




 本文深入探讨了ResNet和DenseNet两种深度学习网络结构,详细解释了它们如何解决梯度消失问题,强化特征传播,并大幅度减少参数数量。ResNet通过引入Shortcut结构允许网络深度无限增加,保持性能稳定;DenseNet则通过每层与之前所有层的连接,最大化信息流动。
本文深入探讨了ResNet和DenseNet两种深度学习网络结构,详细解释了它们如何解决梯度消失问题,强化特征传播,并大幅度减少参数数量。ResNet通过引入Shortcut结构允许网络深度无限增加,保持性能稳定;DenseNet则通过每层与之前所有层的连接,最大化信息流动。
ResNet是15年被提出,在ImageNet比赛的分类任务中获得第一名。检测、分割、识别任务中都有用到。
https://blog.youkuaiyun.com/lanran2/article/details/79057994
意义:
随着网络加深,训练集准确率会发生下降,但不是由于过拟合造成的。故提出深度残差网络,允许网络尽可能加深。
Shortcut结构:
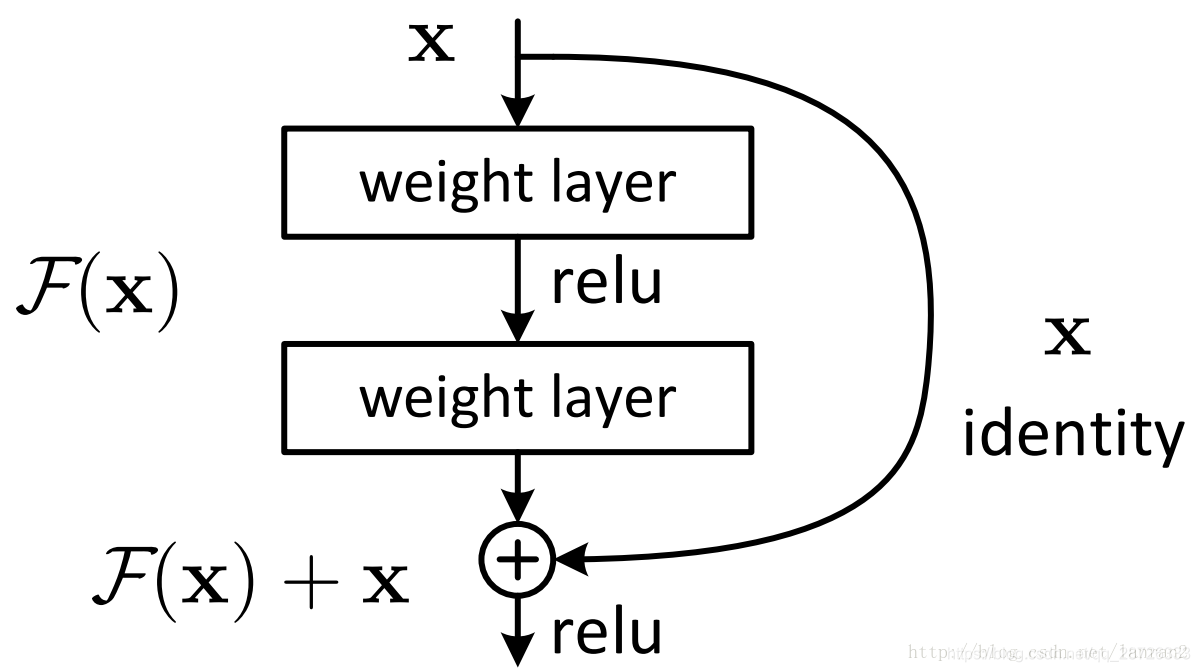
残差网络提出了两种mapping:一种是identity mapping,指的就是图中”弯弯的曲线”,另一种residual mapping,指的就是除了”弯弯的曲线“那部分,所以最后的输出是 。如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
ReaNet结构:
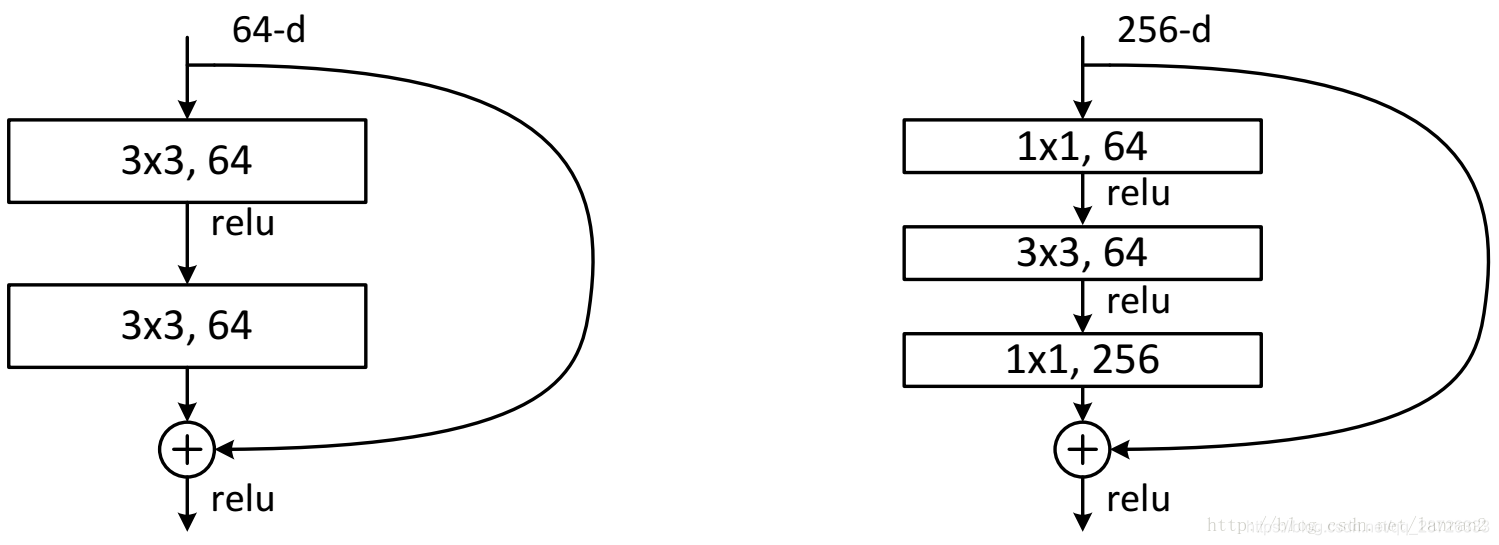
这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个”building block“。其中右图又称为”bottleneck design”,目的一目了然,就是为了降低参数的数目,第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
