









面试时面试官最常问的几个问题:
1. HashMap是线程安全的吗?
答:不是。
2. 既然HashMap不是线程安全的,那有什么替代方案?
(1)用HashTable,它是线程安全的,但是被弃用了(性能问题被弃用了)。
(2)用HashMap,但是所有调用它方法的地方,都做加锁处理操作。
(3)用ConcurrentHashMap,一了百了。
3. 为什么HashTable被弃用了?
因为它底层只是对所有HashMap方法进行了重写(Synchronized修饰),并没有做很多优h化。
4. ConcurrentHashMap怎么做到线程安全的?
接下来,我们要解决的就是这个问题。
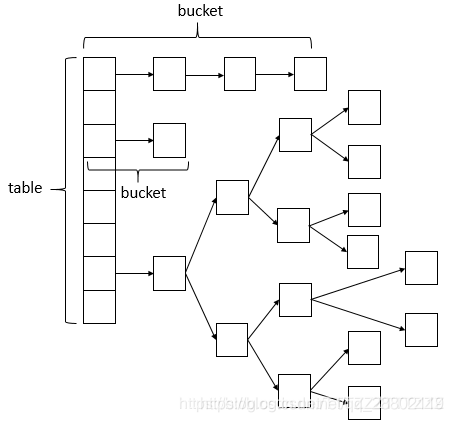
首先熟悉下ConcurrentHashMap的数据结构(数组+链表+红黑树),桶中的结构可能是链表,也可能是红黑树,红黑树是为了提高查找效率,如下图:
接下来,我们来看看ConcurrentHashMap的构造方法:
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}重点关注第五个构造方法,它有三个参数:initialCapacity是初始容量,loadFactor是加载因子,concurrencyLevel是并发级别,默认值为16。
接下来,我们看看put()方法分别是怎么实现的:
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
//不允许 key或value为null
if (key == null || value == null) throw new NullPointerException();
//计算hash值
int hash = spread(key.hashCode());
int binCount = 0;
//死循环 何时插入成功 何时跳出
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果table为空的话,初始化table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//根据hash值计算出在table里面的位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//如果这个位置没有值 ,直接放进去,不需要加锁
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//当遇到表连接点时,需要进行整合表的操作
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//结点上锁 这里的结点可以理解为hash值相同组成的链表的头结点
synchronized (f) {
if (tabAt(tab, i) == f) {
//fh〉0 说明这个节点是一个链表的节点 不是树的节点
if (fh >= 0) {
binCount = 1;
//在这里遍历链表所有的结点
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果hash值和key值相同 则修改对应结点的value值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//如果遍历到了最后一个结点,那么就证明新的节点需要插入 就把它插入在链表尾部
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//如果这个节点是树节点,就按照树的方式插入值
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//如果链表长度已经达到临界值8 就需要把链表转换为树结构
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//将当前ConcurrentHashMap的元素数量+1
addCount(1L, binCount);
return null;
}
比较明显的就是,ConcurrentHashMap不接受空值了,key和value都不允许为空。而且,ConcurrentHashMap对数据存储做了优化,进行了数据分片加锁处理。上面的代码中,虽然也用到了Synchronized关键字,但是但是对某一个数据节点加锁,并不会影响其他数据节点。
我们再来看看get()方法:
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}因为get()方法不会对数据本身产生影响,所以并没有加锁的操作。
其实最需要注意的其实是size()方法:
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}size()方法并没有加锁操作,而是通过sumCount()方法把所有的数据片段的数据数量计算出来。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









