栈的功能及用途。解释了各区域如何存储不同类型的程序数据,并讨论了Linux下进程虚拟内存空间的管理方式。
本文详细介绍了进程内存管理的五个关键区域:代码段、数据段、BSS段、堆和栈的功能及用途。解释了各区域如何存储不同类型的程序数据,并讨论了Linux下进程虚拟内存空间的管理方式。
进程与内存
所有进程都必须占用一定数量的内存,对任何一个普通进程,会对应内存空间中所包含的5种不同的数据区。分别是代码段、数据段、BSS段、堆和栈。
代码段
代码段是用来存放可执行文件的操作指令,也就是说它是可执行程序在内存中的镜像。代码段需要防止在运行时被非法修改,所以只准许读取操作,而不允许写入(修改)操作——它是不可写的。
数据段
数据段用来存放可执行文件中已初始化全局变量,换句话说就是存放程序静态分配的变量和全局变量。
BSS段
BSS段包含了程序中未初始化的全局变量,在内存中 bss段全部置零。
堆
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。
一般由程序员分配释放(在c中,调用malloc申请堆内存,使用free释放内存;在Java中使用new申请堆内存,使用delete释放), 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表,与数据结构中的堆是两回事。堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。
栈
栈是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的后进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈,栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。
内存区域分布
数据段、BSS和堆通常是被连续存储的——内存位置上是连续的,而代码段和栈往往会被独立存放。
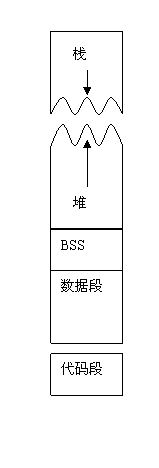
进程内存空间
Linux操作系统采用虚拟内存管理技术,使得每个进程都有各自互不干涉的进程地址空间。该空间是块大小为4G的线性虚拟空间,用户所看到和接触到的都是该虚拟地址,无法看到实际的物理内存地址。利用这种虚拟地址不但能起到保护操作系统的效果(用户不能直接访问物理内存),而且更重要的是,用户程序可使用比实际物理内存更大的地址空间。
进程内存管理
进程内存管理的对象是进程线性地址空间上的内存镜像,这些内存镜像其实就是进程使用的虚拟内存区域(memory region)。进程虚拟空间是个32或64位的“平坦”(独立的连续区间)地址空间(空间的具体大小取决于体系结构)。要统一管理这么大的平坦空间可绝非易事,为了方便管理,虚拟空间被划分为许多大小可变的(但必须是4096的倍数)内存区域,这些区域在进程线性地址中像停车位一样有序排列。这些区域的划分原则是“将访问属性一致的地址空间存放在一起”,所谓访问属性在这里无非指的是“可读、可写、可执行等”。
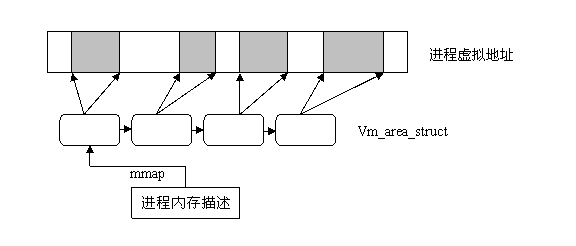
vm_area_struct是描述进程地址空间的基本管理单元,对于一个进程来说往往需要多个内存区域来描述它的虚拟空间。
vm_area_struct结构是以链表形式链接,不过为了方便查找,内核又以红黑树(以前的内核使用平衡树)的形式组织内存区域,以便降低搜索耗时。并存的两种组织形式,并非冗余:链表用于需要遍历全部节点的时候用,而红黑树适用于在地址空间中定位特定内存区域的时候。内核为了内存区域上的各种不同操作都能获得高性能,所以同时使用了这两种数据结构。
参考链接:https://blog.youkuaiyun.com/heybeaman/article/details/80348582

















 3313
3313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