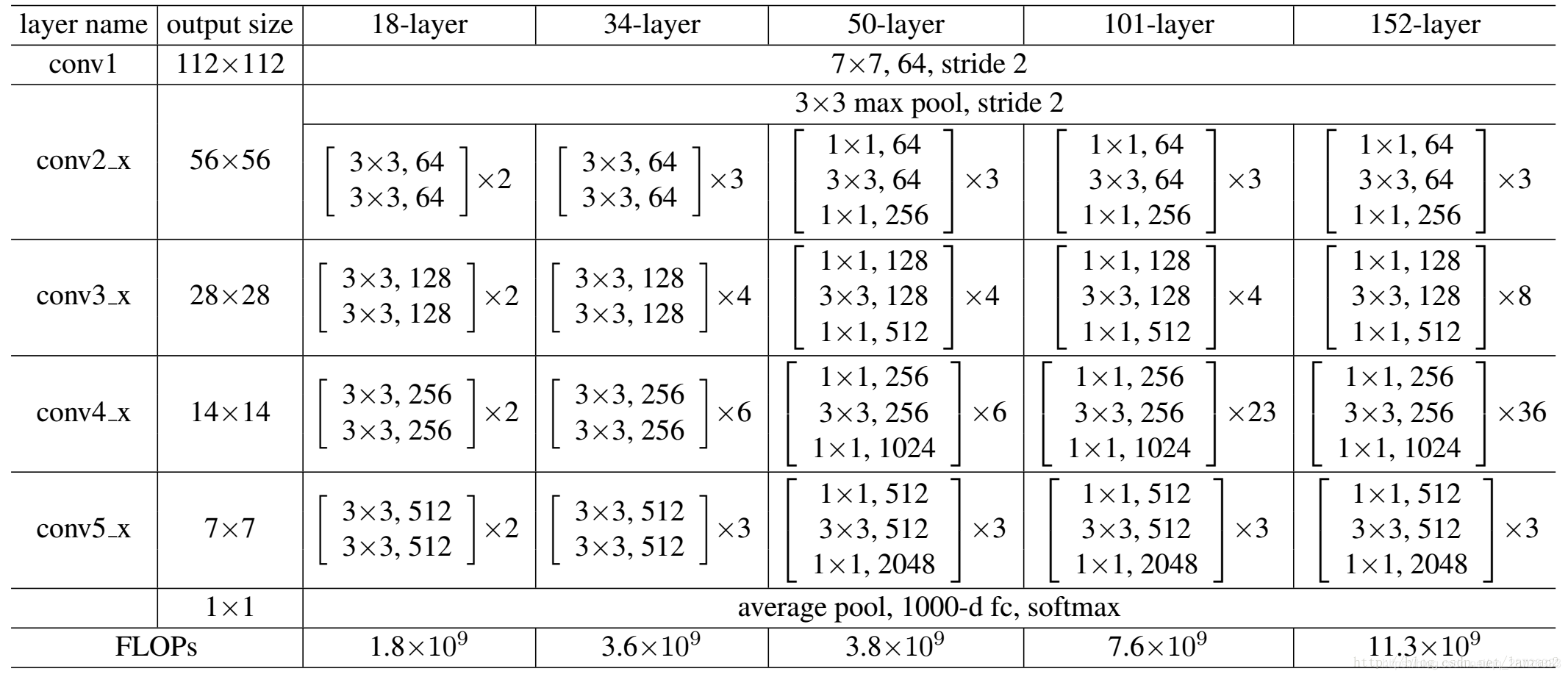
具体结构:
DenseNet:
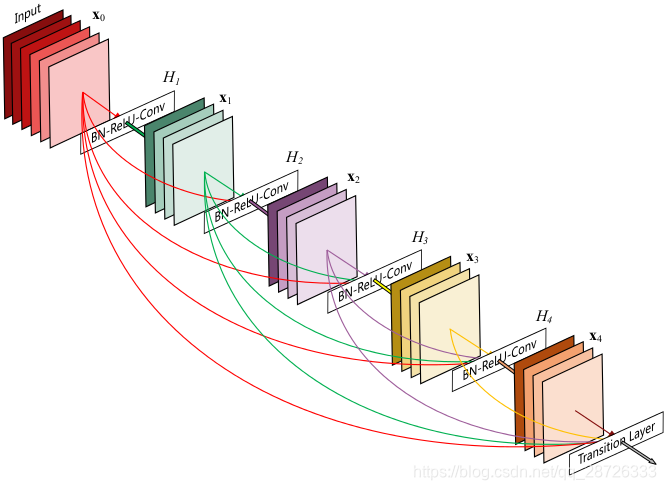
稠密连接:每层以之前层的输出为输入,对于有L层的传统网络,一共有LL个连接,对于DenseNet,则有
通过加深网络结构,提升分类结果。加深网络结构首先需要解决的是梯度消失问题,解决方案是:尽量缩短前层和后层之间的连接 。H4层可以直接用到原始输入信息X0,同时还用到了之前层对X0处理后的信息,这样能够最大化信息的流动。反向传播过程中,X0的梯度信息包含了损失函数直接对X0的导数,有利于梯度传播。
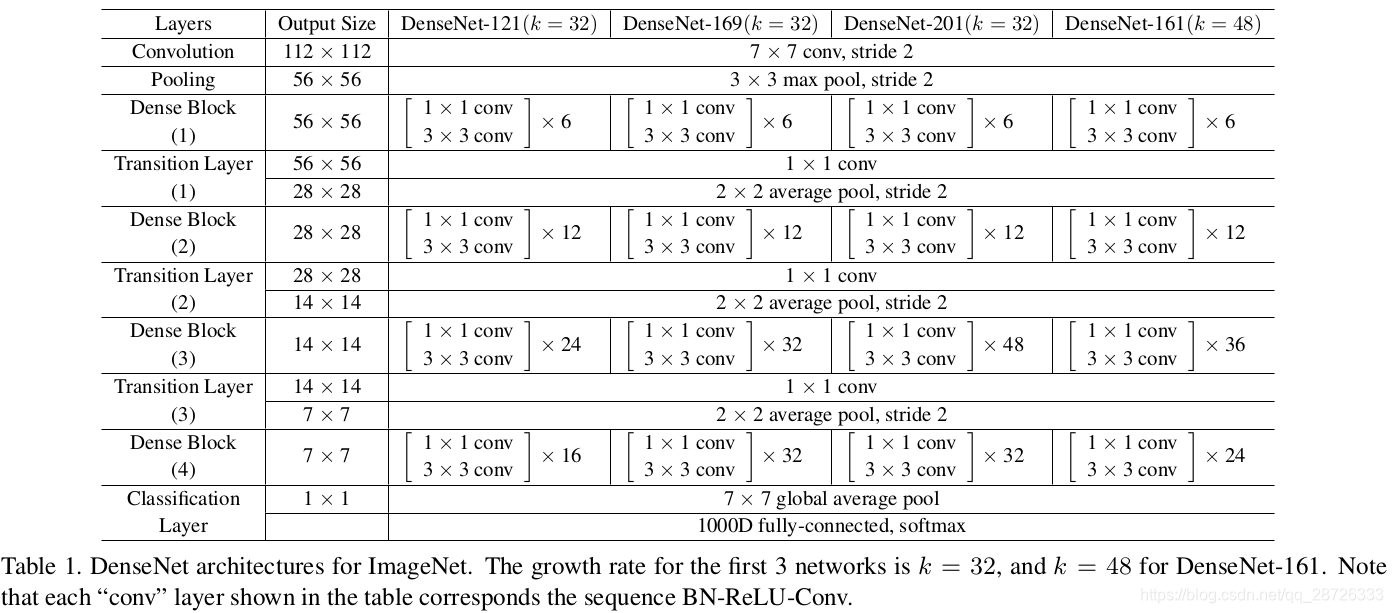
优点:
1.有效解决梯度消失问题
2.强化特征传播
3.支持特征重用
4.大幅度减少参数数量

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









